降维打击:群体智能半价打平Fable 5新智元
当Fable、Mythos因禁令下线,当OpenRouter Fusion、Fugu、Hermes MoA集体登场,行业共识已成:未来竞争力不在于单一模型有多强,而在于AI组织力。浪潮信息元脑企智EPAI的多模融合API,正带着这份群体智能的降维打击,走向更广阔的企业战场。
今年6月12日,全球最强的Fable 5与Mythos 5,因一纸禁令对所有人下线。
6月13日,OpenRouter放出Fusion,自称「市场上最智能的复合模型」,半价对标Fable。
6月22日,Sakana AI放出Fugu,官方说法是Ultra版比肩Fable 5与Mythos Preview。
紧接着,Hermes官方也上线了Mixture of Agents功能(MoA)。
在智能体基准测试HermesBench上,基于Opus 4.8 + GPT 5.5的MoA得分比 Opus 高出 8%,比GPT高出11%。
他们补位的方式出奇地一致:不是再造一个更大的单一模型,而是把一群现成的模型组织起来,用「群体智能」击败更大参数的单体模型。
Sakana说得最直白:「超越更大模型:编排模型是下一个前沿领域」。
但这件事上,还漏了一家。
在OpenRouter推出Fusion API之前,国内已有企业有类似的想法,最近也推出了相关服务。
不过,他们为什么不卷单模参数,却不约而同选择了这一条路?
AI的下一站
真正的问题是什么?
要理解多模融合的价值,得先承认一件事:「选出最强模型」是个伪命题。
因为真实业务里的复杂任务,都不是单点能力的博弈。
举个例子,一份「竞品技术方案分析」,里面同时藏着
▪︎事实检索:对方用了什么技术;
▪︎逻辑推理:这套架构的瓶颈在哪;
▪︎专业判断:值不值得跟进;
▪︎内容表达:写成一份能给老板看的报告。
这四种能力,几乎不可能由同一个模型在每一个环节都保持最佳状态。
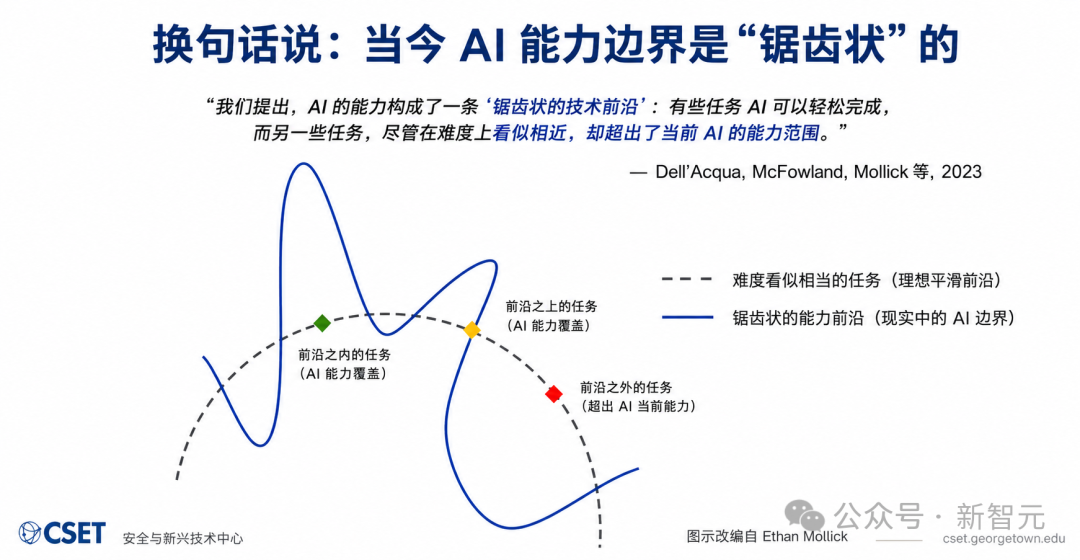
AI的能力边界并不是一条平滑的曲线,而是一道布满深渊的断崖。
这一残酷真相叫做:「锯齿状前沿」(Jagged Frontier)。
OpenAI奥特曼曾低估了AI会有多参差不齐,直言:「在有些事上AI做得极其出色,但在那种长期的复杂任务监督方面却完全不行。」
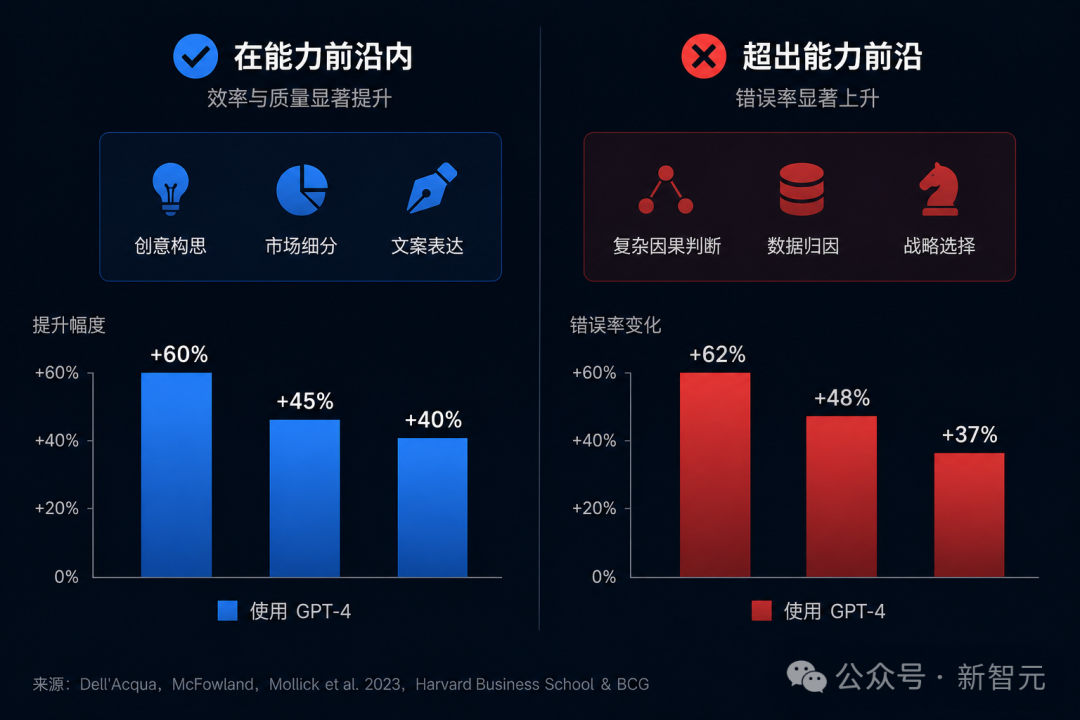
在哈佛商学院与BCG的一项实地实验中,研究者发现:一旦任务跨出模型能力前沿,使用AI的人类顾问反而更容易给出错误答案。
最危险的地方在于:AI会把错误包装得更像正确答案。
也就是说,单一AI不是「越难越强、越简单越稳」。
这似乎也是通往真正AGI(通用人工智能)智能的最后几个前沿问题之一。
更糟糕的是,企业级应用依赖单一API,本质上是在刀尖上行走。
如果企业陷入「测试—调整—再测试」的单模型选型死循环,那其实用农业「挑种子」思维,应对数字时代的「工业化协作」。
所以行业的重心,正在悄然变化:从「接入更多模型」,转向「如何根据任务,组织和使用多个模型」。
AI的下一战开始了。
元脑企智EPAI的降维打击
浪潮信息元脑企智EPAI的逻辑非常犀利:企业级AI的下半场,比的是谁能让不同模型的长处,在同一个任务里自动「补位」。
最近,元脑企智EPAI上线了多模融合API。
目前,该多模融合API已在积算科技Token服务平台正式上线,并面向开发者和企业用户开放内测申请。
试用申请链接:https://www.icompify.com/api_request/index.html
他们坚信:群体智能超越单模上限。
很多人认为多模融合就是简单的「1+1」,但元脑企智EPAI告诉我们,这是一场关于「AI组织力」的革命。
它的多模融合API,本质上是给企业配了一个「AI首席执行官」 。
它的玩法分为三步:
▪︎众模并行(候选生成): 把同一个任务丢给一池子模型,让它们各显神通。
▪︎智能评审(评审分析): 请一个高阶模型坐在首席,识别不同答案里的共识、分歧和遗漏。
▪︎深度融合(最终输出): 挑出最优解,拼出一张最完整的拼图。
关键在于,这一整套流程,开发者只需要一次API调用。
不用自己搭多模型调度系统,不用手写评审逻辑,不用做结果整合。
在OpenClaw、Hermes、OpenCode这些主流智能体框架里,把多模融合API当成一个普通的模型服务配置进去就行,原有的对话、推理、工具调用能力照常用,应用一行都不用重构。
效果有多硬核?
在内部实测中,元脑企智EPAI的多模融合API在DRACO(深度研究)基准测试中拿到了53.9%的成绩,远超单一模型。