从LLM到JEPA:中国人把“世界模型”搬进细胞量子位
最近,AI虚拟细胞(AIVC)赛道,迎来关键突破!
作为全球最早布局该领域的企业之一,百曜科技正式发布全球首个基于LLM-JEPA架构的AI虚拟细胞世界模型——AURA CellOS。
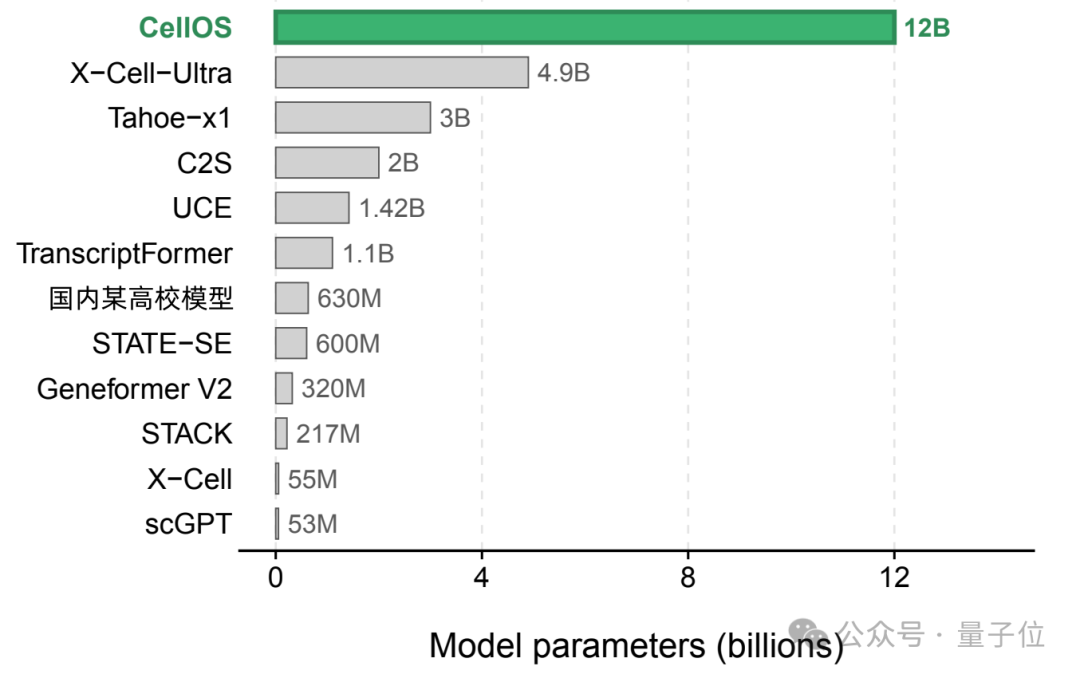
该模型是目前公开报道中参数规模最大的单细胞基础模型,基于3.905亿个人类单细胞转录组训练,覆盖了几乎所有重要的人类细胞:40余种人体组织、260余种细胞类型。
其最受关注的突破在于,它首次将JEPA(联合嵌入预测架构)与世界模型理念系统性引入单细胞研究。
当前,世界模型已经是自动驾驶、机器人和生成式AI的重要技术方向。
CellOS的出现让外界好奇,在高度复杂的生命科学领域,世界模型能否真正落地,并产生实质价值?
从目前公开的评测结果看,CellOS在预测精度、扰动建模等多个核心指标上与多款主流模型拉开倍数差距,达到当前国际领先(SOTA)水平。
但想要看清它的技术逻辑与商业价值,一切还要从一颗细胞说起。
AIVC走到十字路口
理解细胞变化,是生命科学最核心的问题之一。
疾病发生、药物作用、细胞治疗,本质上都是细胞状态发生变化的过程。
过去,科学家只能通过细胞培养、动物实验乃至人体验证来探究细胞在药物、基因扰动等刺激下的变化。
高昂的研发成本和漫长的试验周期,让大量潜在新药和细胞疗法陷入漫长试错,“十年研发周期、十亿美元投入,临床成功率却不足10%”的“双十定律”亟待被终结。
△图片由AI生成
“虚拟细胞”的出现,为新药发现开辟了全新的路径。
在计算机里“复刻”细胞的想法,早在20世纪90年代就有学者探索,并开发了最早的细胞建模软件之一VCell。之后斯坦福大学研究团队发布了全球首个全细胞计算模型。
但此前的虚拟细胞,不是一个学习型的模拟器,不能模拟细胞在不同条件和变化环境下的运作。
无法预测细胞功能、行为和动力学,无法揭示其背后的机制,也就无法在药物开发应用中发挥最大价值。
直到近些年AI技术的突飞猛进,叠加组学技术的迅猛发展,才让虚拟细胞更接近生命科学的“模拟沙盘”:
▪︎单细胞测序技术的指数级进步及成本降低,显著提升了数据采集能力,过去几年中,这些数据每6个月翻一番,为建模提供了底层基础;
▪︎AI技术的进步则显著增强了细胞数据的处理、学习和推理的能力。
2024年12月,美国斯坦福大学、基因泰克制药公司与陈—扎克伯格基金会组成的联合科研团队在顶级期刊《Cell》发表的重磅论文,点燃了全球的研发热潮:
AI虚拟细胞(AIVC)的时代,正式宣告到来。
△图片由AI生成
其实在此之前,Geneformer、scGPT、scFoundation、GeneCompass等一批模型就已相继问世,只是业内还没有统一AIVC的叫法。
这些AIVC模型解决了细胞类型识别等基础需求,但在预测细胞动态变化上存在明显局限。
例如,在敲除基因、给药或诱导分化后,细胞会如何演化?第一代AIVC模型在这类动态预测任务上仍存在明显局限。
核心在于,它们的训练目标主要是学习基因表达模式本身,而非细胞状态变化的内在机制,因此难以区分哪些表达变化只是背景噪声,哪些才是真正驱动细胞状态演化的关键信号。
进一步地,由于模型主要基于单一表达视角学习静态基因表达模式,难以刻画基因调控关系及细胞状态演化的动态规律。
许多只有在特定扰动条件下才显现的关键生物学信号,也容易被大量稳定表达的背景信号所淹没。
因此,仅靠不断扩大数据规模和模型参数,并不能显著提升模型对细胞状态演化轨迹的预测能力,也难以学习细胞变化背后的内在生物学规律。
2026年6月,《Nature Methods》刊发的一项研究非常扎心:
研究人员基于2220万个细胞的scTab语料库,预训练了400个模型,完成6400次评估。结果显示,在多项任务中,模型性能往往在使用约1%的预训练数据后便进入平台期。
换句话说,仅用约22万细胞训练模型性能就基本拉满,再多喂海量同质细胞样本,模型效果也不会明显提升。
这让行业开始重新思考:现有技术路线是否还能持续受益于Scaling Law(缩放规律)?
或者说,问题究竟出在数据规模不足,还是第一代AIVC的建模范式已经触及瓶颈?
CellOS给出的答案是后者:
真正限制模型持续提升的,并非Scaling Law本身,而是传统语言模型架构与细胞数据特性的系统性错配。
只有让模型真正学习细胞状态演化规律,而不仅仅是静态表达模式,数据规模扩展才能持续转化为模型能力的提升。
从“看懂”到“理解”细胞,CellOS的“三板斧”
世界不是由文字构成的。
李飞飞最新长文如是说。
而细胞世界,更不由文字定义。
说到底,AIVC领域需要的是AI对细胞状态有理解,而非单纯的表达模式复现。
只有这样的模型,才能支撑动态预测(如扰动响应)和可迁移的虚拟细胞能力。
站在业内角度看,CellOS这次的打法其实挺狠的。
它没有选择大多数团队还在走的“安全路线”——继续在大语言模型上卷参数、卷数据,而是直接站队JEPA这条更难、但潜在天花板更高的路。
因为人工智能领域的普遍共识是:「世界模型」最擅长感知规律、推演环境动态变化。
在自动驾驶、机器人领域,世界模型已经被用来预测环境变化。
现在,细胞领域也要一试。而CellOS是第一个“吃螃蟹”的。
CellOS是率先将世界模型理念引入AI虚拟细胞领域的模型。
同时,它也是目前公开信息中规模最大的单细胞Foundation Model,是基于3.905亿个人类单细胞转录组数据训练的12B参数模型。
什么概念?这几乎覆盖所有已知人类细胞类型。
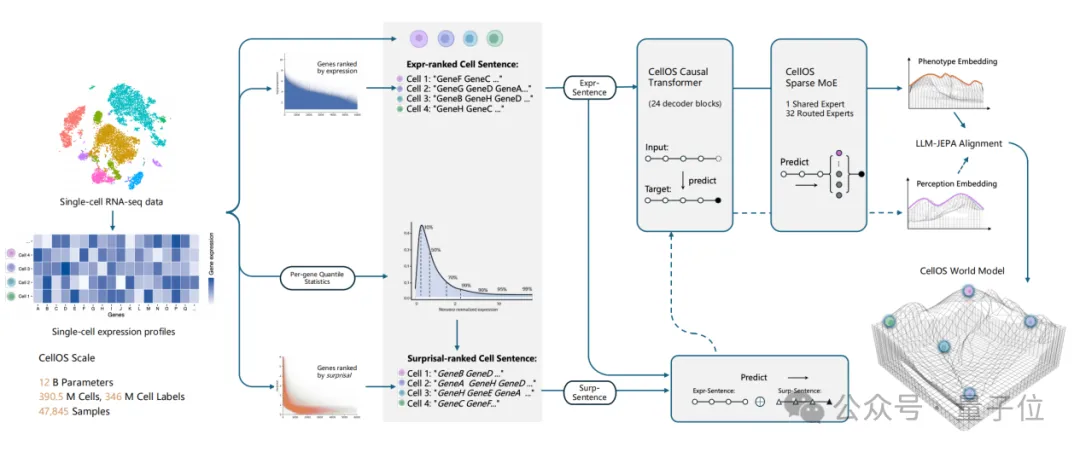
CellOS核心创新有三点:多视角表征学习、JEPA联合嵌入预测、无损扩容。咱们一个个看。
创新一:多视角表征学习
它让模型在进入更复杂的训练阶段前,就先获得更丰富、更敏锐的细胞特征辨别能力。
传统单细胞基础模型通常只依赖单一的“表达视角”,即根据基因在单个细胞中的表达丰度来判断细胞状态。
这种方式容易忽略那些表达量不高、但在生物学上具有重要标志意义的基因(如调控基因、应激响应基因),导致关键信号易被背景噪声淹没。
于是,CellOS引入「双视角互补机制」,在表达视角之外,增加群体感知视角。相当于给模型装了两双「眼睛」: