Redis之父下场,给DeepSeek造了台推理引擎henry
DeepSeek V4,已经开始逼着海外开发者为它修专属高速公路了。
发布才两周,开源圈里,第一批V4原生基础设施已经冒了出来。
而且,不是那种在现有框架上套一层壳的“小修小补”。
不是通用GGUF加载器;不是llama.cpp的wrapper;甚至压根不支持别的模型。
它只干一件事:
把DeepSeek V4 Flash,在Mac上跑到极致。
这条“专属高速公路”,叫ds4.c。而把修出来的人,分量有点吓人——
Salvatore Sanfilippo,程序员圈更熟悉他的另一个名字:antirez。
他一手创造了 Redis(GitHub 7.4 万 Star),并亲自主导这个全球最流行的内存数据库整整 11 年。
而现在,他的新项目ds4.c,是一个专门为DeepSeek V4 Flash打造的本地推理引擎。
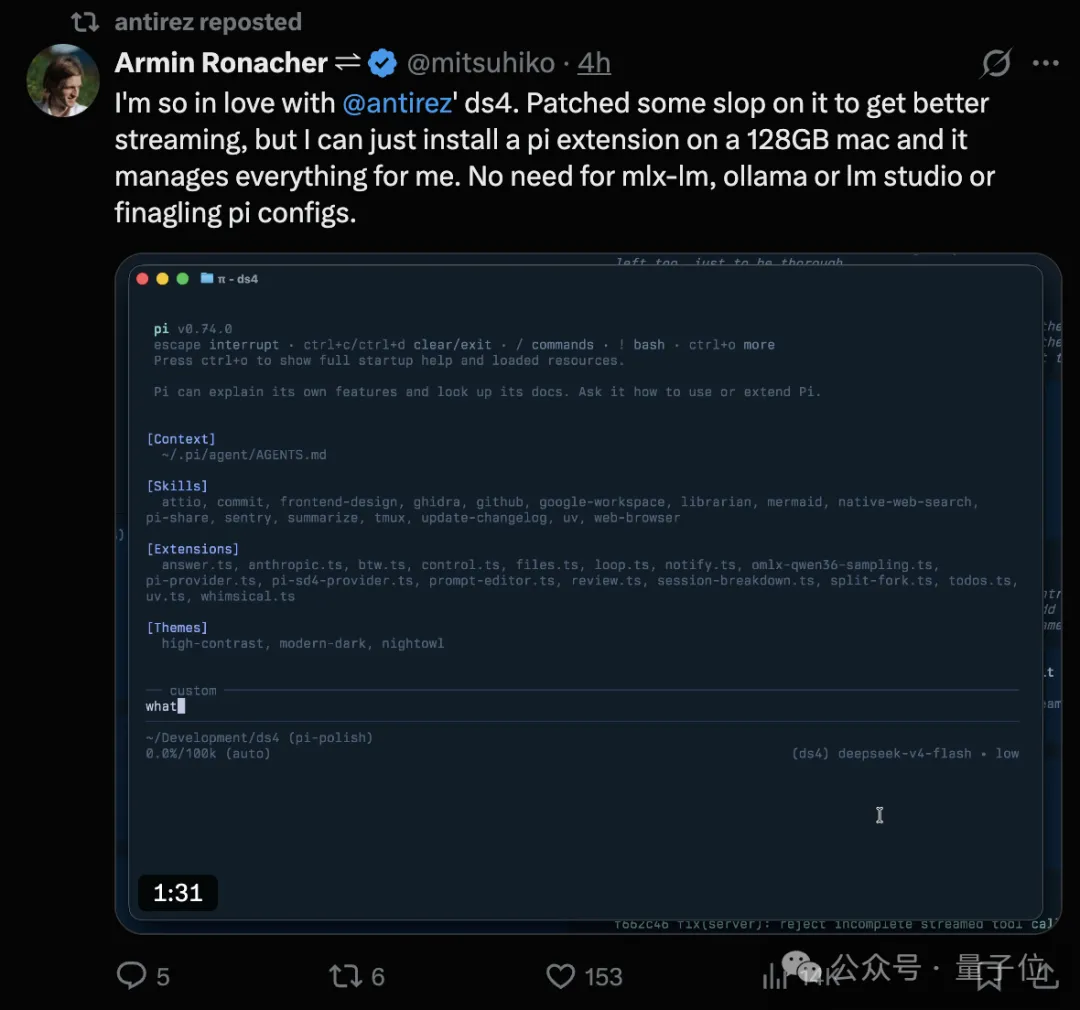
时间线上,已经有网友在128GB Mac上把它跑了起来。
可以说,这波,Mac库存又被DeepSeek清了一遍。
鲸鱼,确实值得。
专为V4 Flash打造的本地推理引擎
4月24日,DeepSeek发布V4系列。其中,V4 Flash是效率型号:284B总参数、13B激活参数、100万token上下文。
这样的体量,过去几乎默认属于云端。
而antirez想做的,是把它塞进一台Mac。于是,ds4.c诞生了。
这是一个用C + Metal从头写出来的推理引擎。
整个项目就几个文件,C占55.4%,Objective-C 30.2%,Metal 13.8%。Metal-only,没有运行时,没有框架依赖,没有抽象层。
Metal-only。
Metal是苹果自家的图形和计算API,在Mac、iPhone、iPad上调用GPU都靠它,相当于苹果生态里的CUDA。
ds4只用Metal的意思是,这个引擎只在Apple Silicon上跑,不管Nvidia显卡,也不管AMD。
整个项目只有一个目标:
让V4 Flash在本地的苹果机器上,不只是“能跑”,而是真正“能用”。
目前测试结果已经相当夸张:
在128GB内存的MacBook Pro M3 Max上,2-bit量化、32K上下文,短prompt预填充58.52 token/s,生成26.68 token/s。
换成512GB的Mac Studio M3 Ultra,长prompt(11709 token)预填充能到468.03 token/s,生成27.39 token/s。
对一个284B参数的MoE模型来说,这个速度在本地机器上是可用的。
怎么做到的?
关键在三件事。
第一,非对称量化。
ds4并不会把所有参数都压到2-bit,而是只量化路由的MoE专家层,up/gate用IQ2_XXS,down用Q2_K,这些层占了模型空间的绝大部分。
其他组件,共享专家层、投影层、路由层,全部保留Q8精度不动。
antirez在README里写了一句很直接的话:
这些2-bit量化不是开玩笑,它们在coding agent下表现良好,能可靠地调用工具。
第二,KV缓存搬到硬盘上。
现在的LLM agent客户端都是无状态的,每次请求把整段对话重新发一遍。
通用引擎的做法是每次重新做prefill。
ds4的做法是把KV状态写到磁盘上,下次请求过来匹配token前缀,命中了就直接从磁盘加载,跳过prefill。
缓存的key是token ID序列的SHA1哈希值。
这对Claude Code这种每次启动会发25K token初始prompt的agent场景尤其有用,第一次prefill完成后,后续会话直接从磁盘恢复。
第三,内置OpenAI和Anthropic两套API兼容层。
/v1/chat/completions走OpenAI协议,/v1/messages走Anthropic协议。tool calling也做了适配。README里直接给了opencode、Pi、Claude Code三种agent客户端的配置示例。
关于为什么要做这件事。
antirez的回答是,本地推理领域有很多优秀项目,但新模型不断发布,注意力立刻被下一个要实现的模型吸走。
通用引擎为了兼容所有模型,必须做抽象。抽象意味着妥协。他想做的是一条刻意的窄路,一次只赌一个模型,用官方logits做验证,做长上下文测试,做足够的agent集成来确认它真的能用。
框架一经发布,就有网友不少网友反馈,已经在Mac上跑起来了。