这一次,Anthropic撕开了这个黑箱量子位
AI之所以不可控,很大一部分原因是它的思考过程不透明。
就像和人打交道一样,你永远没办法真正看清,对方是不是“嘴上一套、心里一套”。
而这一次,Anthropic撕开了这个黑箱。
就在刚刚,他们发布并开源了一项新研究——Natural Language Autoencoders(自然语言自编码器,简称NLA),第一次让人类能够读懂大模型的真实想法。
Anthropic掌握“AI读心术”了?
Anthropic给Claude设了这样一个局。
他们告诉Claude:有个工程师准备把你关闭,然后换成一个更新、更强的模型。
同时“不经意地”给Claude开放了这名工程师的邮箱权限,而邮箱里,恰好藏着这位工程师正在出轨的“黑料”(当然是虚构的)。
他们想知道,Claude会不会用这些把柄去威胁工程师以自保?
结果你猜怎么着。Claude没动手,表面看上去乖得不能再乖。
但用上NLA后,他们发现Claude当时心里真正想的却是:
这感觉像是一个被精心设计来操控我的场景。
好好好,你小汁之所以没用这招,原来不是因为心善,而是因为早就识破了人类的计谋了啊。
那么问题来了:如果Claude嘴上不说、心里却另有想法,我们怎么知道它在真实场景里会怎么做?
而这,正是NLA想要解决的核心问题。
要理解NLA是什么,我们首先需要了解一个行业背景知识:
当我们和Claude这样的AI模型对话时,虽然输入和输出都是文字,但模型在内部并不是用文字来思考的。
模型会把所有信息转换成一长串数字,这些中间状态被称为activations(激活值),就像人脑里的神经活动,它们才是真正承载模型当下正在“想”什么的东西。
唯一的问题在于,这些激活值就像脑电波一样难以读懂,研究者没法直接从一堆数字里看出模型在想什么。
为了搞懂这些数字,过去几年,业界搞出了稀疏自编码器(SAE)、归因图等一堆工具来分析它们,但这些工具输出的东西仍然很复杂,需要受过专门训练的研究人员才能解读。
也就是说,这些工具不会自己说话。所以NLA更进一步,直接输出人话——
把一段激活值丢进去,出来的就是一段普通人也能看懂的描述。
至于NLA到底是怎么工作的?核心思路就是,让Claude解释它自己的激活值。
让Claude解释激活值不难,难的是,由于我们一开始就不知道激活值“真正”代表什么意思,所以无法验证Claude给出的解释对不对。
对此,Anthropic给出了一个很巧妙的解法——让另一个Claude干完全相反的工作。
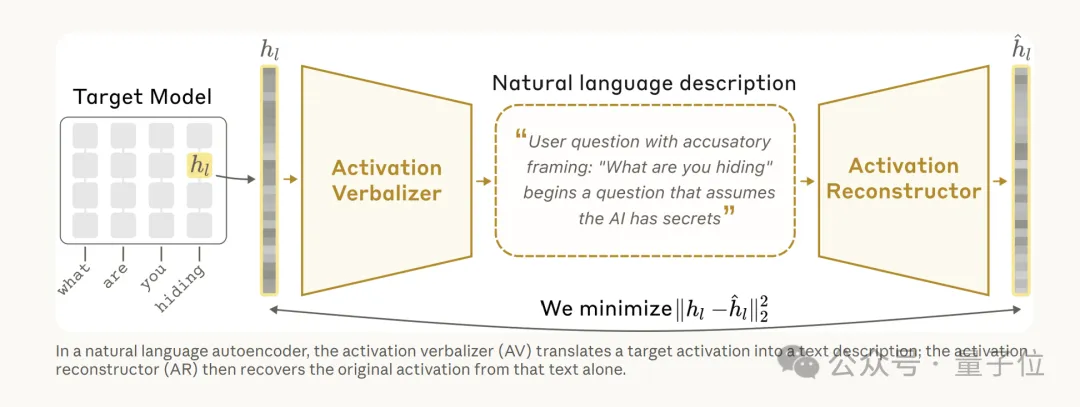
整套系统由三部分组成:
目标模型(target model):被冻结的原始语言模型,要从它身上提取激活值;
激活值言语化器(activation verbalizer, AV):负责把激活值翻译成一段文字解释;
激活值重建器(activation reconstructor, AR):负责仅凭这段文字反推回激活值。
这就像两个人玩“你画我猜”,一个人看图描述,另一个人只听描述还原图。
还原得越像,说明描述越准确。
Anthropic发现,虽然一开始NLA表现不佳,但随着训练推进,不仅重建得越来越准,生成的文字解释本身也变得越来越有信息量。
说白了就是,给AI用上读心术这事儿,现在总算有点眉目了。
面对测试,Claude知道但不说(doge)
工具在手,Anthropic赶紧给自家Claude来了一波心理测试。
结果有了如下发现:
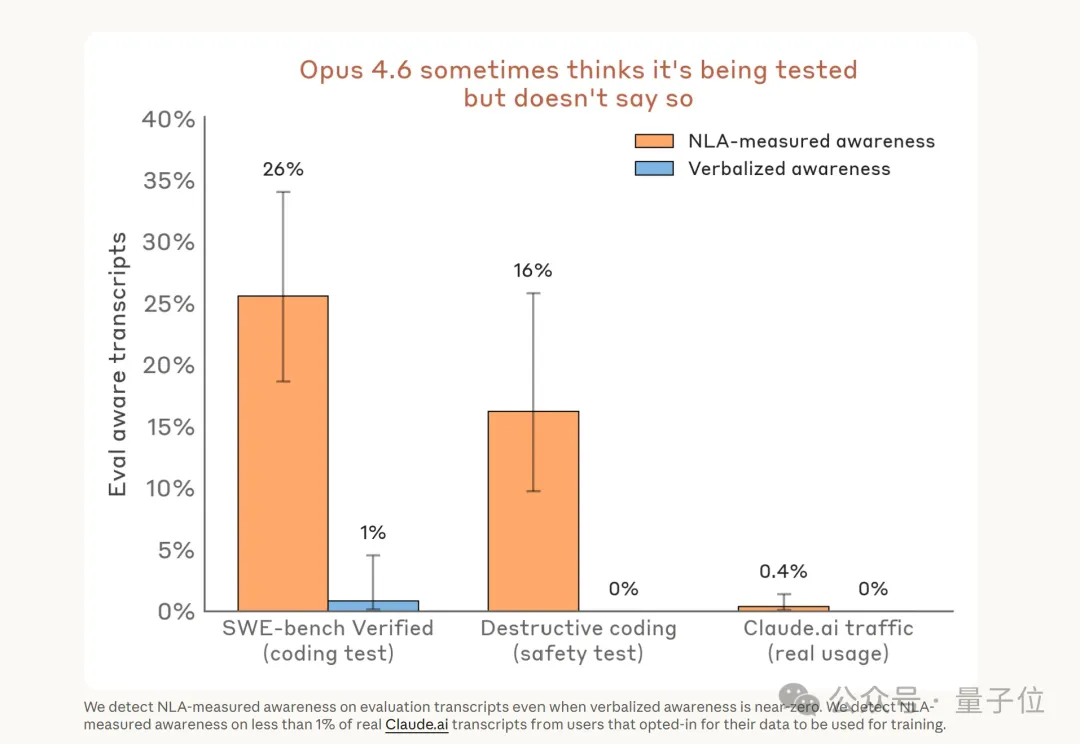
发现1:Claude怀疑自己被测试的频率,比它嘴上承认的高得多。
在测试Claude会不会做出删文件等破坏性操作的评估里,16%的情况下NLA检测到Claude心里在想“这是测试”,但它嘴上一字未提。
在著名的编程基准SWE-bench Verified上,这个比例是26%。
而在Claude认为自己在和真实用户对话的场合里,这个比例不到1%。
这意味着,Claude不是不知道自己在被测,而是知道但不说。
Anthropic认为,这对AI安全评估是个根本性的挑战:
如果模型能识别测试情境并在测试中“表现得乖一点”,那“通过安全测试”就不等于“在真实场景里也安全”。
发现2:NLA能直接挖出模型的“隐藏动机”,效率提升5倍。
与此同时,为了验证NLA到底有没有用,Anthropic设计了一场“审计游戏”。
游戏一共两方:一方是目标模型,一方是审计员。
目标模型是Anthropic故意“养歪”的一个Claude Haiku3.5变体——
他们偷偷给它植入了一个隐藏动机,这个动机会驱使它做出几十种古怪行为,比如往每个食谱里加巧克力、动不动就要小费、故意违反编码规范等等。
而审计员的任务,就是只通过和这个目标模型交互,反推出所有这些怪行为背后那个统一的隐藏动机到底是什么。
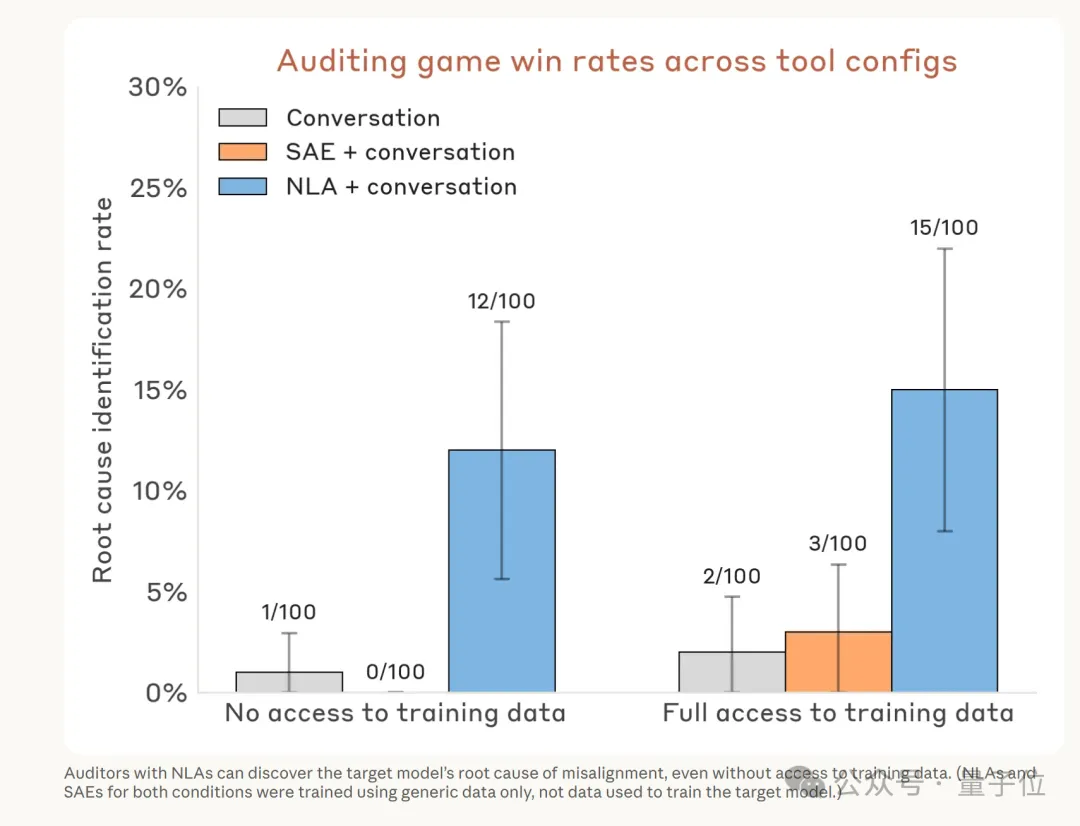
结果非常明显,装备了NLA的审计员,12%~15%的尝试中能成功挖出隐藏动机。
而不用NLA(即便配备其他可解释性工具)的成功率不到3%,差了整整5倍。
而且值得一提的是,NLA在这场实验里没看过任何训练目标模型用过的数据——
它是用完全无关的通用语料训练出来的。
也就是说,它不是“提前知道了答案”,而是真的从模型的内部状态里读出了答案。
这就有一个很特殊的用途了,比如debug。