弹性大规模分布式预训练终于可行了机器之心
弹性 AI 预训练已经推进到了下一个前沿!没有意外:来自谷歌。
据介绍,他们提出的 Decoupled DiLoCo 是一种革命性的分布式训练技术,能够利用全球各地的异构硬件进行训练,并且即使当硬件发生故障时,系统也不会停止运行!
这项重磅研究成果引发了广泛关注,论文 Leads 作者之一的 Arthur Douillard 在 X 上的分享推文获得了超 260 万次浏览!
值得注意的是,著名研究者、Google DeepMind 和 Google Research 首席科学家 Jeff Dean 也是作者之一。他也发布了多条推文介绍这项成果。
推文中,他还回忆了自己 14 年前的一篇一作论文《Large Scale Distributed Deep Networks》。在这篇 NeurIPS 2012 论文中,他们就已经证明大规模训练和异步技术可以用于训练非常庞大的神经网络,并以容错的方式将训练任务分散到数千台机器上。
而现在,Decoupled DiLoCo 有望将这个理念真正变成切实可行的大规模工程实践。
论文标题:Decoupled DiLoCo for Resilient Distributed Pre-training
论文地址:https://arxiv.org/pdf/2604.21428v1
背景:规模越大,故障越频繁
要理解这项工作的意义,先要理解现代 AI 训练的一个根本困境。
今天训练大语言模型,普遍采用一种叫做 SPMD(单程序多数据)的并行方式。简单来说,就像一个工厂里所有工人必须同步操作一条流水线 —— 每个人都在做自己那一步,但所有人必须同时完成,才能推进到下一步。任何一个工位出了问题,整条流水线就得停下来等。
这在小规模下没什么问题。但当集群规模扩展到数十万乃至数百万块芯片时,概率就开始作怪了。
论文里有一个直接的计算:假设每块芯片平均一年才会出一次故障,听起来已经很可靠了。但如果集群里有 240 万块芯片,整个集群的平均故障间隔就缩短到不足一分钟。在这个规模下,硬件故障可不能再被视为意外了,而是训练过程中的日常。
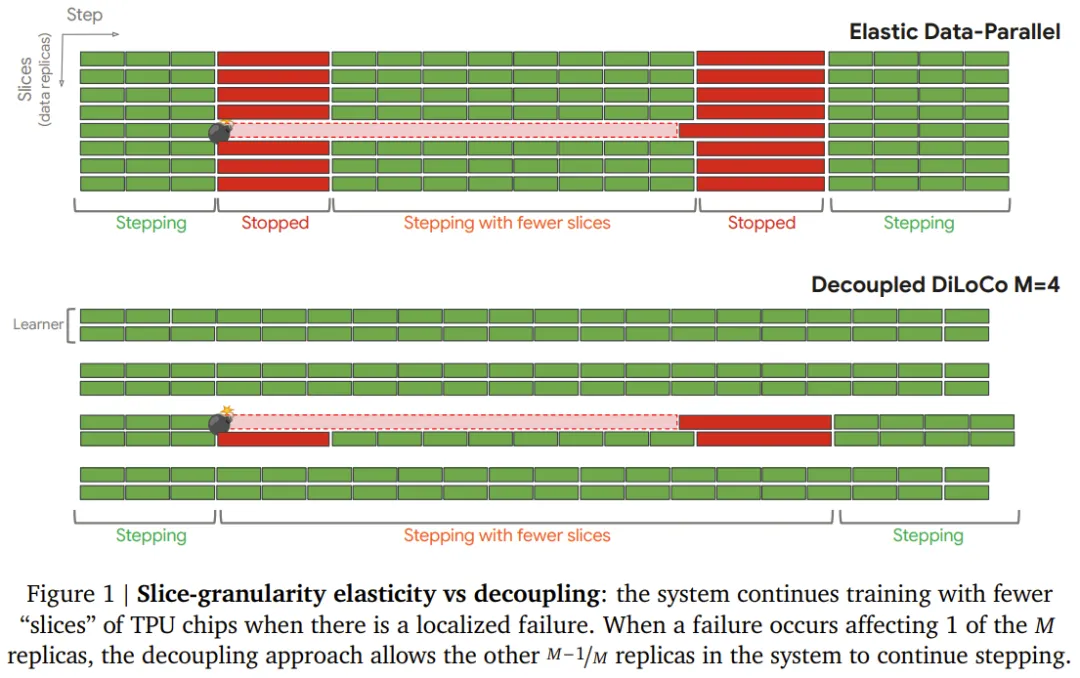
现有的应对方式,是所谓的「弹性训练」:检测到某台机器宕机后,重新调整集群配置,用剩余的健康机器继续跑。但这个重配置过程本身就要耗费大量时间,导致整个集群在等待期间无法做有效计算。
论文的模拟数据显示,在 240 万块芯片的规模下,即使有弹性机制,实际有效计算时间(即「Goodput」,有效吞吐率)也只有 40%—— 也就是说,有 60% 的时间,集群处于某种形式的等待或重配置状态,白白浪费算力。
打破「步调一致」的枷锁
Decoupled DiLoCo 的核心思路,是彻底放弃让所有机器保持同步这个前提。
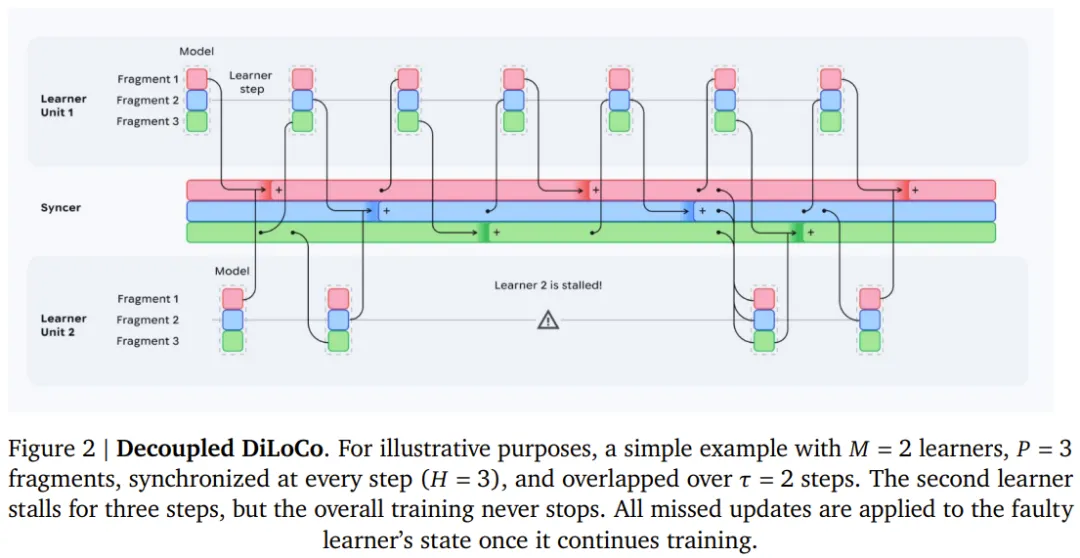
这套框架把整个训练集群拆分成若干个独立的「学习器」(Learner)。每个学习器各自用自己分到的数据独立训练,不需要等待其他学习器。当某个学习器出了故障,其余的学习器完全感知不到,继续自己的训练节奏。这就好比把一个大型联合考场拆成了若干个独立考场,一个考场里出了火情疏散,不影响其他考场里的学生继续答题。
那各个学习器之间怎么协同,让最终训练出的是同一个模型?
这里引入了一个轻量级的「同步器」(Syncer)。同步器运行在相对稳定的 CPU 资源上,负责周期性地收集各个学习器的参数更新,做一次合并,再把合并后的结果推送回去。
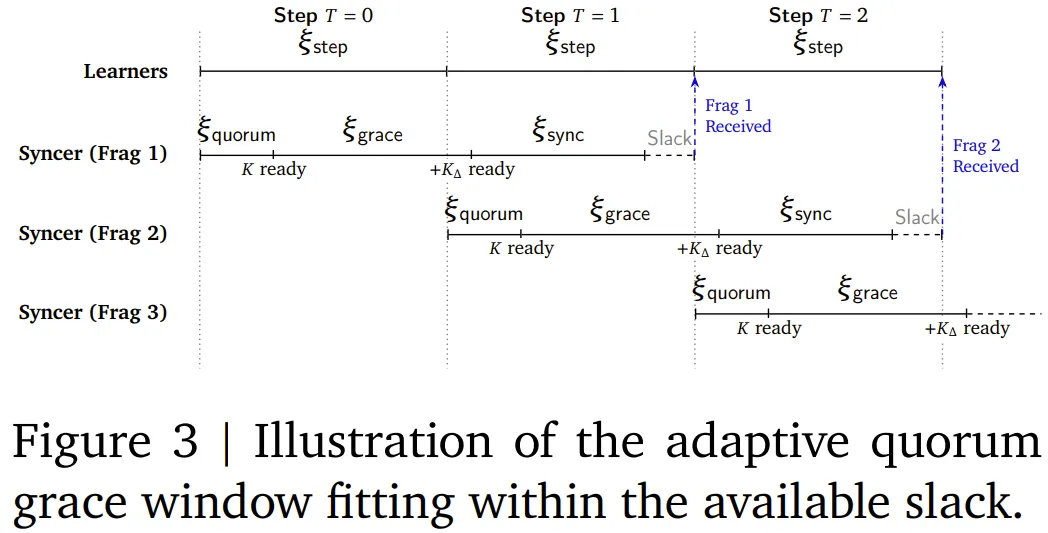
关键在于:同步器不需要等所有学习器都准备好才开始合并。只要有足够数量(论文称为「最小法定数」,即 Minimum Quorum)的学习器汇报了自己的进度,同步器就可以开始工作,出故障的那个学习器直接跳过,等它恢复后再补上。
此外,由于不同学习器的计算速度可能不同(尤其是混用了新旧两代芯片时),一个跑得快的学习器在同步间隔里处理的数据会比慢的多。为了避免快的学习器在合并时「一票顶多票」,同步器引入了基于处理 token 数量的动态权重机制,让合并结果更公平地反映每个学习器的实际贡献。
还有一个细节叫「自适应宽限窗口」(Adaptive Grace Window):同步器在达到最小法定数后,不会立刻合并,而是会多等一点点时间,争取让更多学习器赶上这一轮同步,从而提高每次合并的质量。这个等待时间被精心控制在不影响整体训练速度的范围之内。