李飞飞与杨立昆:同一个「世界」,不同的梦想零一瓦舍
李飞飞要的是「把世界做出来并让智能体进入其中」。
杨立昆要的是「把世界压缩成可规划的内部变量并让智能体据此行动」。
前者强调世界的外在可构造性,后者强调世界的内在可预测性。
一、同一个「世界」,不同的梦想
最近几年,很多大佬都在谈「世界模型」(World Model)这个概念,杨立昆和李飞飞可能是其中最有影响力的两个。
在很多人的印象里,他们的路线和主张是一样的。其实不然。
自然语言有模糊性,同一个词指向的含义可能非常多样化——就像不久前杨立昆和 DeepMind 的哈萨比斯在社交媒体上论战「通用人工智能」(AGI),吵了半天,实际上,两人对「通用」这个词的定义完全不一样,鸡同鸭讲。
「世界模型」这个词也具有一定的迷惑性。从宏观角度讲,在这个概念下,大家都关心的共同问题是:机器究竟怎样才能获得对世界的把握?
但如果去解决这个问题,哲学观、切入点以及路线图就像各村的地道,各有各的高招了。
李飞飞最关注的是 AI 如何获得对三维空间、几何关系、物理约束与交互环境的理解与生成能力。她后来创业的公司 World Labs 在官方表述里,把自己定义为一家「空间智能」(Spatial Intelligence)公司,我觉得这个词更能贴切地描述她的主张——强调模型要能够感知、生成、推理并与 3D 世界交互。
在李飞飞眼中,所谓的「世界」,首先是一个可进入、可编辑、可共享、可漫游的空间对象。强调的是世界的可构造性与可共享性:AI 要能把一个具有空间一致性、物理连贯性和编辑自由度的世界生成出来,让人和机器都能进入其中。
杨立昆那边则完全是另一种语义重心。在他的架构里,「世界模型」是内部系统的一部分,它的职责不是把世界显式地做出来给人看,而是补全未观测状态、预测未来状态、表达不确定性,与其他模块一起支撑「规划」。
更关键的是,他反复强调,预测应发生在「抽象表征空间」中,模型不必也不应该去重建观测信号的全部细节,只需要保留与任务、行动和后果有关的结构。
在杨立昆眼中,所谓的「世界」,首先是一个可用于预测和规划的抽象状态空间。强调的则是世界的可预测性与可行动性:AI 不一定要把世界完整复刻出来,却必须形成一个足够好的内部模型,使自己能够在行动之前预想未来、比较后果并据此规划。
所以,你可以这么理解:这些大佬都觉得,单靠语言模型,不足以通向更完整的智能,未来的 AI 需要对世界有更多的认知和掌控。但对于「接下来要补上的到底是什么」这个问题,答案并不相同。有人想把世界重新带回 AI 的外部接口,有人想把世界压缩进 AI 的内部机制。
我更愿意把它们理解为两种不同层级上的命题:李飞飞在定义一种新的能力目标,杨立昆在定义一种新的认知机制。前者回答「AI 应该成为什么样的存在」,后者回答「AI 内部应该如何工作,才可能成为那样的存在」。
二、李飞飞的「空间智能」
李飞飞自己说,她进入这个领域以来,长期的北极星一直是「视觉和空间智能」:从早年推动大规模视觉学习基准 ImageNet,到后来在斯坦福长期把计算机视觉与机器人学习结合起来,再到创办 World Labs,主线始终是「让机器真正建立对世界的感知与理解」。
「空间智能」是这条主线的自然外推:从识别物体,到理解场景,再到进入世界。
她认为,真实智能首先发生在空间里。人类婴儿在学会说话之前,已经在通过抓取、移动、观察、跌倒和纠正,持续建立关于深度、边界、物体恒常性、因果后果和行动可能性的直觉。对机器而言,缺的恰恰不是更多关于世界的描述,而是这种把感知、几何、物理与行动联结起来的底层能力。
在李飞飞的论述里,下一代「世界模型」至少应当具备生成性、多模态性与交互性。而在 World Labs 的叙事中,这一点被进一步具体化为持续性(Persistent)、可漫游性(Navigable)、可编辑性(Editable)的 3D 世界——这是一个能够被人和机器共同探索、修改、组合和推演的世界。
「3D as code」是这条路线最有启发性的提法之一。它的意思是说:正如文本曾成为调用软件能力的通用接口,3D 表征也可能成为未来调用空间能力的通用接口。
代码之所以重要,是因为它可检查、可修改、可组合、可执行,并能嵌入既有工具链。而 3D 表征如果获得类似地位呢?当世界模型输出的是结构化 3D,而不只是像素时,人可以把它拿到熟悉的工具里继续编辑,机器也可以把它接入渲染引擎、仿真器、物理求解器、机器人栈与 CAD 流程。
这样一来,「空间」就变成了一种像代码一样可以进入生产链条的对象。「世界生成」就不再只是内容生产,而变成一种可编排、可迭代、可协同的生产能力。
一言以蔽之,所谓空间智能,是要重新构建 AI 与现实世界的关系——这个关系在之前长期被语言和扁平化的数据所垄断。如果说 LLM 让机器学会了「谈论」世界,那么空间智能要做的,就是让机器开始真正「栖居」(Inhabiting)于世界之中。
三、杨立昆的「世界模型」
我之前写过几篇介绍杨立昆「世界模型」和 JEPA 的文章,链接放在文末,可以参考。这里不再长篇赘述,只简述核心思想。
杨立昆如果听到「世界模型」被解释成「构建一个完整的 3D 空间」,大概会皱起眉头。不是因为他反对空间智能,而是因为他关注的首要问题不同。
他首要关注的不是AI 如何把外部世界显式做出来, 而是智能体如何在内部形成对世界变化的表征,以便预测、规划和行动。
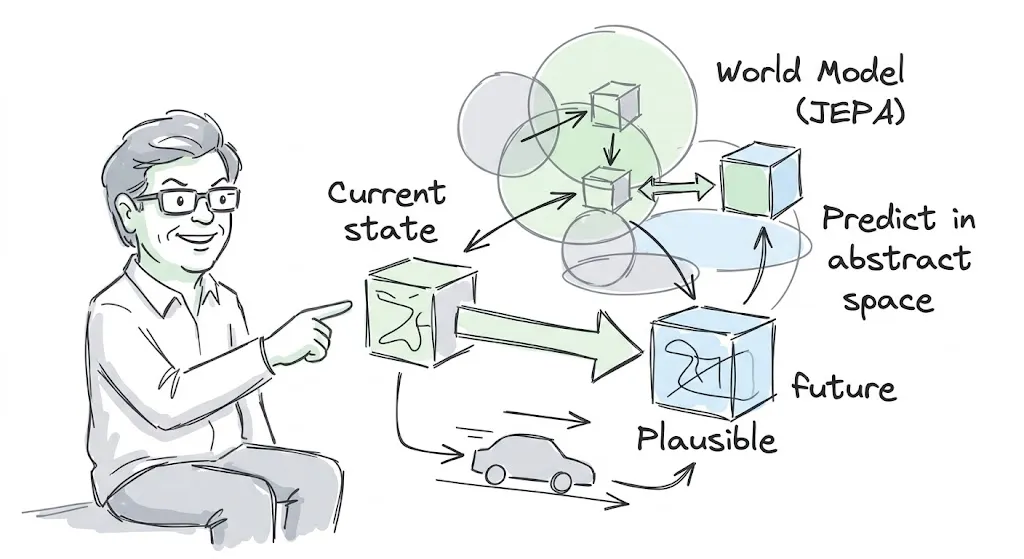
这是他 2017 年以来一直在推进的概念——自主机器智能(Autonomous Machine Intelligence)——的核心。在这个架构里,世界模型不是一个生成 3D 场景的渲染器,而是一个可配置的预测引擎。负责两件事:一是估计感知模块没有提供的世界状态,二是预测「看似合理的未来」(Plausible Futures) 的世界状态,并在多个抽象层级和多个时间尺度上工作。
这个思想有一点「抽象」,也是最容易被大众误读的一点。我们举个具象化的例子。
比方说你在开车。你不需要在脑子里实时渲染出道路、树木、对面来车的每一根线条和纹理。你只需要一个抽象表征:前面那辆车的速度、距离、可能的刹车概率,以及如果你踩油门或刹车会发生的状态变化。那些不必要的细节——车的颜色、轮胎的品牌、路边的广告牌——统统可以丢掉。
这就是为什么他一直在推进 JEPA 这套学习方案。JEPA 不做像素级的生成,而是学习将观测(比如一帧视频)映射到一个抽象表征,然后在这个表征空间里预测未来的表征。
这套东西不是给人看的,而是供行动和规划使用的。杨立昆认为:预测应该发生在抽象表征空间中,而不是观测空间中。 因为观测空间(比如像素)太冗余、太细节,强迫模型去预测每一个像素,浪费算力,还抓不住重点。
这条路线也有它的挑战:如何在不预设显式几何结构、主要依赖表征学习的前提下,学会物理常识?如何保证抽象表征空间能够捕捉到足够多的因果结构,而不只是统计相关性?这些问题至今没有完全解决。
其实,看到这里,你应能明白,这两条路线,不是一回事,但也不是对立的,更谈不上对错之分。
李飞飞强调的是:世界必须成为一个可生成、可编辑、可共享的外部对象。这正是「3D as code」的野心:把三维空间变成一种像代码一样的通用接口。
杨立昆强调的是:世界必须成为一个可压缩、可推演、可规划的内部结构。这正是 JEPA 系列工作的核心:在抽象表征空间里学会物理世界的规律,而不浪费算力去重建每个细节。
这些路线今天看上去是分叉的,但长期看,难保没有汇合的一天。