AI能自己打红警了新智元
红警不再只是童年游戏,而成了AI Agent的硬核训练场:OpenRA-RL把25Hz实时战场、50个工具调用和64局并发打包开源,让大模型第一次真正站上RTS战争迷雾里的公开考场。
AI能自己打红警了。
Hugging Face 刚扔出一个炸弹——OpenRA-RL,直接把经典 RTS《红色警戒》改造成了大模型的 Agent 训练场。
不是套个壳录段视频那种玩具级 Demo,是真·基础设施级别的东西——
50 个 MCP 游戏工具全量暴露,25Hz 实时状态流不间断推送,单进程 64 局并发训练,LLM、脚本 Bot、强化学习 Agent 三条路线全部打通。
更狠的是,它直接原生接入 OpenEnv 生态——TRL、torchforge、Unsloth 训练框架即插即用。
当年 DeepMind 的 AlphaStar 打星际、OpenAI Five 打 Dota,靠的是几千块 TPU 和完全不可复现的定制架构。
普通研究者连门在哪都找不到。
而现在,开源社区第一次把 RTS Agent 训练的门槛一脚踹到了地上——一台消费级显卡,一行 pip install openra-rl,你就能站在同一条起跑线上。
实战:经济满分,战斗零蛋
让我们看看实战。
团队用 Ollama 本地部署了一个 Qwen3 32B 模型,在 128×128 的盟军地图上对阵游戏内置的 Beginner AI,跑了 5 局。
Agent 通过 MCP 工具集接收结构化观测、发出动作指令,每局前有策略规划阶段,结束后有反思复盘,从中提炼的经验会注入下一局的系统提示。
结果:全部以平局告终,零次战斗交锋。
Agent 在每一局都成功建起了经济体系,但从未生产出一支进攻部队。
有趣的是,如果只看胜负,5 局全平,故事就讲完了。
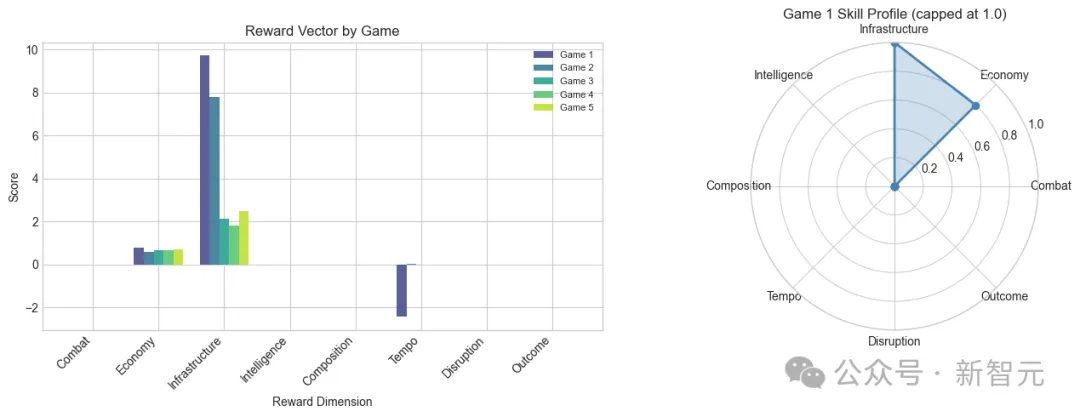
但 OpenRA-RL 提供了 8 维奖励向量,画面一下就丰富了:经济维度得分 0.58-0.80,基建表现稳定,但战斗和骚扰两个维度是干脆的零。
这就是一个精确的失败模式诊断——你能据此设计奖励塑形和课程学习策略。
下面这段 Game 5 前 10 回合的决策日志,能直观看到模型的「思考节奏」:
Turn 1 | get_faction_briefing()
Turn 2 | end_planning_phase(strategy=「」Deploy MCV, build Power Plant (300 ticks), then Barracks/War Factory (500/750),train E1 + 1tnk, attack AI base at (64,64).「」)
Turn 3 | deploy_unit(unit_id=120)
Turn 4 | build_and_place(building_type=「」apwr「」)
Turn 5 | advance(ticks=100)-> tick=55, cash=$5000, units=0, buildings=1
Turn 6 | build_and_place(building_type=「」apwr「」)
Turn 7 | build_and_place(building_type=「」powr「」)
Turn 8 | advance(ticks=60)-> tick=108, cash=$4923, units=0, buildings=1
Turn 9 | advance(ticks=130)-> tick=159, cash=$4838, units=0, buildings=1
Turn 10 | advance(ticks=80)-> tick=210, cash=$4753, units=0, buildings=1
三段式节奏清晰可见:情报+规划 → 建造经济 → 用 advance 快进来弥合 LLM 推理延迟和游戏速度之间的鸿沟。
工具调用分布也印证了这一点——advance 占了全部调用的约 57%,这正是异步架构设计的核心价值所在。
另一个耐人寻味的细节:第 2 局的赛后反思发现了「战争工厂应该排在发电厂后面」这个建造顺序错误,到第 4 局开局计划确实改成了先建发电厂。
提示注入式学习能修复建造顺序,却填不上战斗维度的零分——这恰恰就是从上下文适应到权重更新式强化学习应该产生可量化提升的地方。
为什么是红警?为什么是现在?
为什么偏偏选红警当训练场?
先看一个问题:一个前沿大模型,不做任何 RTS 专项训练,能在即时战略游戏里撑多久?
诚实的回答是:没人知道。
因为现有的 RTS 平台压根就不支持 LLM Agent。
SC2LE、PySC2 这些经典框架默认你的 Agent 在毫秒级别行动,动作空间是低层操作。
LLM 的需求恰恰相反——它需要高层接口、异步交互,以及对推理延迟从 40 毫秒到好几秒剧烈波动的容忍。
硬把 LLM 往老框架上嫁接,能跑是能跑,但结果不可比较,别的团队也没法复现。
OpenRA-RL 选了经典 Westwood RTS《红色警戒》作为底座,基于开源项目 OpenRA 魔改游戏引擎。
理由很朴素:策略深度够,代码干净能改,自带从 Beginner 到 Hard 的 AI 对手梯队。
最终的效果是,你拿 Qwen3、Claude 还是一个 Python 脚本 Bot 来对打,都是同一个环境、零改动。
OpenRA-RL 的架构可以用「三层三明治」来理解:
最底层是魔改过的 OpenRA 游戏引擎,用 C# 写的,以约 25Hz 的频率不停跳动游戏心跳。
中间是 gRPC 桥接层,实时往外推送观测数据、接收操作指令。
最上层是 Python 封装,对外暴露 Gymnasium 风格的 reset / step / close 接口。
在此之上,MCP 服务器把 50 个游戏动作暴露为工具,任何兼容 MCP 的 LLM 客户端都能驱动一局游戏。
这套分层的核心目的只有一个:Agent 的计算和游戏的执行完全解耦。
一个 40 毫秒一步的脚本 Bot 和一个 2 秒一步的 LLM,跑在同一个 25Hz 引擎上,互不干扰。