这个开源模型把图像理解和生成统一了量子位
4/29/2026
这两天打开朋友圈,10 条里有 7 条都是 GPT-Image-2 生的图。
中文海报、复古杂志封面、直播画面、社交截图,连高考试卷都能照着出一张几乎以假乱真的。
对此,大家伙的反应也都出奇的一致 —— 专业设计师们完了,我又能行了!
但实际上上手你就会有同感:免费用户一天几张,抽卡次数有限,遇到稍微严肃点的活,额度马上到顶,常常是活没干完,次数没了。
针对这一空档,商汤刚刚开源了一个全新架构的理解生成统一模型 SenseNova-U1,虽然小尺寸版本只有 8B,却能复刻不少 GPT-Image-2 的拿手绝活。
比如,我们拿它做一张量子位的招聘海报:文字、版式、配色,挑不出毛病。
△图片由 SenseNova U1 生成
太阳系图解,八大行星各自的轨道、属性、图文介绍一应俱全,看着挺像那么回事。
△图片由 SenseNova U1 生成
画个钢铁侠,模型也能自动从轮廓、铺色、细节、质感、氛围等多个阶段拆解完整的绘画流程。
来个马斯克太空集群的信息图也审美在线。
△图片由 SenseNova U1 生成
可以说,信息图(InfoGraph)、文字密集排版、图文交错 —— 这几个曾经被公认是 AI 生图最难啃的硬骨头,U1 能跟 GPT-Image-2 挤进一桌。
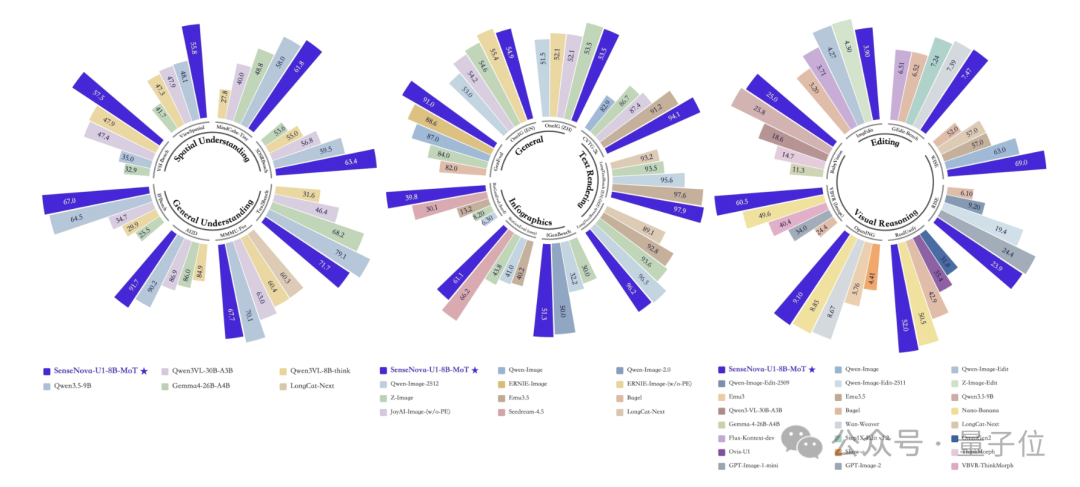
在具体的图像理解与生成的多项指标上,SenseNova-U1 也是登顶开源模型的榜首。
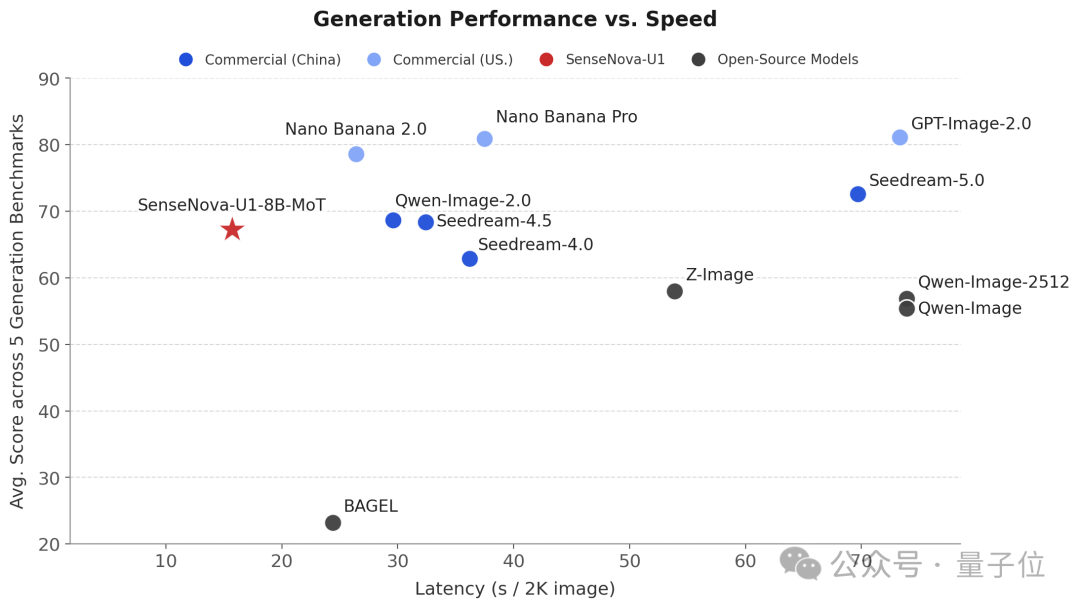
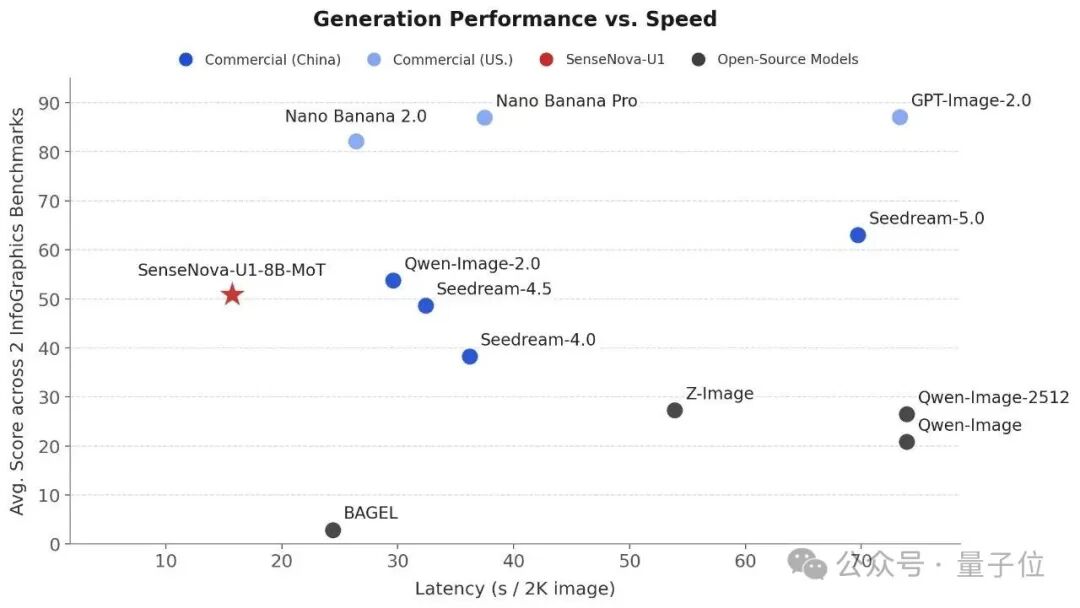
在推理响应速度上也具备相当的优势,逼近主流商用闭源模型。