DeepSeek与Kimi的隐秘交点:中国芯片腾讯科技
Kimi发布开源模型K2.6,强化代码与Agent能力。其最新论文提出“预填充即服务”架构,通过混合模型大幅压缩KV缓存,实现跨数据中心、异构硬件的推理降本。这一实践为中国模型适配国产芯片打通了可行路径。在DeepSeek V4尚未发布之际,Kimi已率先为“中国芯片+中国模型”的合体探路。
“K2.6是我们迄今为止最强代码模型。”Kimi在公众号中写道。
4月20日晚间,Kimi正式推出编程、Agent能力都表现更强的开源模型K2.6,距离上一个版本K2.5发布刚好一个季度左右。
这里还有一个小插曲,传闻本周DeepSeek V4也将发布。如果一切按外界预期的推进,这将是Kimi和DeepSeek的第N次撞车。但在更底层的基础设施层面,还有一条暗线:Kimi和DeepSeek这两个大模型创业公司,终将踏入同一条河流——与国产芯片创业公司共进退。
时间倒回2026年3月份,杨植麟在英伟达GTC演讲台,谈及Kimi的技术路线图。他说:“目前普遍使用的很多技术标准,本质上是八九年前的产物,逐渐成为Scaling的瓶颈。”
为了解决类似问题,Kimi给开源社区贡献了首次大规模应用的二阶优化器MuonClip、让大模型处理长上下文更高效的Kimi Linear架构,以及优化深度神经网络层连接的Attention Residuals。
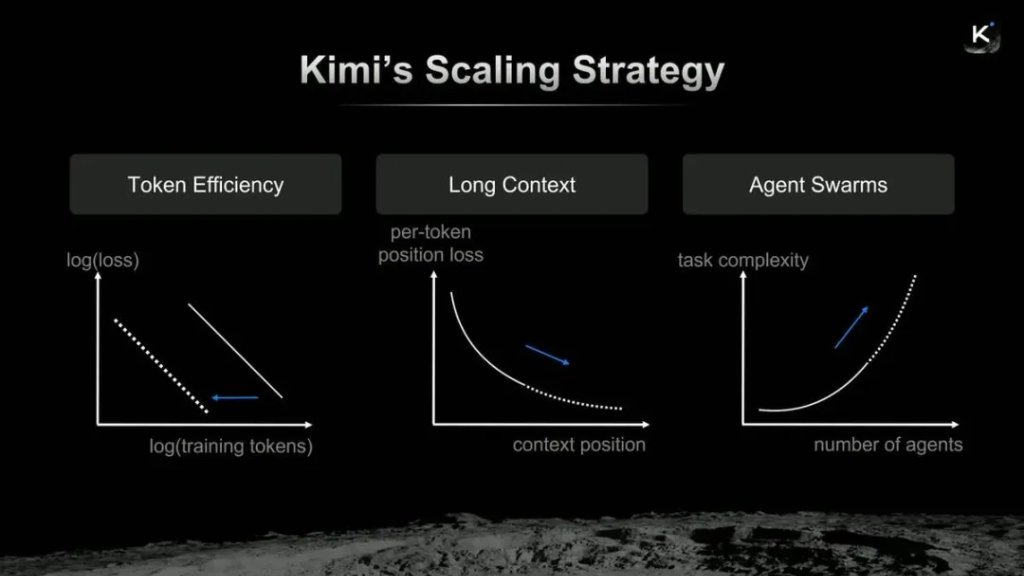
Kimi的Scaling策略
杨植麟认为,将Kimi的进化逻辑归纳为Token效率、长上下文以及智能体集群“合体”。刚刚上线的Kimi K2.6,可以理解为杨植麟在这条Scaling路径下新交的一份作业。
Kimi官网已接入K2.6
代码、Agent,还有呢?
作为最容易标准化的能力项之一,代码是前沿模型的必争之地。
从K2、到K2.5、再到K2.6,Kimi在几个开源模型上保持着平均一个季度左右的迭代节奏,但由于这是个小版本号,暗示杨植麟手中可能还有更多的底牌。
“K2.6长程编码能力显著提升,在测试中可以不间断编码13小时,编写或修改超过4000行代码,”Kimi在一份传播材料中写道,“在涵盖了多种复杂端到端任务的、Kimi内部严格代码评测基准Kimi Code Bench中,K2.6的成绩比K2.5提升了约20%。”
要知道K2.5已经是一个非常“能打的模型”,OpenRouter上2月份一度霸榜。一位接近Kimi的知情人士贴出了联合创始人张宇韬发当时在朋友圈的截图,“他貌似对这个版本很满意。”
通用Agent、编程和视觉Agent基准测试上,K2.6的表现
对OpenClaw、Hermes这类Agent框架,K2.6的核心提升集中在API调用的精准性和长时间运行的稳定性——一个是提升任务执行的成本,一个则是优化任务执行的销效率。
1月份上线的K2.5当中,Kimi提出了“Agent集群”的概念,将一项任务拆分成多个子项目,自动化分配给不同领域的Agent来跟进处理,进而缩短任务处理的失效,同时避免串行任务流下整个项目崩溃的可能性。
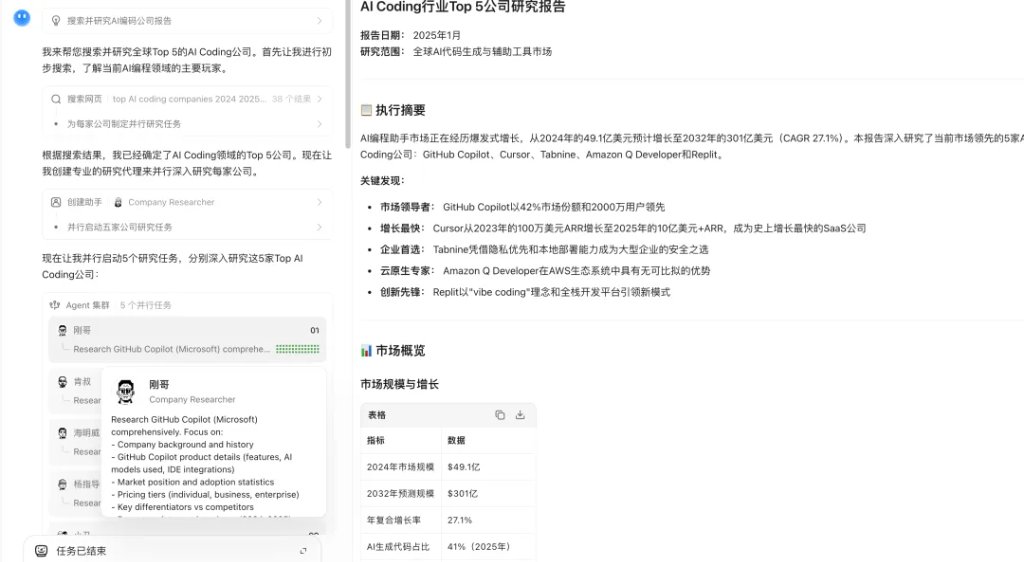
Kimi K2.6的Agent集群能力演示
在新的K2.6版本中,这个能力被进一步放大,将广度搜索与深度调研、大规模文档分析与长篇撰写以及多格式内容生成进行集成与并行处理,最多支持300个子Agent并行完成4000个协作步骤。
如果要一句话概括Kimi K2.6亮点,大致包括:代码和长程任务能力进化、Agent集群能力进化与主流Agent框架适配优化。
如果要从上述的功能特性里面找一个个人的偏好,我认为Agent集群是最有价值的一个能力,它直接将并行计算爆炸性能力具象化了——无论是代码,还是长程任务的稳定性,这些都是模型迭代必须去做的事情,更重要的是,基于这些能力提升,推动Agent的工作方式、效率甚至是交互方式创新。
毕竟,作为用户,我要的不是它告诉我能怎么样,而是它能驱动Agent来解决我实实在在的问题,形成有效生产力。
K2.5上线的时候,一位学界研究员开始利用这款模型开展科研项目,当时他的评价是没有短板,可以作为科研助手。
“官方提供的多Agent确实有效,去年国产的Agent很多还是toy。”
如果Kimi K2.5在内外部评价都不错,在这个基础上更进一步的K2.6,效果会如何呢?
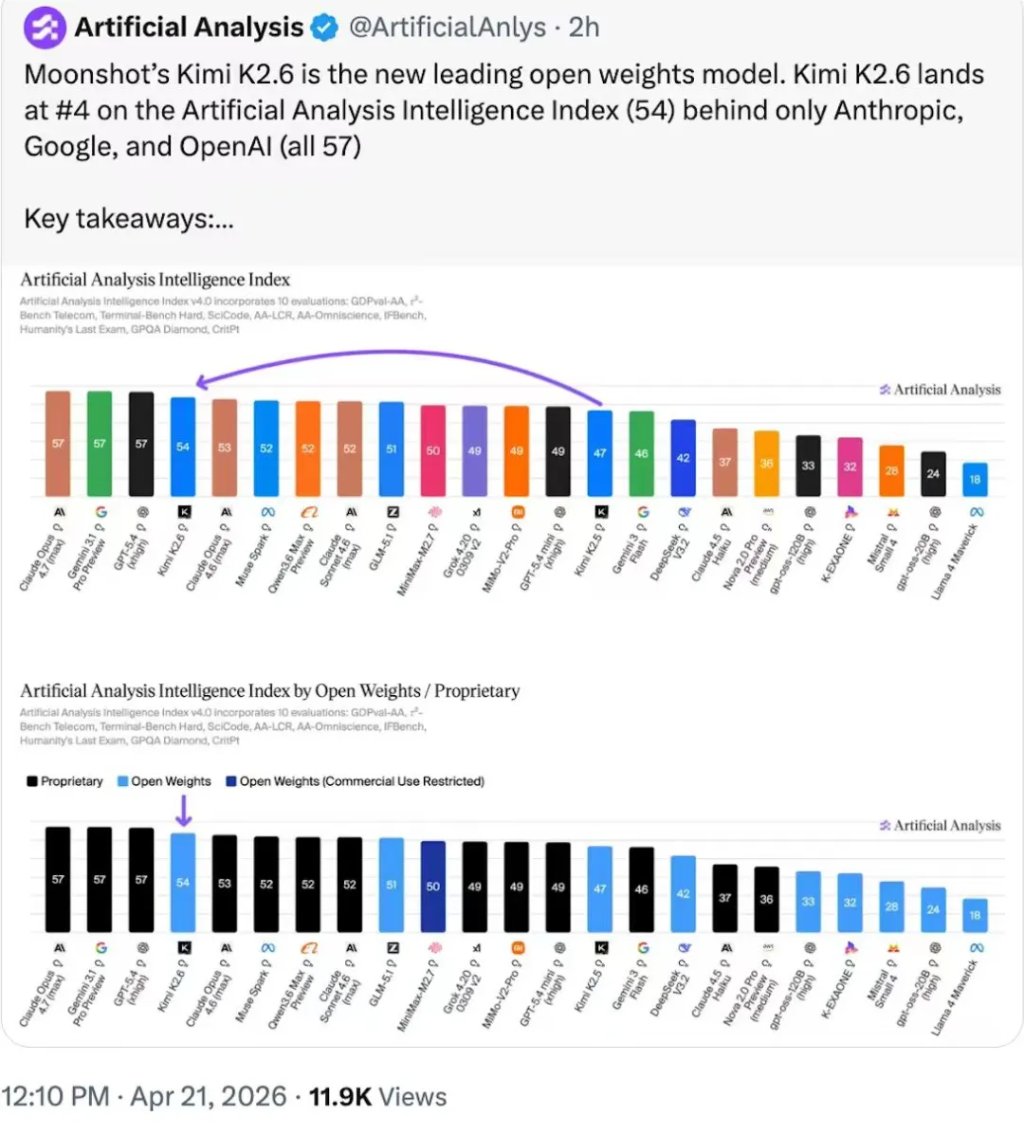
Artifacial Analysis智能榜单,Kimi K2.6仅次于三家闭源模型,并领跑开源模型权重榜单
路线图里的“新故事”
Kimi总是时不时给行业搞点新意思,其中就包括杨植麟演讲中路线图里提到MuonClip、Kimi Linear、Attention Residuals,一些探索也得到了行业顶流的正向打Call。
3月中旬,Kimi发布Attention Residuals这篇论文,提出利用注意力机制来改造残差连接,马斯克直接发推称这是“Kimi做得令人印象深刻的突破。”
上周末,Kimi发布了一篇新论文《Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter》,(PrfaaS,预填充即服务),提及Kimi在架构上的新探索,核心讨论的仍然PD分离(Prefill和Decode)。
PD分离并不是新话题——模型推理的Prefill阶段属于计算密集任务,Decode阶段则依赖显存带宽,显存要来回读写KV Cache——这种架构要解决的是将计算密集型任务和带宽密集型任务解耦,提高算力利用率和吞吐量,进而降本增效。
PD分离虽好,但也有一个卡点:必须基于同机房的RDMA高速网络。
Kimi的PrfaaS这篇论文,核心点在于:基于混合模型(Kimi Linear)大幅缩减了KV缓存体积,然后把Prefill和Decode彻底解耦到不同的异构集群。
论文提及的实验示例显示,PrfaaS专用预填充集群使用32张主打高算力的H200;本地PD解码集群使用张通过RDMA内网互联的H20 GPU;两组集群通过VPC专线打通,跨集群总带宽约100Gbps。测试模型为1T参数的Kimi Linear混合注意力模型。
实测结果显示,PrfaaS‑PD跨数据中心方案,相比采用96卡H20同PD集群方案,吞吐量提升54%,P90 TTFT(90%的用户,从发请求到看到第一个字返回的等待时间)从9.73s降至3.51s,降低6 4%,跨数据中心 KV缓存传输带宽仅占用总带宽100Gbps中13%。
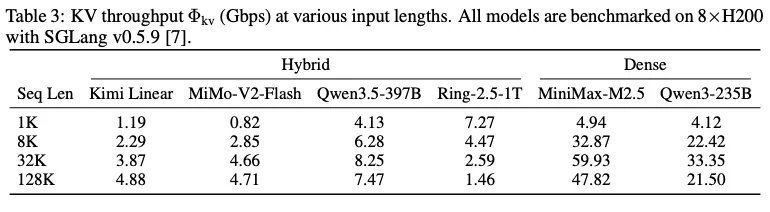
不同上下文长度下,混合架构模型与稠密模型KV吞吐量对比
为了证明混合模型架构的优势,论文提到一组实验:8卡H200和SGLang v0.5.9推理框架下,对多款主流模型进行基准测试,32K上下文长度时,采用混合注意力的MiMo‑V2‑Flash模型KV 吞吐量仅4.66Gbps,而同规模稠密注意力模型MiniMax‑M2.5高达59.93Gbps,直接证明混合注意力架构可将KV缓存传输需求压至普通以太网可承载范围。
“跨数据中心+异构硬件,解锁显著降低单token成本的潜力。”Kimi在官方账号上说。