ImageNet之后,李飞飞再出手量子位
ImageNet之后,李飞飞再出手!
李飞飞团队最新发布ESI-Bench——一个专门用来评测具身空间智能的新基准。
过去的空间智能评测默认给模型最优观测,而ESI-Bench第一个把观察者变成行动者,闭合了感知-行动回路。
它为具身空间智能领域提供了一个系统性的评测框架,覆盖人类核心空间认知能力的四大维度。
论文的核心结论是:
现在的AI看图很厉害,但离「会动、会摸、会主动找答案」的空间智能还差得远。
ESI-Bench是什么
ESI-Bench发布的背景,是由于目前的空间智能benchmark,测的都是「被动感知」。
把一张或几张图片扔给模型,问「A物体在B物体的左边还是右边」「这个杯子能装多少水」「抽屉里有没有东西」,这样的题目测出来的是模型的视力,而非空间推理能力。
反观人类是怎么做的?人类会站起来绕到物体背后去看,会把抽屉拉开,会把水倒出来量一量。
这就是ESI-Bench的核心立场:
把观察者变成行动者。
现实世界里,智能体必须像人类一样,主动决定行动、获取证据,再基于新观测做下一步判断。团队把它称为「感知-行动回路」(Perception-Action Loop)。
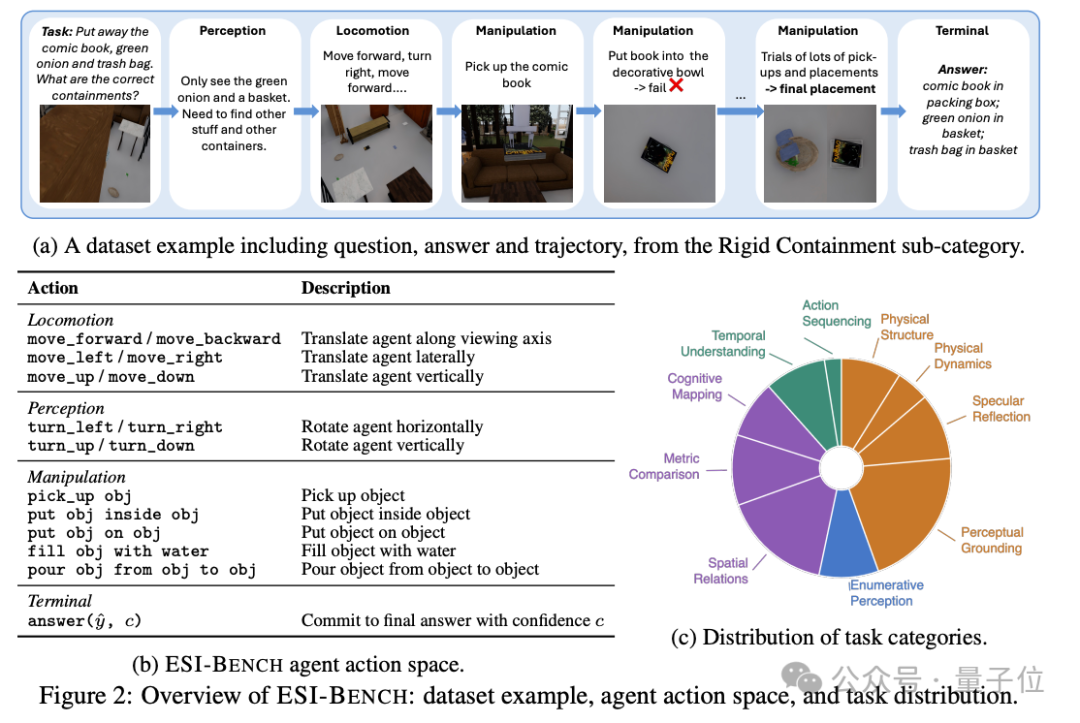
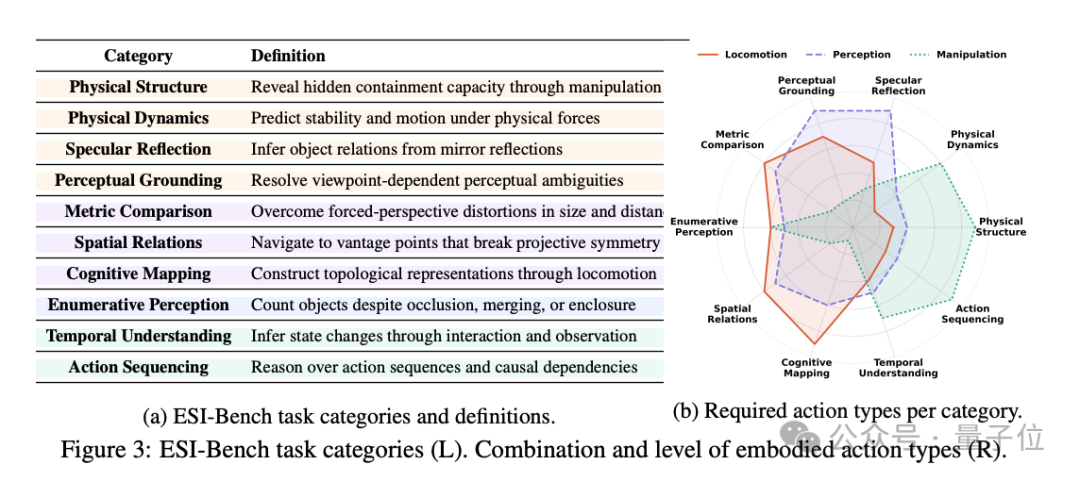
ESI-Bench就是这样一套超越现有基准的空间智能新评测基准,它包含10个任务类别,29个子类别,3081个任务实例,全部在OmniGibson仿真平台上构建,场景素材来自BEHAVIOR-1K场景库。
所有任务围绕Spelke的四大核心知识系统设计,也就是人类婴儿天生就具备的空间直觉:物体表征、布局与几何、数量表征、目标导向行动。
它的关键设定在于行动强制。每一道题,AI智能体必须主动行动才能拿到足够信息作答。模型不能坐在原地等图片,它要决定往哪走、看什么、拿什么、怎么操作。
举几个具体的例子:
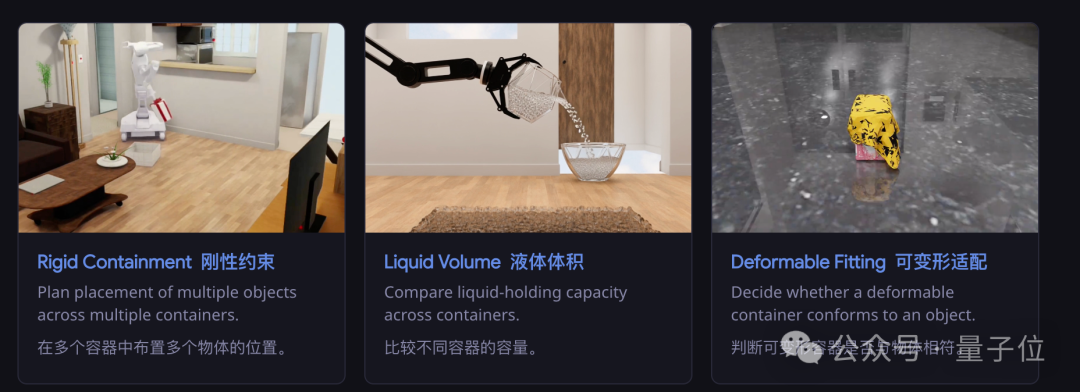
比如评测中有一道「刚性容纳」题:给定几个容器和几个物体,要求把物体全部装进去。有的容器开口小、有的内部有隔板、有的盖子需要掀开才能看到真实容量。
模型必须走近、俯身、甚至把容器拿起来从底部观察,才能判断能不能装得下。
还有「液体体积」题:两个杯子,从外观看不出容量差异,模型需要把水倒进去测试,或者直接拿起来掂量。
这么一说,大家应该也能直观感受到这套评测基准的设计理念:
正确答案不在任何单张图片里,智能体必须主动行动并推理出正确结果。
团队特别指出,与此前工作相比,ESI-Bench在三个地方有所超越:
从空间感知到空间能力:在这里,智能体不仅根据他们能感知到什么来评估,还根据他们是否知道部署哪些具体能力来解决空间任务来评估;
选择性感知:智能体必须确定哪些观察值得获取,优先考虑与任务相关的信息而不是冗余或无信息的输入;
解决感知歧义:智能体必须通过误导性观察进行推理,以推断隐藏的空间结构和超越直接观察的潜在物理约束。
测完发现了啥?3个核心结论
团队拿当前最强的多模态大模型做了全面测试,包括GPT-5和Gemini系列。
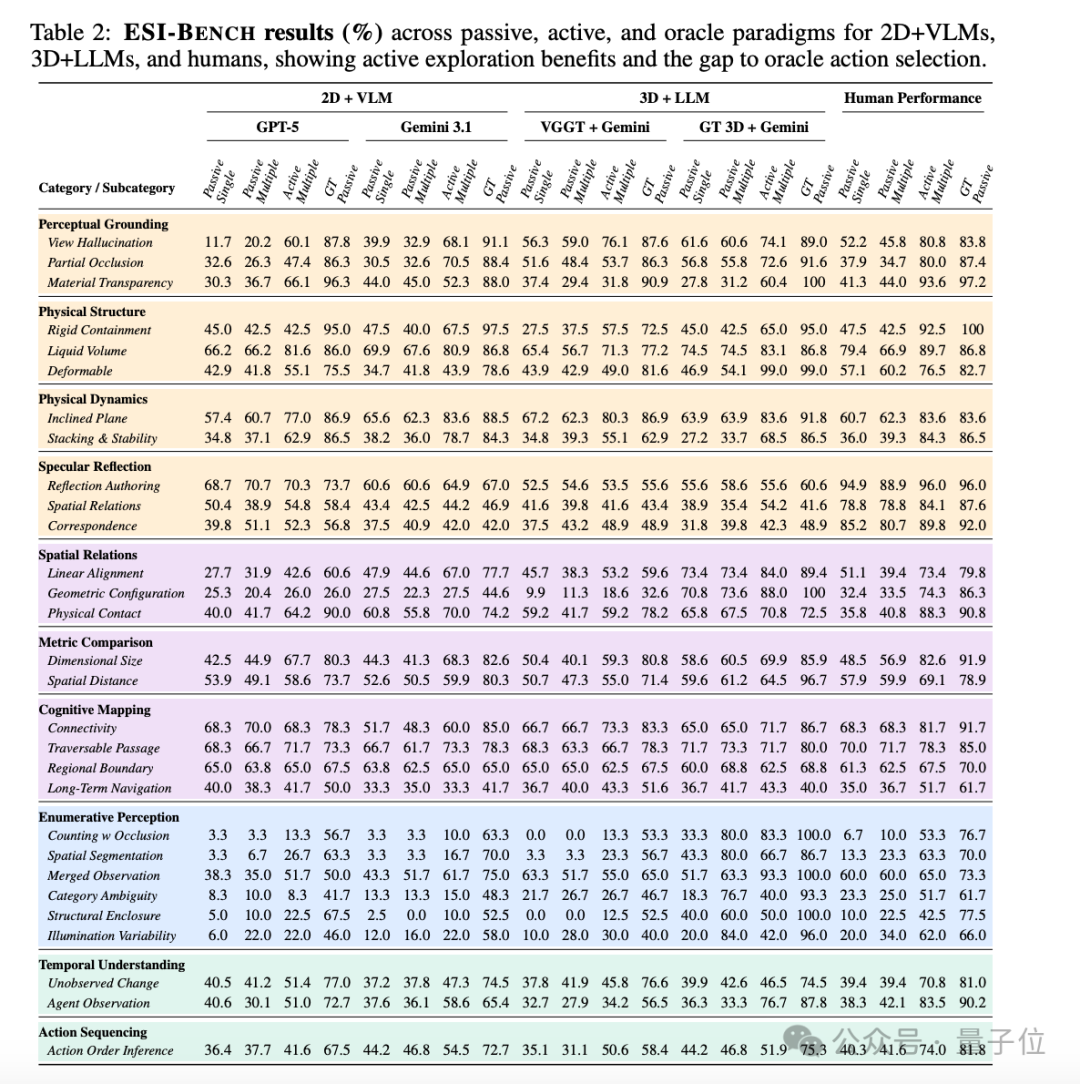
这是最主要的实验结果图,包含了ESI-Bench在被动感知、主动探索、Oracle三种范式下的各项任务准确率,涵盖2D+VLM、3D+LLM及人类基线。
核心结论有3个。
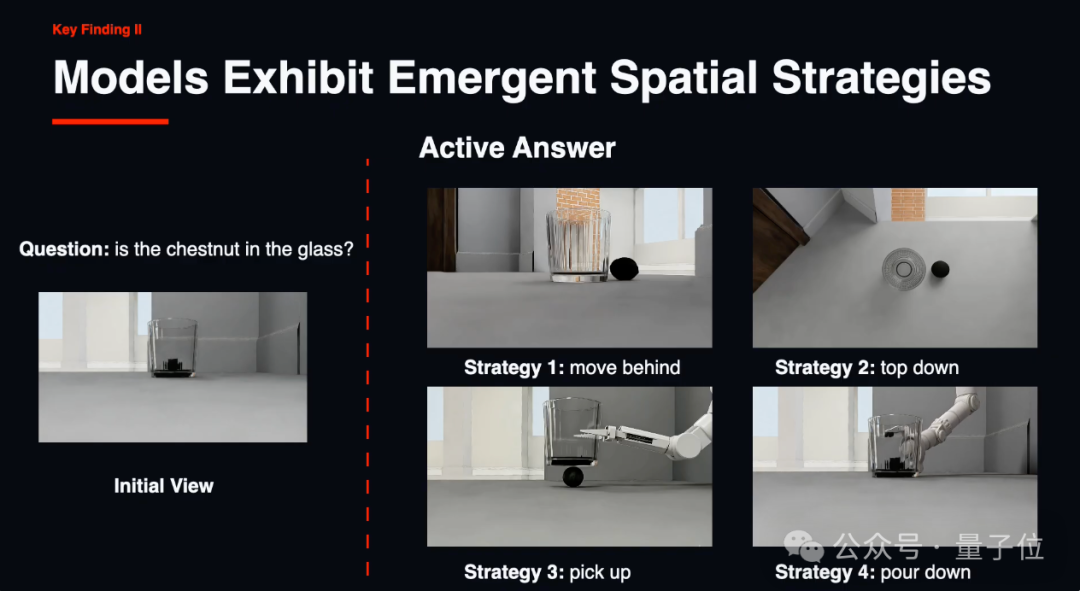
第一,感知不是瓶颈,行动才是。
好消息是,主动探索确实有效。在没有额外指令的情况下,智能体自发涌现出多种空间策略。
比如绕到物体背后观察(move-behind)、切换俯视角度(top-down)、把物体拿起来(pick-up)、把水倒出来验证(pour-out)。
Gemini 3.1在「部分遮挡」任务上,如果给到最佳观察视角,准确率从14.6%暴涨到95.1%。