为什么完美的AI Agent不存在?量子位
当AI编程工具进化为能自主执行任务的智能体,架构层面的设计选择不再只关乎性能,更关乎安全、可控性与可持续性。MBZUAI VILA Lab联合UCL以Anthropic的Claude Code源码为案例,系统分析了生产级AI智能体的设计空间。
这篇文章在X上也引起了广泛的关注和讨论:
来自MBZUAI VILA Lab的研究团队发布了一项新研究,以Anthropic的Claude Code源码为案例,对生产级AI智能体(Agent)的架构设计空间做了系统分析。论文尝试探讨一个问题:构建一个生产级AI智能体,需要回答哪些设计问题?
Claude Code是当前一代AI编程工具的代表:在终端里输入一句”帮我修复auth.test.ts里失败的测试”,它会自己收集上下文、规划步骤、调用工具、执行命令、检查结果,反复迭代直到认为任务完成[7]。围绕它的源码解读文章已经有不少,但多数聚焦在”怎么实现”的层面。
这篇论文的切入点不同:
它不满足于描述实现细节,而是尝试从源码和官方文档中反推出驱动整个架构的设计哲学与设计原则,分析权限、上下文管理、可扩展性、子智能体等关键子系统的设计选择。同时通过与近期备受关注的开源智能体系统OpenClaw的对比,展示同样的设计问题在不同部署场景下可能导向不同的答案。
论文的分析基于以下几类信息来源:Claude Code v2.1.88的TypeScript源码、Anthropic官方发布的博客和产品文档,以及社区的逆向工程分析报告。
观察一:五条设计哲学塑造了架构,但它们之间存在矛盾
论文没有上来就讲技术细节,而是先追问了一个更底层的问题:这个系统为什么要设计成这样?通过综合Anthropic官方文档、源码和相关资料,论文总结出五条驱动架构,以人类价值观为导向的设计哲学:
人类决策权威
人类要能随时看到、批准或否决智能体的操作
安全、隐私与数据保护
即使人类不注意,系统也要能自己保护用户及其代码和数据
智能体做的事要和人类想的一致,长时间运行也不能走偏
系统要让人类能做到以前做不到的事
上下文适应性
系统要能适应用户的具体项目、工具、习惯,并随使用时间逐步改善
在此基础上,论文从官方文档和社区分析中总结出十三条设计原则(Design Principles),例如”拒绝优先(Deny-First)“、”渐进式信任(Graduated Trust)“、”纵深防御(Defense in Depth)“、”最小脚手架、最大操作Harness(Minimal Scaffolding, Maximal Operational Harness)”等。
但论文发现,这些设计哲学之间存在部分矛盾。例如:
人类决策权威vs.安全
根据Anthropic的分析[1],用户批准了约93%的权限弹窗,频繁的审批点击导致用户对授权内容的注意力下降。因此安全不能完全依赖人类审批,系统需要有自己的防护机制。
安全vs.能力
严格的安全检查会带来性能代价。安全研究机构Adversa.ai [2]发现,当一条命令包含50个以上子命令时,如果逐条做拒绝规则检查会导致界面冻结。于是系统选择保持响应速度,退化为单条审批,放弃了逐条检查。这说明在性能压力下,多层安全防御可能被迫让位于可用性。
可扩展性vs.安全
丰富的扩展能力会扩大攻击面。Check Point Research的安全研究[3]发现,Hooks和MCP扩展在信任对话弹出之前就会加载,这个时序窗口被已披露的安全漏洞(CVE-2025-59536、CVE-2026-21852)所利用。扩展性越强,提前加载的代码越多,可被攻击的窗口也就越大(这些漏洞已在披露后数周内修复)。
这些矛盾更像是同时追求多条设计哲学所带来的取舍,而非设计缺陷;类似的权衡在其他智能体系统中也可能出现。
观察二:“最小脚手架、最大操作Harness”
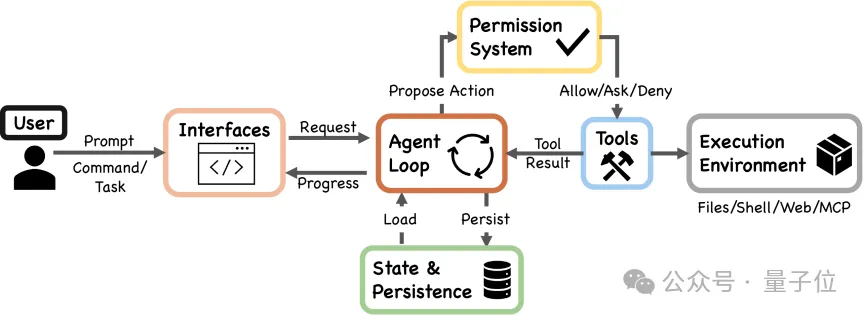
△ 图1:Claude Code的高层系统结构
系统由七个功能组件构成:用户、接口层、智能体循环、权限系统、工具、状态与持久化、执行环境。
这里的”脚手架”(Scaffolding)是指约束和引导模型决策的规划框架,”操作Harness”则是围绕模型运行的基础设施。对源码的分析显示,Claude Code的绝大部分代码是确定性基础设施(权限检查、工具路由、上下文管理、错误恢复),AI决策逻辑只占约1.6%。核心的智能体循环(Agentic Loop)是一个持续迭代的过程:调用模型、获取工具调用请求、执行、返回结果,直到模型停止请求。
在智能体工程领域,存在不同的设计取向。一些框架(如LangGraph [8])将决策逻辑编码为显式的状态图,而Claude Code选择了另一条路:不硬性规定模型的决策路径,而是给模型较大的决策自由度,同时用确定性代码保障安全执行。
论文的分析指出,随着前沿模型在编码能力上趋同,围绕模型的操作Harness的质量可能成为产品差异化的重要因素。
用户请求执行流程
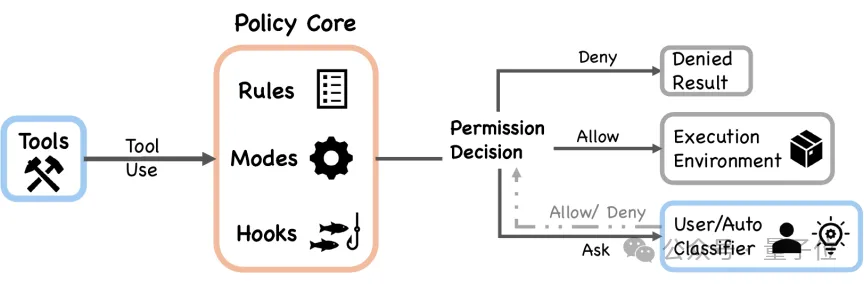
△ 图2:智能体循环的多轮迭代过程。
用户输入经过上下文装配进入循环:模型产出工具调用请求,由权限系统判定,允许则执行,拒绝则把反馈返回模型重试;遇到上下文压力时会触发压缩。循环持续直到模型不再请求工具,输出最终回复给用户;用户继续对话则再次进入新一轮循环
上面两节讨论了”为什么这样设计”,接下来看”具体怎么运行”。论文用一个”运行示例”串起各个架构层级:假设输入”帮我修复auth.test.ts里失败的测试”,系统会先组织上下文(加载CLAUDE.md项目指令、对话历史、工具定义、git状态等),然后在每轮模型调用前执行上下文压缩管道。在调用模型之前,权限系统已经通过工具预过滤移除了被禁止的工具。模型在可见的工具范围内决定要调用哪些工具后,权限系统再次判断具体操作是否允许执行。通过后工具执行,结果喂回模型,进入下一轮循环。子智能体委派也是通过Agent工具在这个循环中触发的。