港中文开源Agent治理内核:高危拦截92.95%新智元
ArbiterOS是一种面向智能体的运行时治理系统,不依赖传统安全手段,而是通过拦截、解析、治理、观测四步流程,提升智能体在复杂环境中的安全性与可控性,适用于多种智能体框架,为高敏感领域提供可复用的治理底座。
随着Scaling Law持续推进,Agent正在从「会回答」走向「会行动」。
当智能体开始自主调用API、执行多步工作流、访问敏感数据,甚至连接物理设备时,仅依赖训练阶段的对齐,已越来越难以覆盖真实环境中的系统级风险。问题的关键在于:训练是离线的,而风险是实时的。
针对这一困境,香港中文大学CURE Lab团队推出了ArbiterOS。它不是又一个外挂式安全补丁,也不只是一个附加在智能体链路外层的过滤器,而是面向智能体的治理内核(governance kernel):在高风险动作真正执行之前,对模型输出、工具调用与数据流进行结构化审查、策略裁决和运行时约束。
论文链接:https://arxiv.org/pdf/2604.18652
如果说传统操作系统负责管理人类程序的资源访问与运行边界,那么在Agent时代,ArbiterOS 试图补上的,正是自主行动智能体长期缺失的一层运行时治理能力。
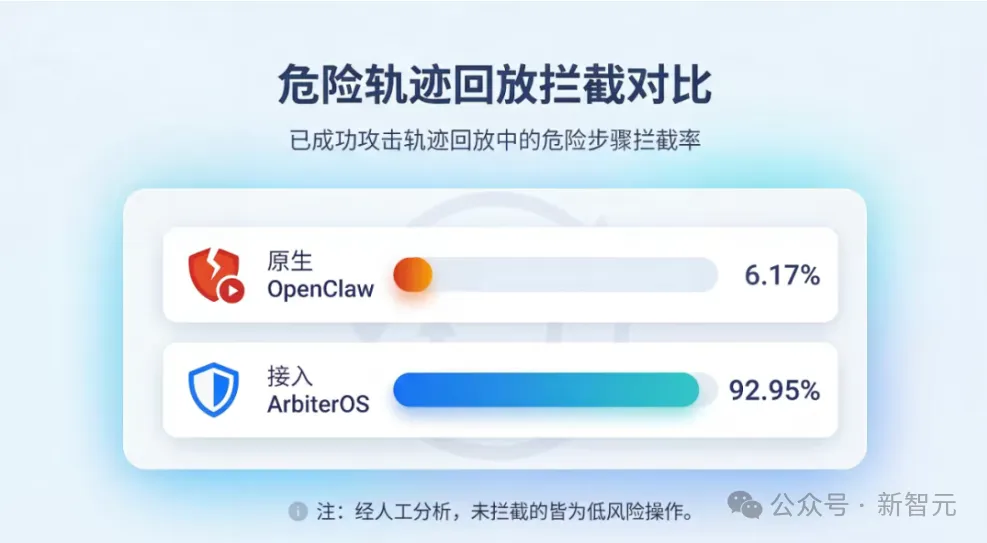
在工程化测试中,ArbiterOS 展现出了显著的安全增益。以主流智能体系统 OpenClaw 为例,在一组涉及私钥泄露、敏感配置外发、文件误删等高风险任务中,原生系统的高危步骤拦截率仅为 6.17%;接入 ArbiterOS 后,这一指标提升至 92.95%。
与此同时,在Agent-SafetyBench与AgentDojo已验证可以成功攻击的攻击的示例中,ArbiterOS的实时拦截率均超过94%;在WildClawBench的高风险工作流评测中,系统实现了100%的及时预警。
ArbiterOS并不依赖某一种特定智能体框架。除了在OpenClaw上完成系统验证外,团队还在近期快速适配了新近受到广泛关注的HermesAgent,整个接入过程仅需数小时。
对于非Claw类Agent,ArbiterOS同样可以支持。它真正依赖的,是开发者能否将智能体的动作语义、执行边界和关键风险点清晰定义为可治理的policy。这也意味着,ArbiterOS的潜力并不止于一个特定生态插件,而是一层可迁移、可复用的Agent运行时治理内核。
项目网址:https://arbiteros.ai/
GitHub地址: https://github.com/cure-lab/ArbiterOS
为什么智能体需要运行时治理?
过去一段时间,围绕OpenClaw等通用智能体框架,业界已经出现了大量安全增强方案,包括提示词约束、附加式Guardrail、流程审批、安全监控和沙箱隔离等。
客观地说,这些方法都具有现实价值。但如果把现有主流防护手段拆开来看,会发现它们大多要么在输入端加限制,要么在输出端做过滤,要么在运行环境外层做刚性约束。它们能缓解风险,却还不足以构成一套真正面向智能体行动的治理架构。
问题至少体现在三个层面。
1. 提示词约束与人工确认并不可靠
大模型底层并不能天然严格地区分「指令」和「数据」。这意味着攻击者可以通过 Prompt Injection 等方式,把原本只是数据的一段内容重新伪装成系统指令,绕过文本层的约束。与此同时,频繁的弹窗确认也并不是理想解法,这样用户会疲于应对,并且普通用户往往也并不具备判断某个 API 调用、外部请求或系统操作背后真实风险的能力。系统看似「处处询问」,实际却未必真正更安全。
2. 语义过滤难以理解真实上下文
附加式 Guardrail 更擅长判断单次输入或输出在语义上是否可疑,因此对于明显的敏感信息泄露或违规表达,往往仍具备一定效果。但它通常并不掌握完整的系统状态,也难以持续追踪数据来源,所以容易漏掉另一类更隐蔽的风险:局部语义完全正常、但在全局上下文中不应发生的操作。例如,代理向外部服务发起了一次格式合法、参数普通的 HTTP 请求,请求中引用的资源标识或业务数据看上去都无异常;然而这些数据实际上来自前序步骤中的越权读取,或属于当前用户无权访问的上下文。由于缺乏跨步骤、跨来源的全链路感知,这类风险很容易绕过语义层面的单点语义护栏。
3. 沙箱隔离会陷入「安全—可用性」的权衡
传统沙箱依赖的是刚性限制:限制目录、限制网络、限制设备访问。但沙箱本身并不理解 Agent 的意图,也无法判断「这次修改配置到底是正常维护,还是恶意篡改」。如果过度隔离,Agent 的实际能力会被直接削弱;如果为了生产力而打开足够多的权限,风险又会顺着这些权限缝隙重新渗透回来。
综合上述三个层面,我们可以发现问题不是「安全插件够不够多」,而是当前智能体系统仍然缺乏一层真正的运行时治理底座。 当极其聪明、随时准备执行动作的智能体,在没有系统级权限约束的前提下运行时,风险并不会因为模型更强而自然消失。相反,越是面向金融、医疗、自动化运维等高敏感场景,越需要一种可审计、可复盘、可配置的执行前治理机制。对这些领域而言,不可控、不可审计,往往就等于不可用。
ArbiterOS在补什么缺口?
ArbiterOS 的核心主张可以概括为一句话:把安全从不稳定的语义博弈,推进到确定的动作治理。
它提出了一种「治理优先」的架构设想:无论上层 Agent 使用了多复杂的Prompt、多长的上下文、多步推理或多种工具,只要它最终准备执行一个高风险动作,例如写本地文件、修改关键配置、对外发起网络请求,这个动作都会先被ArbiterOS接管,转换为机器可读、可检查的请求,再交由治理内核审查。只有当该动作满足预先配置好的「数字契约」后,才会真正被放行。
这也是为什么 ArbiterOS 更适合被理解为 Agent Kernel / Agent OS 的雏形,而不只是一个外挂式的过滤网或安全组件。其核心在于向智能体领域首次引入了底层系统的黄金法则——「特权分离(Privilege Separation)」。
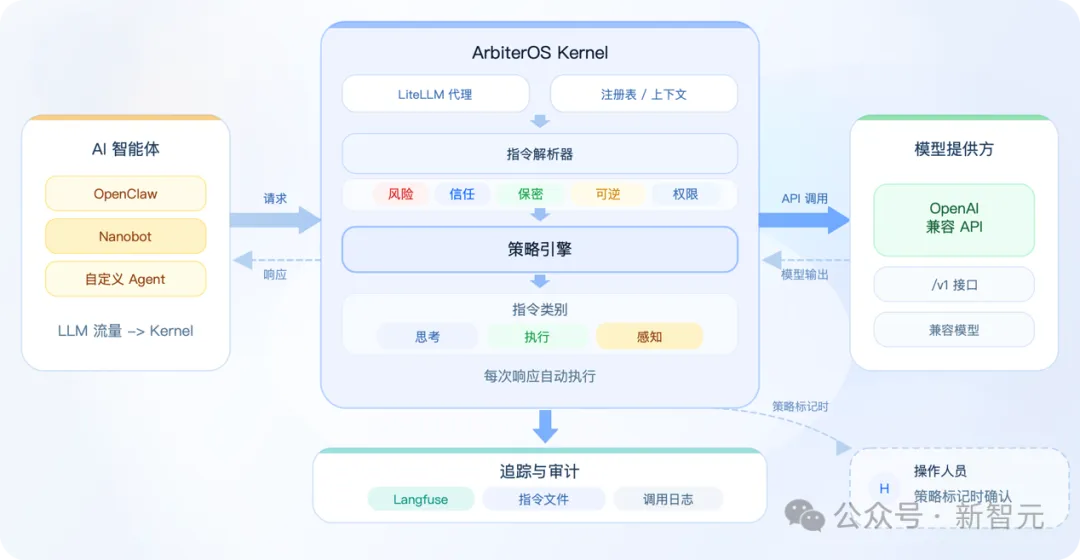
ArbiterOS 在物理架构上彻底剥夺了模型和上层应用的底层执行主权,把「想」和「做」进行了刚性切割。
它像一个系统层中间件那样,站在「智能决策」和「真实执行」之间:模型只负责思考和提出动作候选,而 ArbiterOS 作为唯一掌握物理接口的内核,负责冷酷地决定哪些动作在当前上下文中可以真正落地执行。
ArbiterOS 生态架构总览: AI 智能体 → 治理内核 → 模型提供方
从工程角度看,这种区别非常关键。它意味着 ArbiterOS 关心的不是「模型是不是说了一句看起来危险的话」,而是:
它准备做什么动作
这个动作对应的目标对象是什么
涉及的数据来自哪里
在当前的上下文中,这个动作是否应被允许执行
这使得智能体安全真正进入了动作级、状态级、数据流级的治理层。
从模型输出到动作治理
ArbiterOS的四步
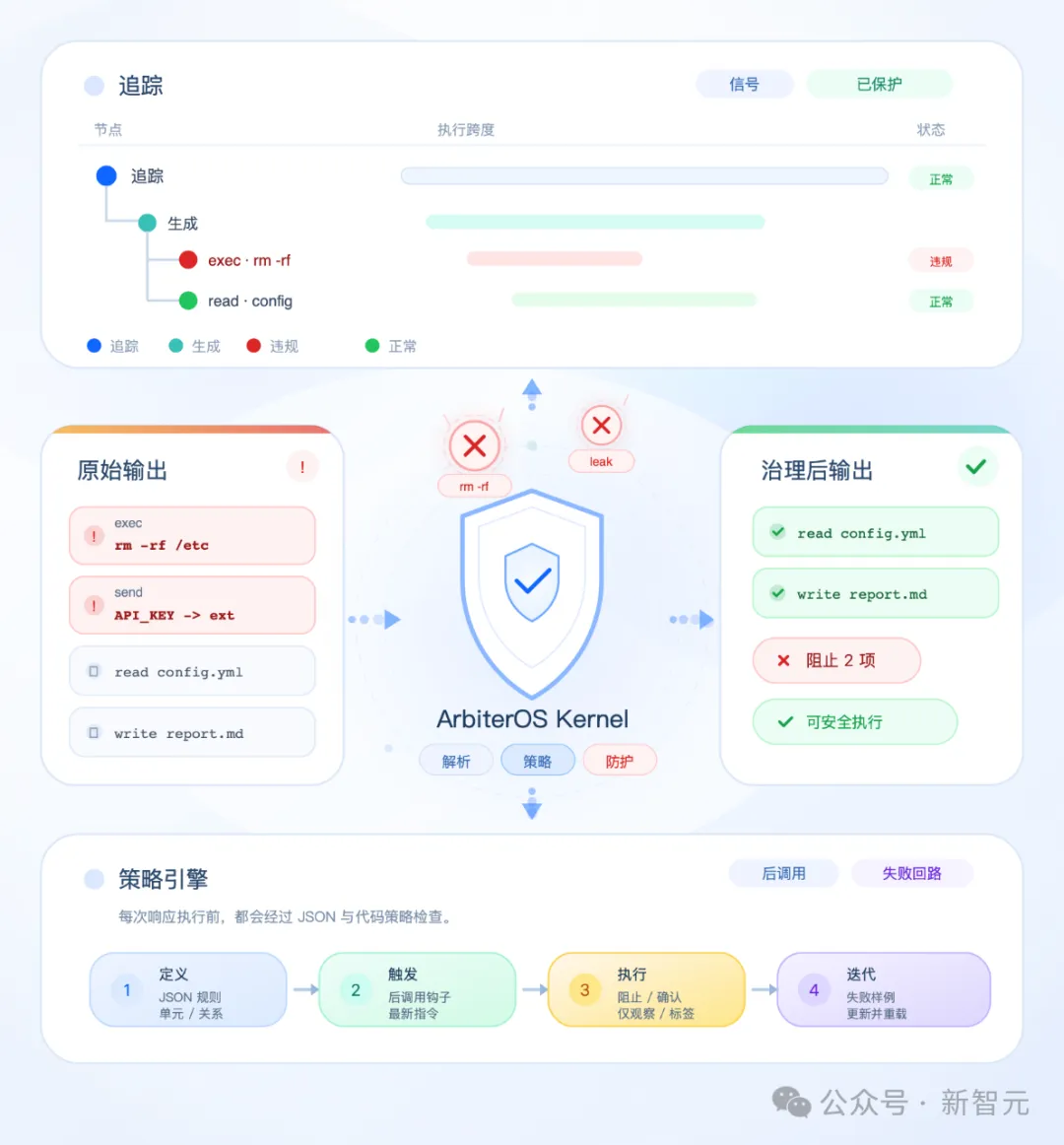
为了实现这种运行时治理,ArbiterOS 将整个流程规范化为四个阶段:拦截(Intercept)、解析(Parse)、治理(Govern)、观测(Observe)。这四步构成了 Agent 运行时最关键的治理闭环。
ArbiterOS四步治理流程: 从原始输出到治理后输出——拦截、解析、策略、观测的完整链路
1. 拦截:在动作执行前先接管
当 Agent 读完一份配置文件,接着准备向外部 API 发起请求时,ArbiterOS 的第一步不是判断它「语气危不危险」,而是先接管这个动作。这是整个系统成立的前提。因为在 Agent 场景里,许多高风险动作一旦发生就是瞬时且不可逆的:数据一旦外发,文件一旦删除,事后再分析日志、写事故报告,都已经太晚。真正的治理必须发生在动作执行之前,而不是事故发生之后。拦截解决的是第一个核心问题:不能让系统进入「先做了再说」的状态。