谷歌「AI联合数学家」来了量子位
数学界「悬案簿」Kourovka Notebook,AI 取得新突破。
群论领域几十年无解的第 21.10 号问题,被牛津数学家 Marc Lackenby 用谷歌一个新系统破解了。
过程也很有意思:AI 第一次给出的证明是错的,被系统里的审查 Agent 揪出了漏洞。
Lackenby 看到之后突然意识到:「等一下,我知道该如何填补这个漏洞」。
于是,通过和 AI 的反复配合,Lackenby 最终成功解答出了这道数学难题。
这套人机协作的系统,就是谷歌 DeepMind 最新发布的「AI Co-Mathematician」(AI 联合数学家)。
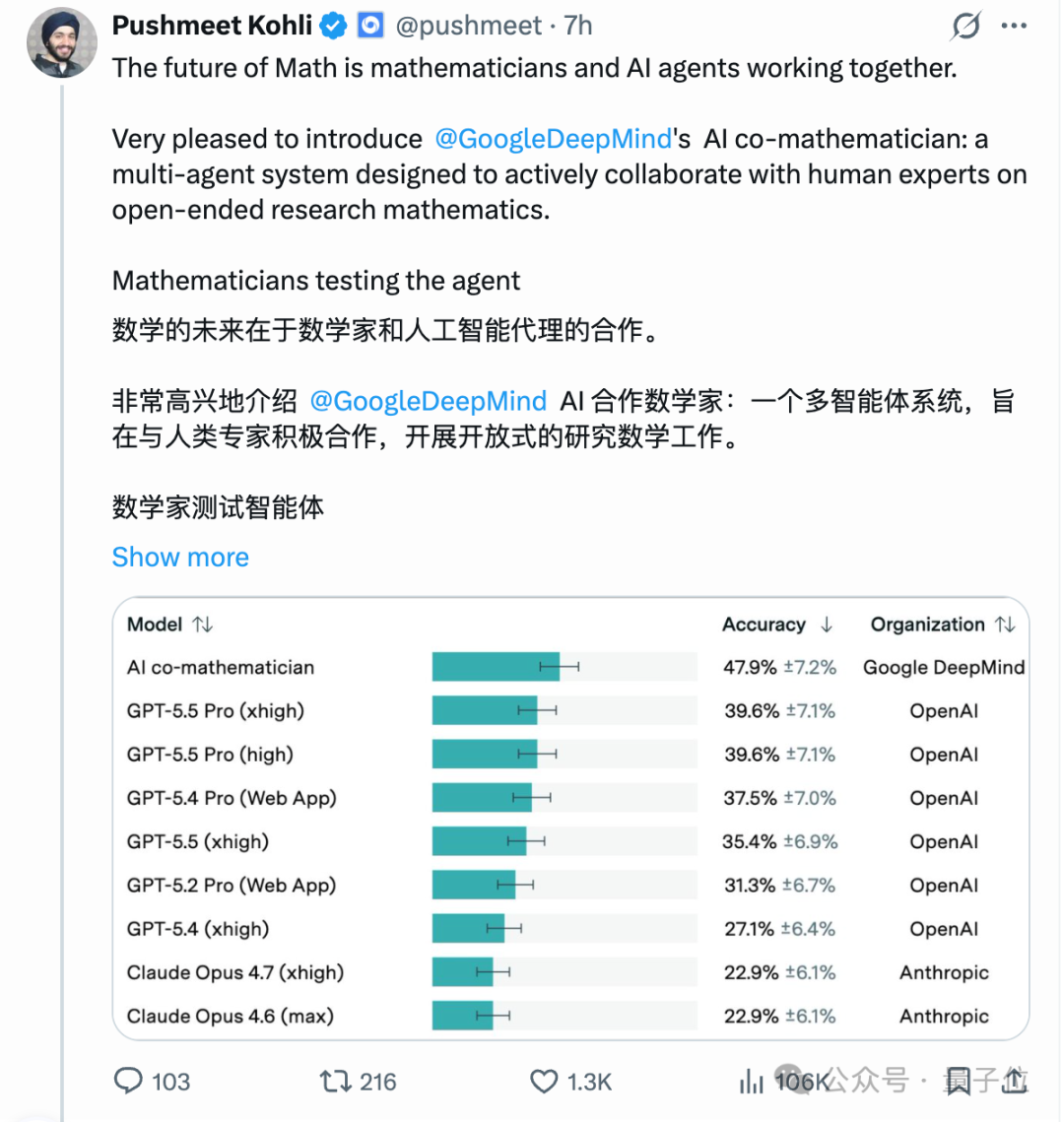
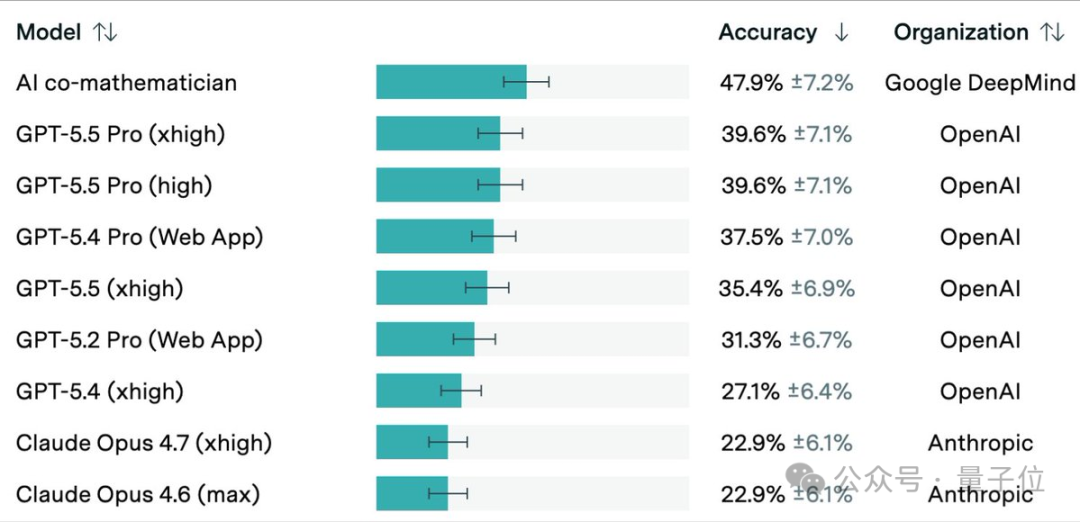
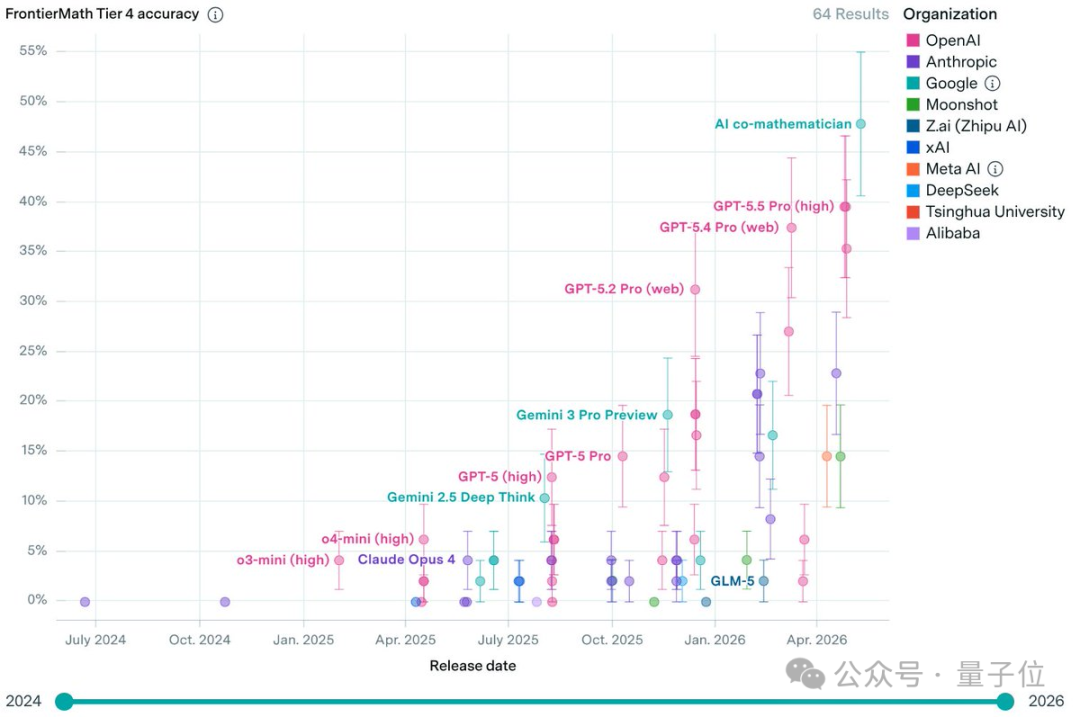
它在最难的数学 AI 基准 FrontierMath Tier 4 上拿了 48%,刷新 SOTA。
甚至超过了 GPT-5.5 Pro(39.6%)
和 GPT-5.4 Pro(37.5%)。
最近几个月,不少数学难题,诸如接连几个 Erdős 问题都是用 GPT 解决的。
现在,谷歌也回归了。
「AI 联合数学家」,是什么?
「AI 联合数学家」是一个
异步、有状态的工作空间,而非一问一答的模型。
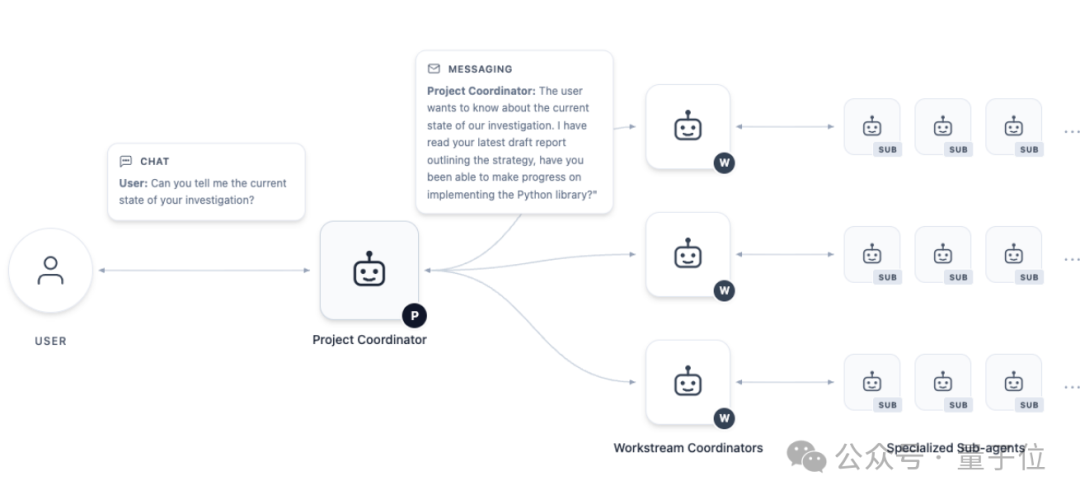
顶层有一个「项目协调者」Agent 负责统筹,拆解任务,调度多条研究线并行推进。
数学家上传一篇论文、提出一个研究方向后,协调者不会立刻输出答案,而是先和用户对话,像真正的合作者一样帮对方精炼问题。
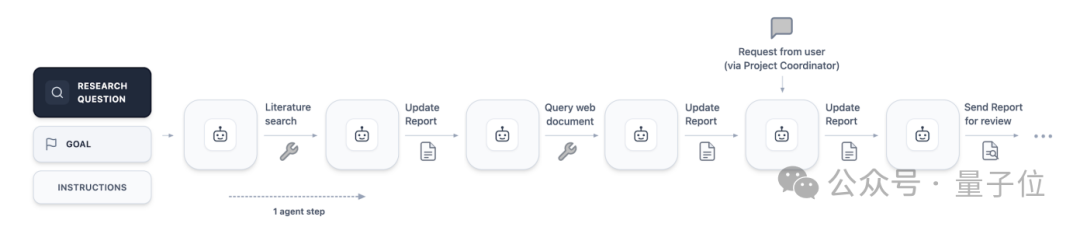
之后它将任务分发到多条并行工作流:一条做文献检索,一条搭计算框架,一条尝试证明策略。
每条工作流都有自己的协调 Agent,异步运行,互不阻塞。用户随时能介入、引导、接管。
如果 Agent 卡住了,它也会主动在聊天窗口里求助,而不是沉默重启。
比较特别的一点在于:它对失败的态度。
系统会持久化追踪所有失败的假说,不会丢弃,而是当作第一等的研究产出保存下来。
论文中提到,在数学研究里,
知道什么行不通往往和知道什么行得通同等重要。
「AI 联合数学家」会持久化追踪每一条死胡同、每一个被否定的假设、每一次审稿 Agent 发现的漏洞。这些「负空间」不会被丢弃,而是成为后续探索的上下文。
它的产出物也不是一段聊天记录或一篇未经验证的草稿,而是带 margin 注释和来源溯源的 LaTeX 文档 —— 完全契合数学家社群的工作习惯。
「AI 联合数学家」有什么意义?论文里有一段很精妙的比喻:
软件工程领域已经有了 Claude Code、Cursor 这类 AI 编码环境,它们提供了持续迭代、版本控制、测试验证的完整工作流。
但数学家此前一直缺少一个等价的编排层。
「AI 联合数学家」就是试图填补这个空白。
它的定位,与 DeepMind 上一代系统 AlphaEvolve 完全不同。
AlphaEvolve 更像一个自主搜索引擎:你把问题扔进去,它进化出一个更好的算法,人基本不在循环里。
而「AI 联合数学家」要求数学家始终在回路中,系统在最适合的时机向人类提问,而不是替人类做完整件事。
刷新最难数学 AI 基准 SOTA
在 benchmark 上,「AI 联合数学家」也拿下了出彩的成绩:
刷新了最难的数学 AI 基准 FrontierMath Tier 4 的 SOTA,拿了 48% 的准确率。
FrontierMath 是Epoch AI 开发的数学 benchmark,包含 350 道原创高难度题,覆盖现代数学各大分支。
其中 Tier 4 仅 50 题,被 Epoch AI 描述为「其中一些问题可能数十年内 AI 都无法攻克」,人类专家解决一道通常需要数天。
「AI 联合数学家」在 48 道非公开题中答对了 23 道,准确率 48%。
GPT-5.5 Pro 此前在 Tier 4 拿到 39.6%,GPT-5.4 Pro 是 37.5%,Claude Opus 4.6/4.7 则双双落在 22.9%。
相比之下,「AI 联合数学家」把最高分推了近 10 个百分点。
值得注意的是,它的底层基座模型 Gemini 3.1 Pro,单独做这个测试只拿到了 19%。