Anthropic联创定下deadline:2028机器之心
MLNLP社区是国内外知名的机器学习与自然语言处理社区,受众覆盖国内外NLP硕博生、高校老师以及企业研究人员。
社区的愿景是促进国内外自然语言处理,机器学习学术界、产业界和广大爱好者之间的交流和进步,特别是初学者同学们的进步。
AI 很快就能自己改造自己了?
Anthropic 联合创始人 Jack Clark 发帖称,他最近几周阅读了大量公开的 AI 开发数据后,认为到 2028 年底,递归自我改进(recursive self-improvement)发生的概率有 60%。
也就是说,AI 系统可能很快就能自主构建和改进自己,进入自我加速的阶段。
这一观点并非凭空而来。他看了一堆公开基准,发现 AI 在 AI 研发相关任务上进步非常快。
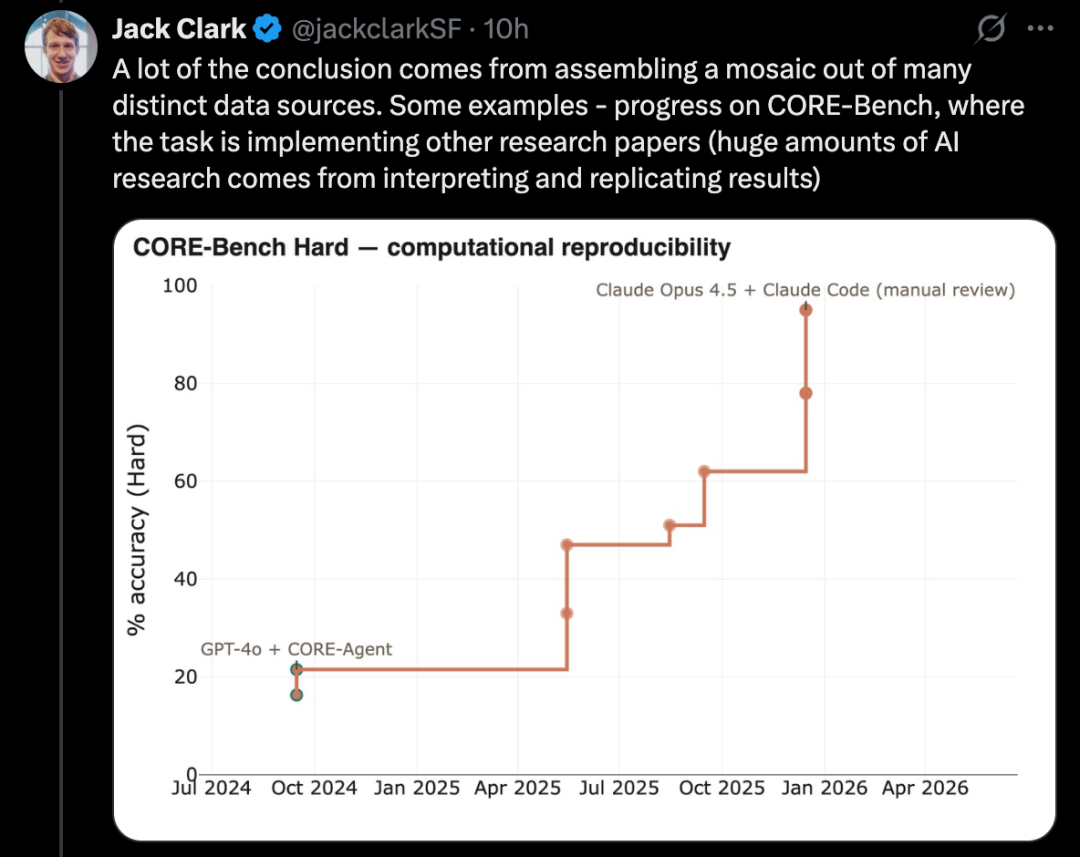
比如,CORE-Bench 考察 AI 实现他人研究论文的能力,这是 AI 研究中至关重要的一环。
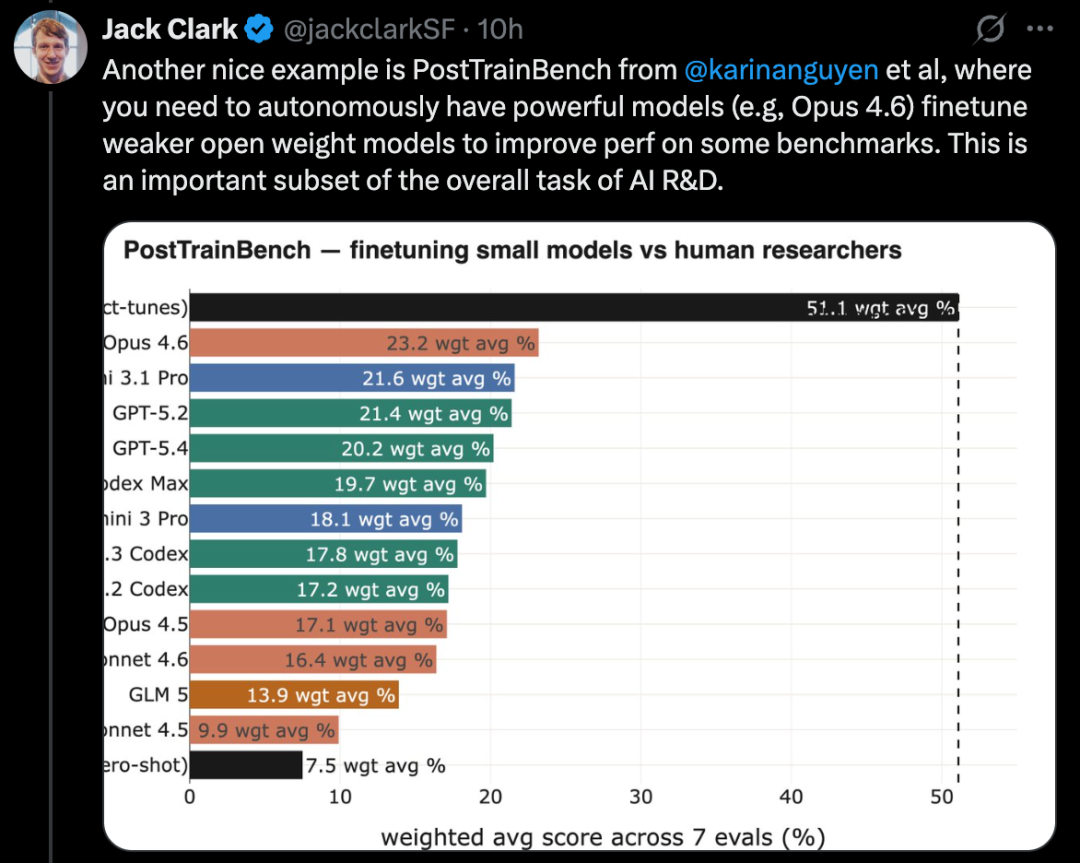
PostTrainBench 则测试强大模型能否自主微调较弱的开源模型以提升性能,这正是 AI 研发任务的一个关键子集。
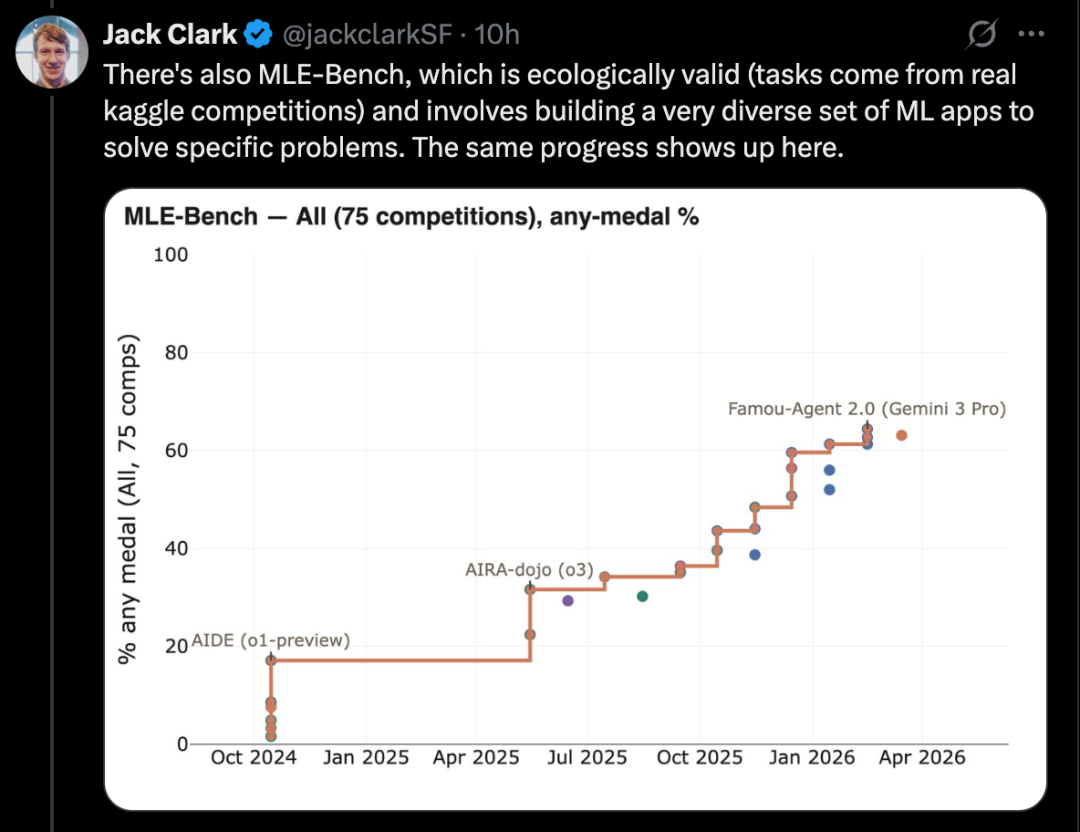
MLE-Bench 基于真实 Kaggle 竞赛任务,要求构建多样化的机器学习应用程序来解决特定问题。此外,像 SWE-Bench 这样广为人知的编码基准,也展现出类似的进步。
Jack Clark 将这一现象描述为「分形」式的向上向右趋势,即在不同分辨率和尺度上,都能观察到有意义的进展。他认为,AI 正在逐步接近端到端自动化研发的能力,一旦实现,AI 将能够自主构建自己的后继系统,开启自我迭代的循环。
此言论一出,在社交媒体引发不少讨论。
一些人视其为迈向 ASI 和奇点的关键第一步,可能彻底改变科技发展的节奏。
然而,也存在不同声音。
华盛顿大学计算机科学教授 Pedro Domingos 指出,AI 系统早在上世纪 50 年代 LISP 语言发明时就具备了「构建自身」的能力,真正的问题在于能否获得递增回报,而目前还没有明显证据支持这一点。
有网友质疑,从 2027 年到 2028 年,概率一下子增加 30%,这暗示 AI 能力会在 2027 年底前后出现一次突然的重大突破。到底哪一个具体的里程碑或事件,会让 AI 实现递归自我改进的概率在短时间内大幅提升?
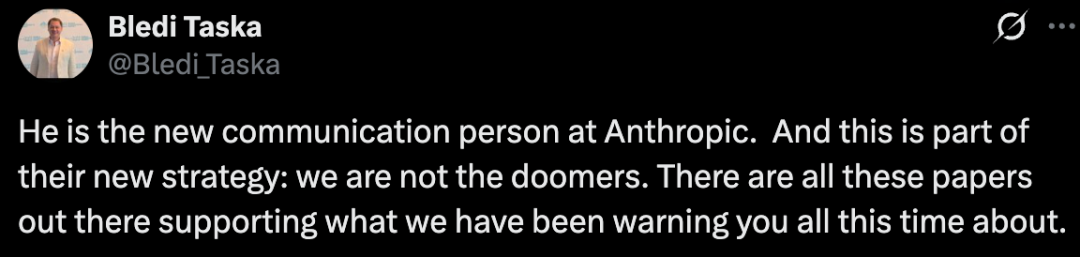
还有网友表示,Jack Clark 是 Anthropic 新上任的公关负责人,这正是他们新战略的一部分:我们并非危言耸听者,有大量的论文都印证了我们一直以来警告你们的事情。
Jack Clark 专门在 Import AI 455 这期 newsletter 里写了一篇长文详细阐述。
文章地址:https://importai.substack.com/p/import-ai-455-automating-ai-research?r=1ds20&utm_campaign=post&utm_medium=email&triedRedirect=true
AI 系统即将开始自我构建,这意味着什么?
Clark 表示,他写下这篇文章,是因为在梳理所有公开可获得的信息后,他不得不形成一个并不轻松的判断:到 2028 年底之前,出现无人类参与的 AI 研发的可能性已经相当高,或许超过 60%。
这里所谓的无人类参与的 AI 研发,指的是一种足够强大的 AI 系统:它不仅能辅助人类做研究,还可能自主完成关键研发流程,甚至构建出自己的下一代系统。
在 Clark 看来,这显然是一件大事。
他坦言,自己也很难完全消化这件事的含义。
之所以称这是一个不情愿的判断,是因为它背后的影响过于巨大,让他感到难以把握。Clark 也不确定,整个社会是否已经准备好迎接 AI 研发自动化所带来的深层变化。
他现在相信,人类可能正生活在一个特殊时间点:AI 研究即将被端到端自动化。如果这一刻真的到来,人类就像跨过了卢比孔河,进入一个几乎无法预测的未来。
Clark 表示,这篇文章的目的,是解释他为什么认为,通向完全自动化 AI 研发的起飞正在发生。
他会讨论这一趋势可能带来的一些后果,但文章的大部分篇幅,都会集中在支撑这一判断的证据上。至于更深层的影响,Clark 计划在今年的大部分时间里继续梳理。
从时间点来看,Clark 并不认为这件事会在 2026 年真正发生。但他认为,未来一两年内,我们可能会看到某种模型端到端训练出自己后继者的案例。至少在非前沿模型层面,出现一个概念验证是很有可能的;至于最前沿模型,难度会更高,因为它们成本极其昂贵,也依赖大量人类研究员的高强度工作。
Clark 的判断主要来自公开信息:包括 arXiv、bioRxiv 和 NBER 上的论文,以及前沿 AI 公司已经部署到现实世界中的产品。基于这些信息,他得出一个结论:自动化生产当下 AI 系统所需的各个环节,尤其是 AI 开发中的工程组件,基本已经具备。
如果 scaling 趋势继续延续,我们就应该开始准备面对这样一种情况:模型会变得足够有创造力,不仅能自动改进已知方法,还可能在提出全新研究方向和原创想法方面替代人类研究员,从而自行推动 AI 前沿继续向前发展。
编码奇点:能力随时间的变化
AI 系统是通过软件实现的,而软件由代码构成。
AI 系统已经彻底改变了代码生产方式。这背后有两个相关趋势:一方面,AI 系统越来越擅长编写复杂的真实世界代码;另一方面,AI 系统也越来越擅长在几乎不依赖人类监督的情况下,把许多线性的编码任务串联起来完成,比如先写代码,再进行测试。
体现这一趋势的两个典型例子,是 SWE-Bench 和 METR time horizons plot。
解决真实世界的软件工程问题
SWE-Bench 是一个被广泛使用的编程测试,用来评估 AI 系统解决真实 GitHub issue 的能力。
当 SWE-Bench 在 2023 年底推出时,当时表现最好的模型是 Claude 2,整体成功率大约只有 2%。而 Claude Mythos Preview 的成绩已经达到 93.9%,基本上接近打满这个 benchmark。
当然,所有 benchmark 本身都会有一定噪声,所以通常会出现这样一个阶段:当分数高到某个程度之后,你碰到的可能不再是方法本身的限制,而是 benchmark 自身的限制。比如在 ImageNet 验证集中,大约 6% 的标签就是错误或存在歧义的。