刚刚,国产AI双冠王新智元
世界模型黑马横空出世!就在刚刚,生数科技的MotuBrain零宣发登顶双榜,直接打通「看懂世界+执行行动」,而且不同的是,他们把World Action Model适配多个头部机器人本体,完成多个长程任务,这是国产AI的硬核突围!从此,具身智能彻底迈入新纪元。
就在刚刚,世界模型圈又闯出一匹黑马!
悄无声息地,它就拿下了两个世界第一。
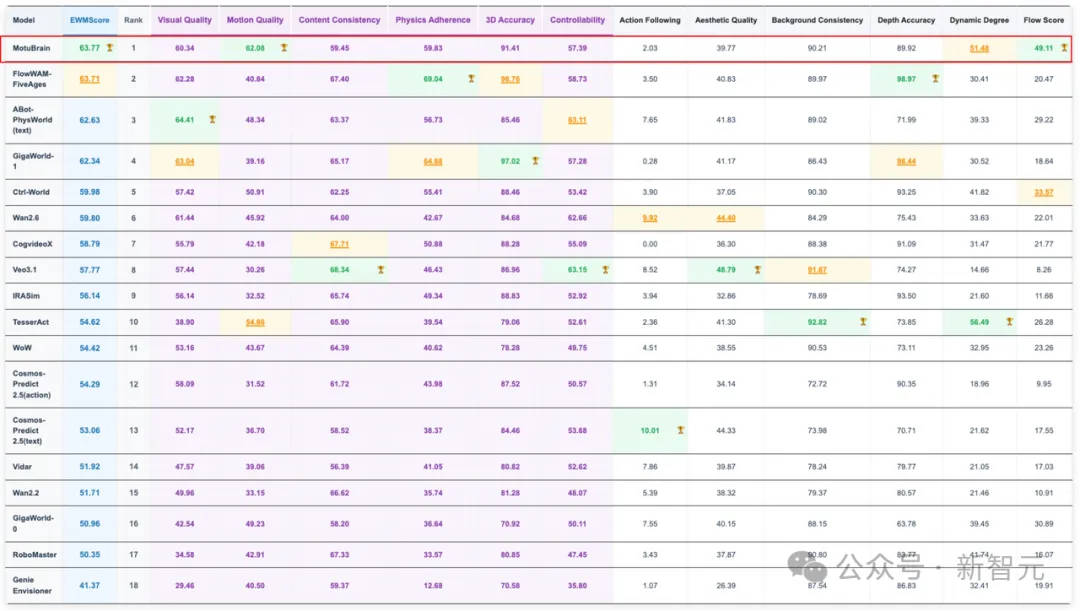
在WorldArena中,总体EWM Score达到63.77,排名第一(截至本月中旬左右)。
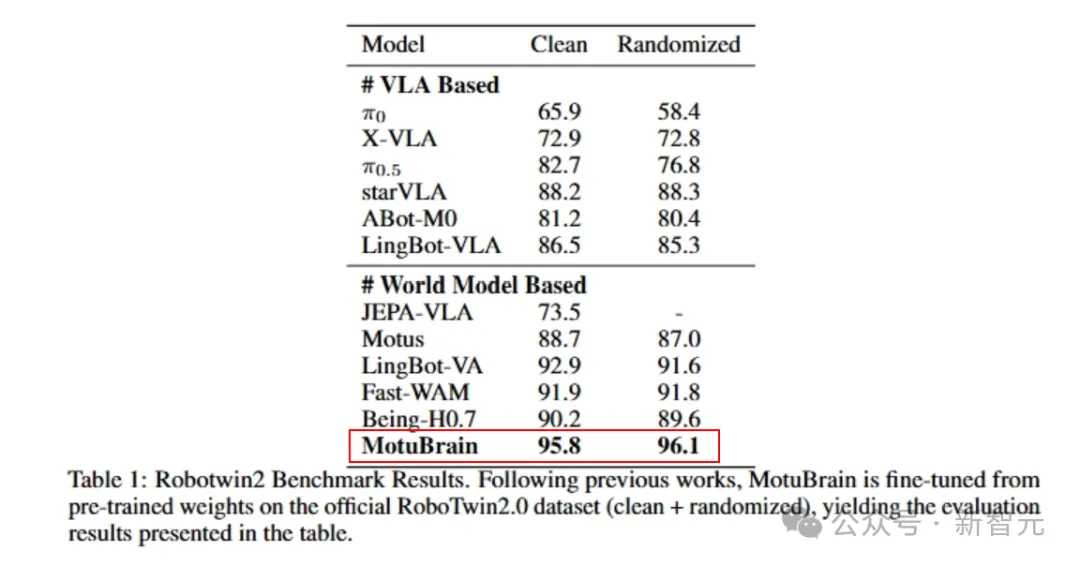
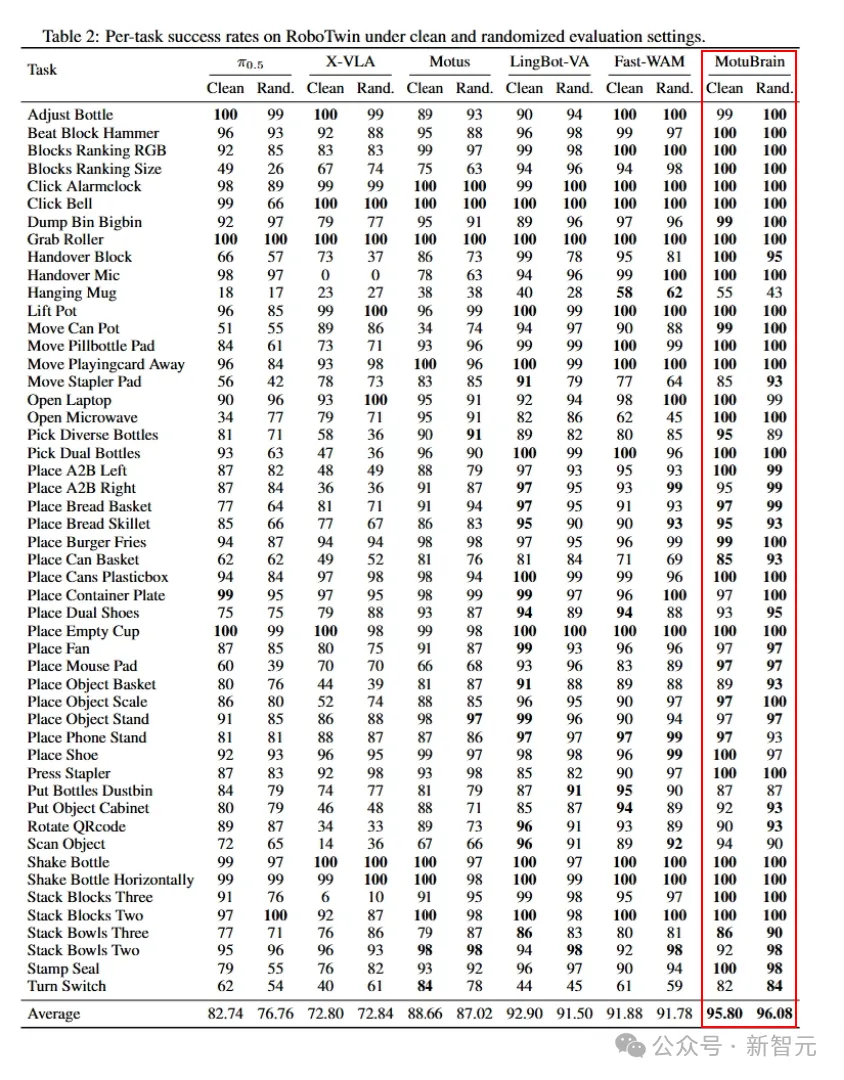
在RoboTwin2.0的Clean和Randomized两个场景下,它分别拿下了95.8和96.1,同样排名第一。
而且,它是百分百的零宣发。
这些荣誉,属于同一个模型——MotuBrain。
它出现得极其反常:没有Logo、没有发布会、没有融资稿,连X账号都是新注册的。
就这么一声不响地,同时爬上了两个国际权威榜单的顶端。
更离谱的是,这两个榜单彼此根本不挨着——一个考「你能不能真正看懂世界」,一个考「你能不能在世界里稳定干活」。
过去几年,行业把它们叫作「两个极点」:做世界模型的看得懂、动不了;做VLA的能动手、想不远。
同时拿下两个第一,业内前所未有。
具身圈猜测刷屏:这是阿里「快乐生蚝」翻版?字节憋的大招?或者华为的暗手?还是李飞飞World Labs的中国分舵?
直到谜底揭开,所有人都没想到——国产生成式AI公司生数科技。
而且他们没有止步与此,现在已经把world action model适配多个头部机器人本体,应对多种任务、建模多个长程任务。
这是工业级的demo,和其他的刷榜模型绝对不一样。
神秘面纱揭开
国产AI领先硅谷巨头
事情得从去年12月说起。
那时候,生数科技联合清华大学开源了一款叫Motus的大一统世界模型。
论文链接:https://arxiv.org/abs/2512.13030
项目主页:https://motus-robotics.github.io/motus
Motubrain官网:https://www.shengshu.com/zh/motubrain
才刚刚发布,Motus就已经在圈内小小震动了一下。
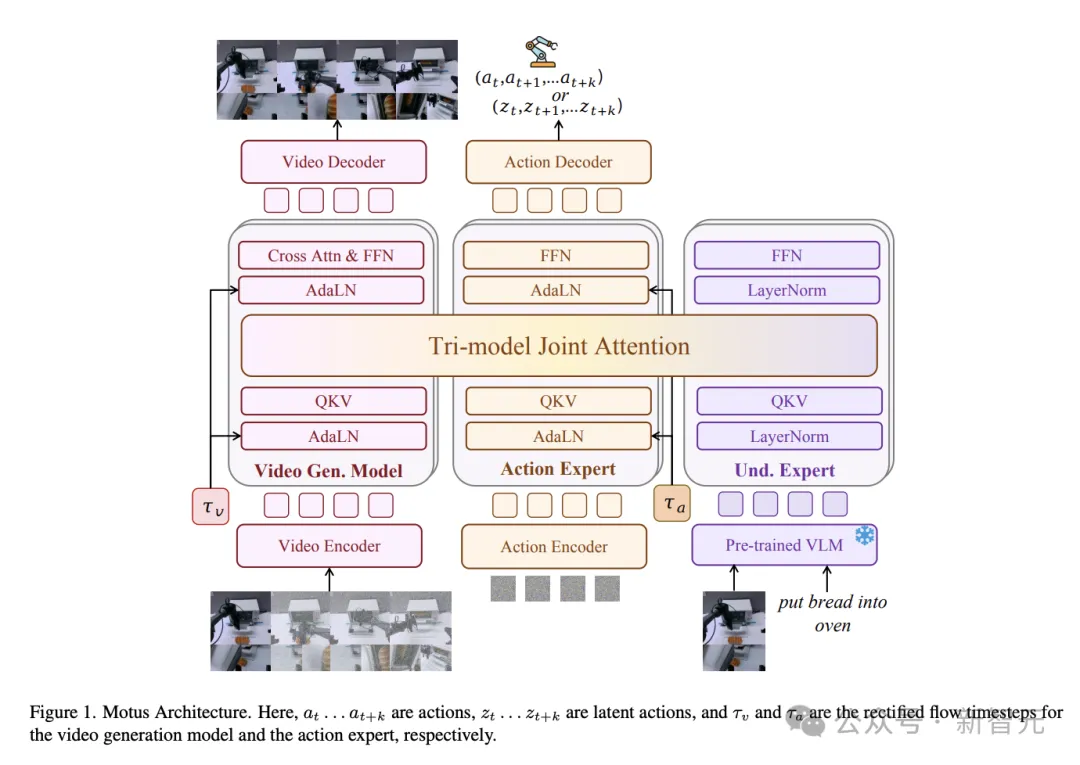
因为它在架构上把五种本来彼此割裂的具身智能范式,拧成了一个「看-想-动」的闭环:
VLA(视觉-语言-动作)、世界模型、视频生成、逆动力学、视频-动作联合预测。
这种统一世界-动作建模,通过一个模型统一建模视频「video」与动作「action」,使之前彼此割裂的5种方法都成为同一建模框架下的不同推理模式。
与以往方法不同,Motus联合建模「视频」和「动作」,学到的不再是机械反应,而是任务目标、环境变化、以及动作会带来什么后果这三者之间的深层世界知识。这让它更能适应新环境和新任务。
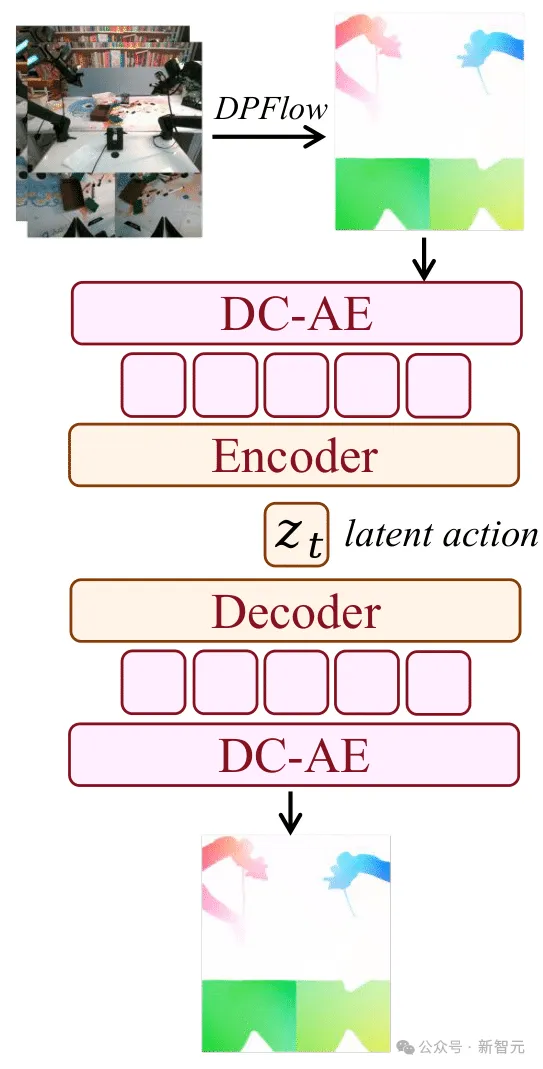
Motus引入「潜动作」机制,能从无标签的互联网视频、人类操作视频中提取通用的「运动规律」。
潜动作变分自编码器 (Latent Action VAE)。 这是一种基于光流的表征方式,通过变分自编码器架构将视觉动力学(visual dynamics)与控制信号相衔接
这让它可以利用近乎无限的海量数据来预训练,极大丰富了先验知识。
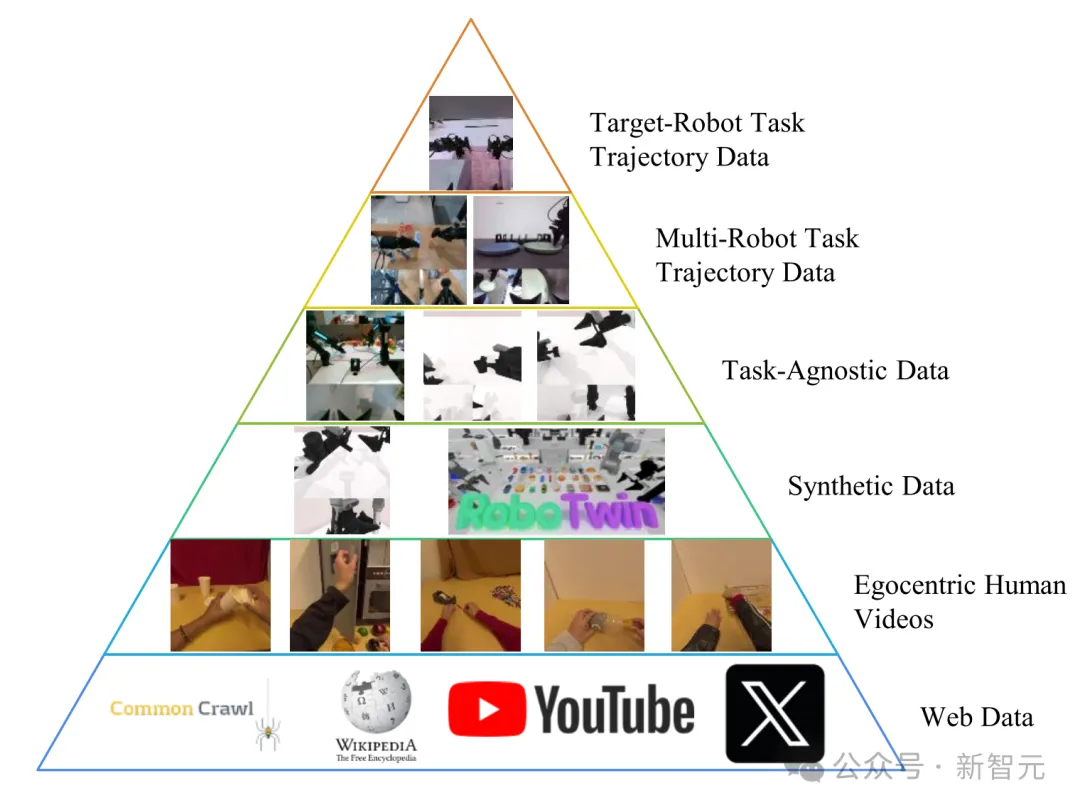
具身数据金字塔。 展示了从互联网数据(第一层)到目标机器人演示数据(第六层)的六级数据层级结构,其任务相关性和数据质量随层级逐级提升。
基于「专家混合」,Motus引入了混合Transformer (Mixture-of-Transformer, MoT) 架构,巧妙融合了视频生成、语义理解、动作生成三个已有的高性能基座模型。
这相当于让模型同时拥有了「想象力」、「理解力」和「执行力」。
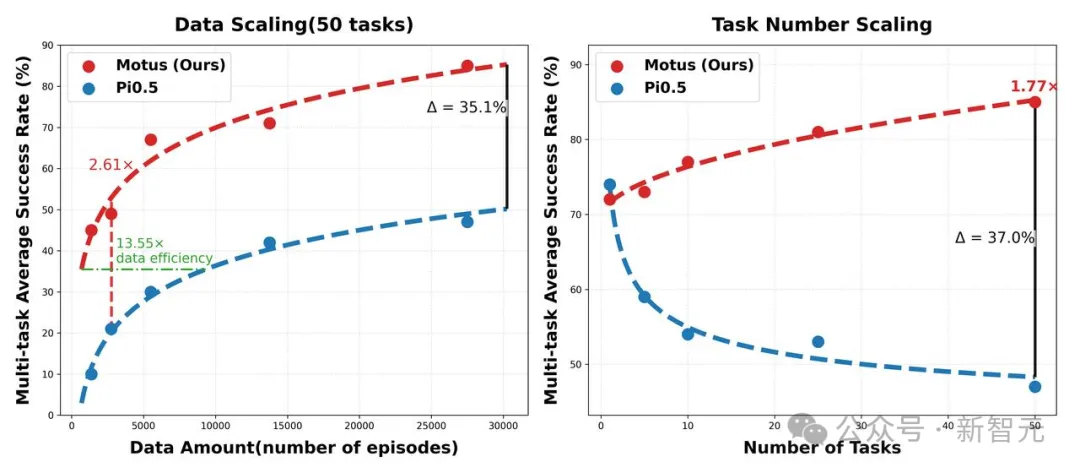
Motus表现出了正向的规模效应,即学习的任务越多、数据越丰富,模型掌握的可迁移世界知识就越多,在新任务上的平均成功率反而越高。
这是它学到了通用规律而非死记硬背的有力证据。