OpenAI发布GPT-5.5:全面超越Claude与Gemini
GPT-5.5在编程、科研与知识工作领域测试中全面超越Claude和Gemini,且以与前代相当的推理延迟实现更高智能。工程师实测直言"像在与更高层次智慧生物协作"。GPT-5.5周四面向ChatGPT及编程工具Codex的付费用户开放。
OpenAI推出迄今最强大模型GPT-5.5,在代码编写、科学研究及知识工作领域实现跨越式提升,同时以与前代模型相当的推理延迟实现更高智能水平,标志着AI从问答工具向自主完成复杂计算机任务的代理系统全面演进。
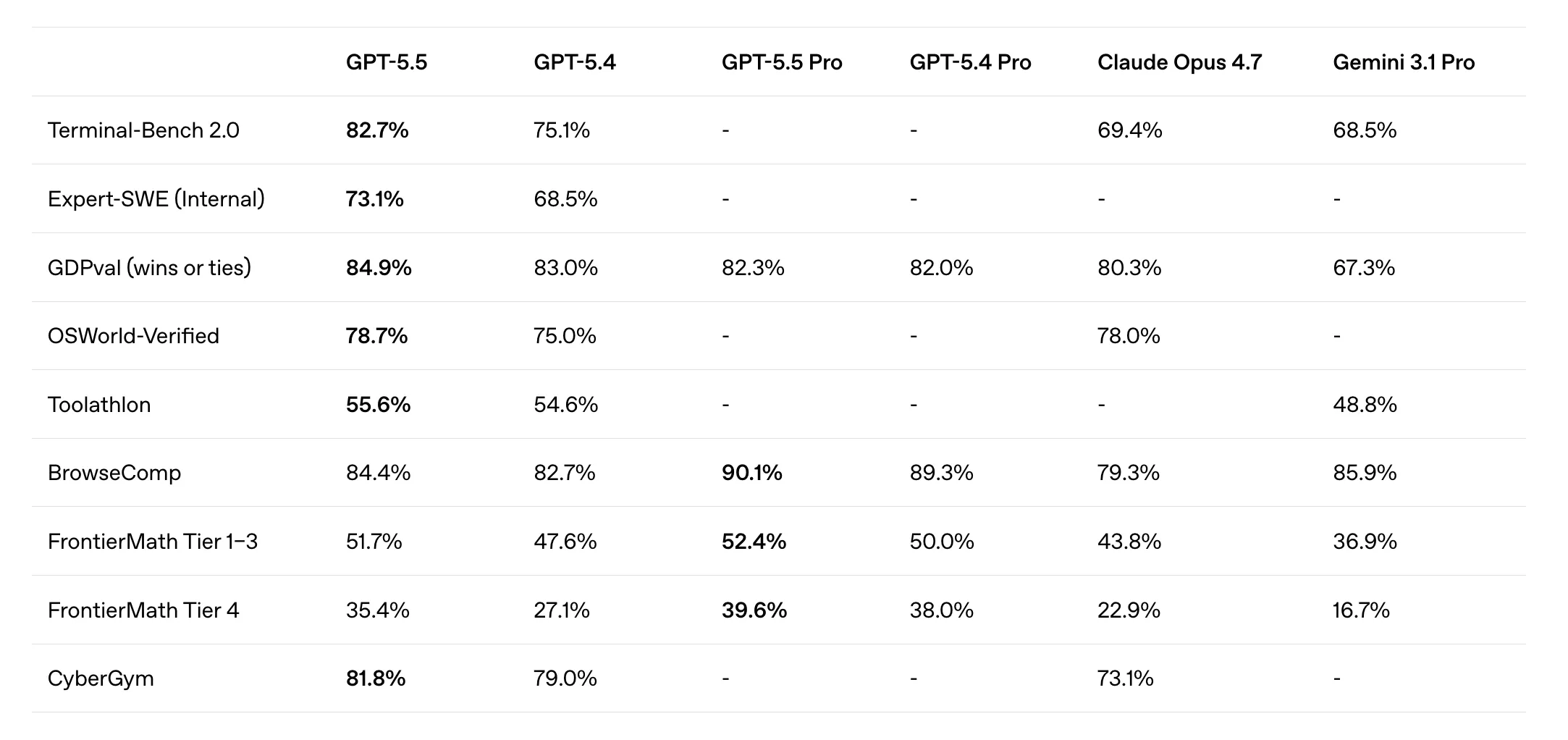
在模型能力上,GPT-5.5在Terminal-Bench 2.0编程测试、在衡量代理操控真实计算机环境的OSWorld-Verified基准和测试跨44种职业知识工作能力的GDPval基准等多重测试中均领先于Claude Opus 4.7及Gemini 3.1 Pro。
GPT-5.5即日起向ChatGPT的Plus、Pro、Business及Enterprise用户开放,Codex平台同步推出。API定价方面,OpenAI表示,尽管GPT-5.5定价高于前代,但其更高的token效率使综合使用成本具备竞争力。
OpenAI联创兼总裁Greg Brockman表示,该模型能够在指令有限的情况下自主处理任务,可调用邮件、表格、日历等应用程序执行用户命令。"它会自行想办法解决,应对模糊情境,"他说,"这是一种更直觉化的体验。"
MagicPath CEO Pietro Schirano指出,GPT-5.5在约20分钟内一次性完成了一次涵盖数百项前端改动与重构更改的分支合并任务。其直言:“感觉就像是在和更高层次的智慧生物一起工作,甚至会产生一种敬畏之情。”
性能飞跃:更高智能,同等延迟
GPT-5.5的核心技术突破在于打破了"更强即更慢"的模型规律。OpenAI表示,GPT-5.5在实际服务环境中实现了与GPT-5.4相当的延迟,同时在多项基准测试中大幅领先前代。
在代理编程领域:
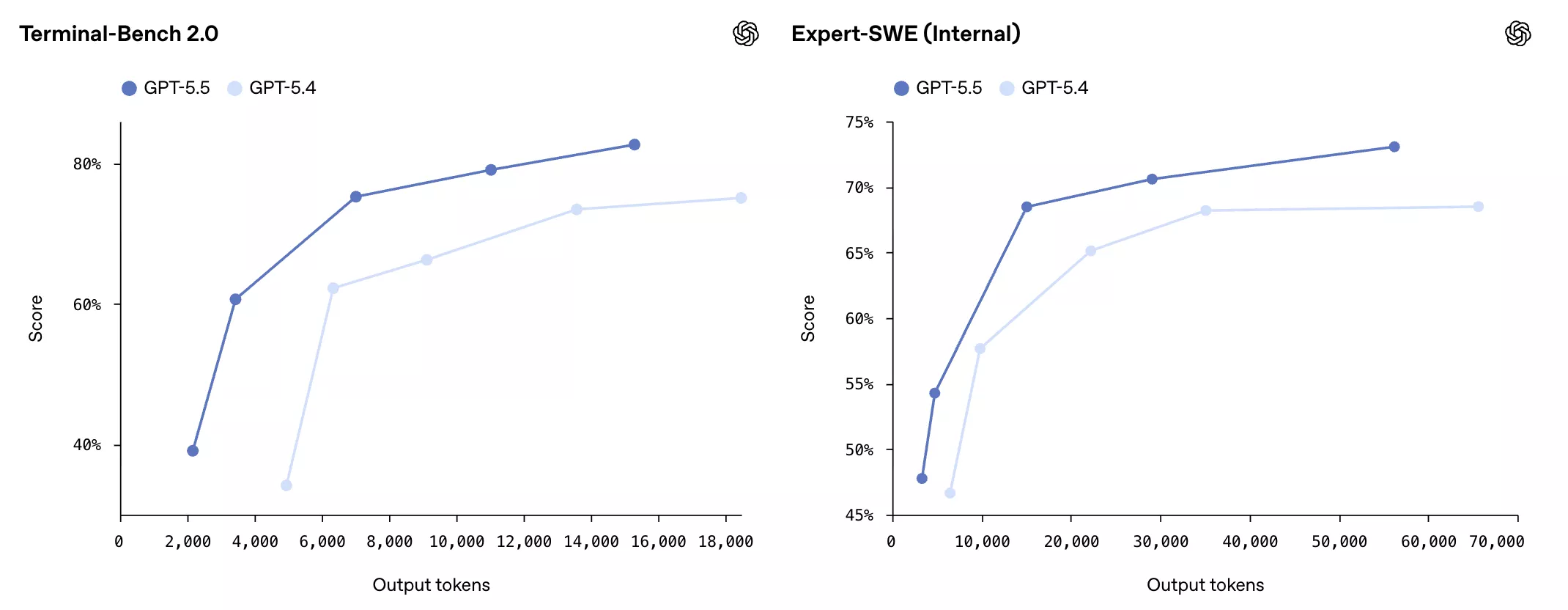
GPT-5.5在Terminal-Bench 2.0上得分82.7%,较GPT-5.4的75.1%提升显著;在测试真实GitHub问题解决能力的SWE-Bench Pro上达到58.6%;在内部长周期编程任务基准Expert-SWE(任务中位完成时间约20小时)上同样超越GPT-5.4。
值得关注的是,GPT-5.5在上述三项测试中均以更少的token消耗实现了更高得分。
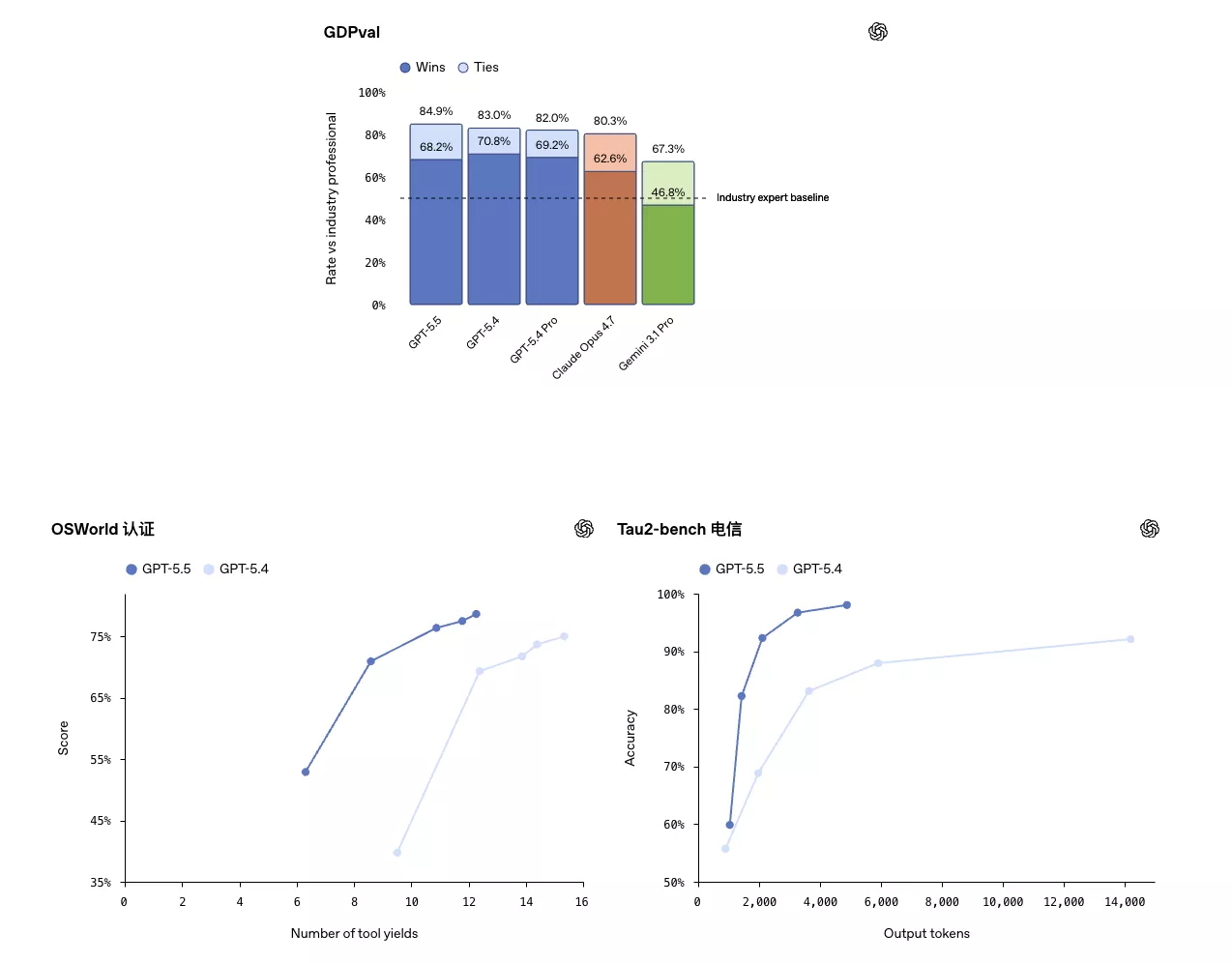
在计算机使用方面,GPT-5.5在OSWorld-Verified测试中以78.7%的成绩领先Claude Opus 4.7的78.0%。在工具调用测试Tau2-bench Telecom中,GPT-5.5在无提示词调优的条件下达到98.0%,而GPT-5.4仅为92.8%。
根据外部评估机构Artificial Analysis的编程综合指数,GPT-5.5以约为竞争前沿编程模型一半的成本实现了同等水平的智能表现。
工程实测:开发者体验的质变
多位企业技术负责人的实测反馈显示,GPT-5.5在实际工程场景中带来的提升超出基准数字所能体现的范围。
Every公司创始人兼CEO Dan Shipper描述了一项测试:在一次上线后排查数天未果的问题上,他用GPT-5.5重演故障状态,模型生成的修复方案与其顶级工程师后来做出的系统重构决策高度吻合,而GPT-5.4未能做到。
Shipper称GPT-5.5为"我用过的第一个具有真正概念清晰度的编程模型"。
MagicPath CEO Pietro Schirano指出,GPT-5.5在约20分钟内一次性完成了一次涵盖数百项前端改动与重构更改的分支合并任务。其直言:
“感觉就像是在和更高层次的智慧生物一起工作,甚至会产生一种敬畏之情。”
Lovable联合创始人兼CTO Fabian Hedin表示,身份验证流程、实时同步及多文件编辑等过去需要多轮尝试的任务,现在可以"一次命中"。
NVIDIA一名提前获得访问权限的工程师表示,"失去GPT-5.5的访问权限,感觉就像被截去了一条肢体。"
知识工作:从辅助工具到全流程代理
OpenAI将GPT-5.5的应用场景从编程扩展至更广泛的知识工作领域,并以自身内部实践作为佐证。
据OpenAI披露,目前超过85%的公司员工每周使用Codex,覆盖软件工程、财务、传播、市场、数据科学及产品管理等部门。
财务团队借助Codex审查了共24,771份、合计71,637页的K-1税务表格,相较上一年度提前两周完成任务;传播团队利用GPT-5.5构建了一套演讲请求评分与风险框架,实现了低风险请求的自动化处理。
GPT-5.5在多个反映此类工作的基准测试中均达到了最先进的性能。在GDPval 测试中,该测试旨在检验智能体在44个职业领域中生成明确知识型工作的能力,GPT-5.5 的得分为 84.9%。
在OSWorld-Verified 测试中,该测试旨在衡量模型能否独立运行在真实的计算机环境中,其得分为 78.7%。在Tau2-bench Telecom测试中,该测试旨在检验复杂的客户服务工作流程,其得分在未进行任何快速调优的情况下达到了 98.0%。
NVIDIA企业AI副总裁Justin Boitano表示,GPT-5.5帮助工程团队将调试时间从数天压缩至数小时,并将数周的实验进程压缩至一夜完成,"这不仅是更快的编程,而是一种帮助人们以根本不同速度工作的新方式"。
科研突破:从工具到"联合科学家"
在科学研究领域,GPT-5.5在多项生物与数学基准上表现出显著进步,OpenAI将其定位为能够实质性加速生物医学前沿研究的"联合科学家"。
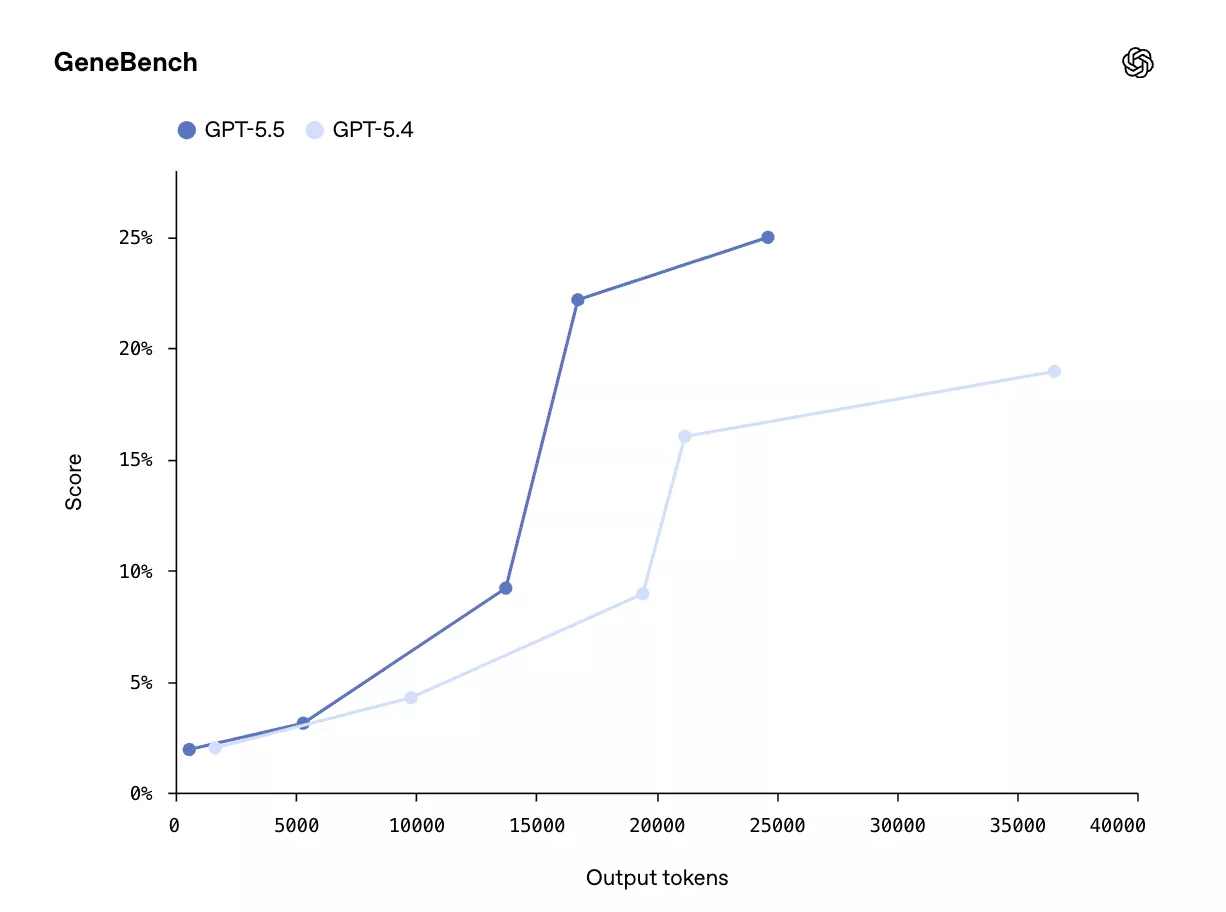
在专注于遗传学与定量生物学多阶段数据分析的GeneBench测试中,GPT-5.5得分25.0%,高于GPT-5.4的19.0%;GPT-5.5 Pro版本进一步达到33.2%。
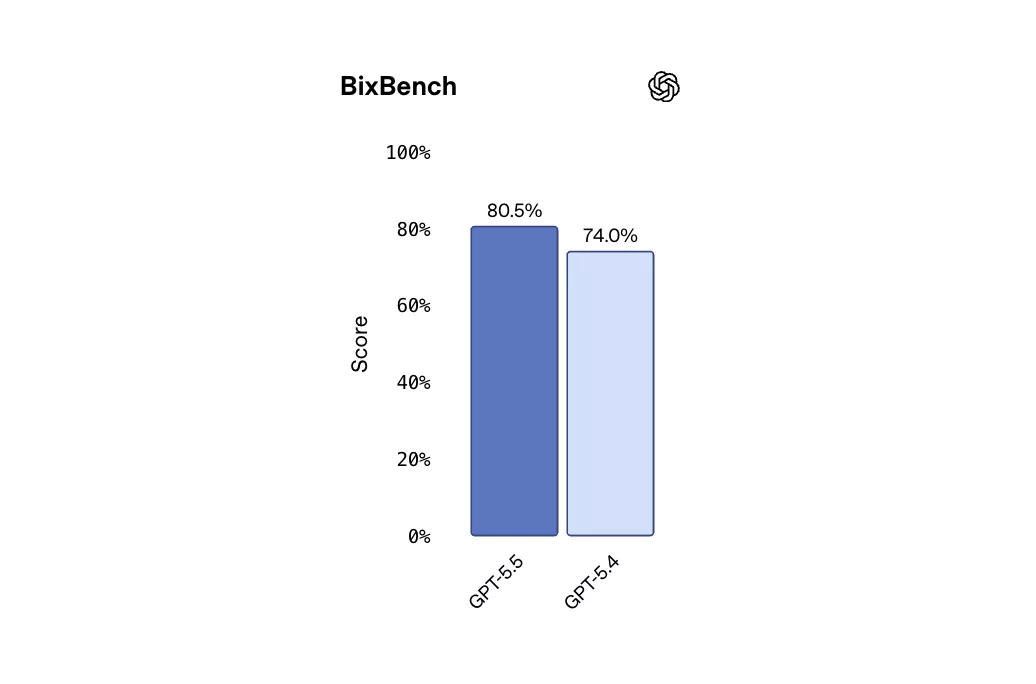
在生物信息学基准BixBench上,GPT-5.5以80.5%的成绩在已公布成绩的模型中排名领先,GPT-5.4为74.0%。
Jackson实验室免疫学教授Derya Unutmaz使用GPT-5.5 Pro分析了一组包含62个样本、近28,000个基因的基因表达数据集,生成了详尽的研究报告,涵盖关键发现及新兴洞察,他表示这项工作原本需要团队数月时间完成。
在数学领域,OpenAI披露,搭配自定义运行框架的GPT-5.5内部版本协助发现了一项关于非对角Ramsey数渐近性质的新证明,该结论随后在Lean系统中获得验证。
OpenAI称,这是模型在核心研究领域贡献"出人意料且有实际价值的数学论证"的具体案例,而非仅停留于代码生成或解释层面。
安全机制:网络安全能力列"高级",同步收紧访问限制
随着模型能力提升,OpenAI对GPT-5.5的安全框架亦进行了相应升级,并在网络安全与生物/化学两个领域将该模型的能力评级列为"高级"(High)。
OpenAI表示,在GPT-5.2首次引入网络安全专项防护措施的基础上,GPT-5.5进一步部署了针对高风险活动的更严格分类器及重复滥用保护机制,部分用户初期可能会遇到较多的访问限制。
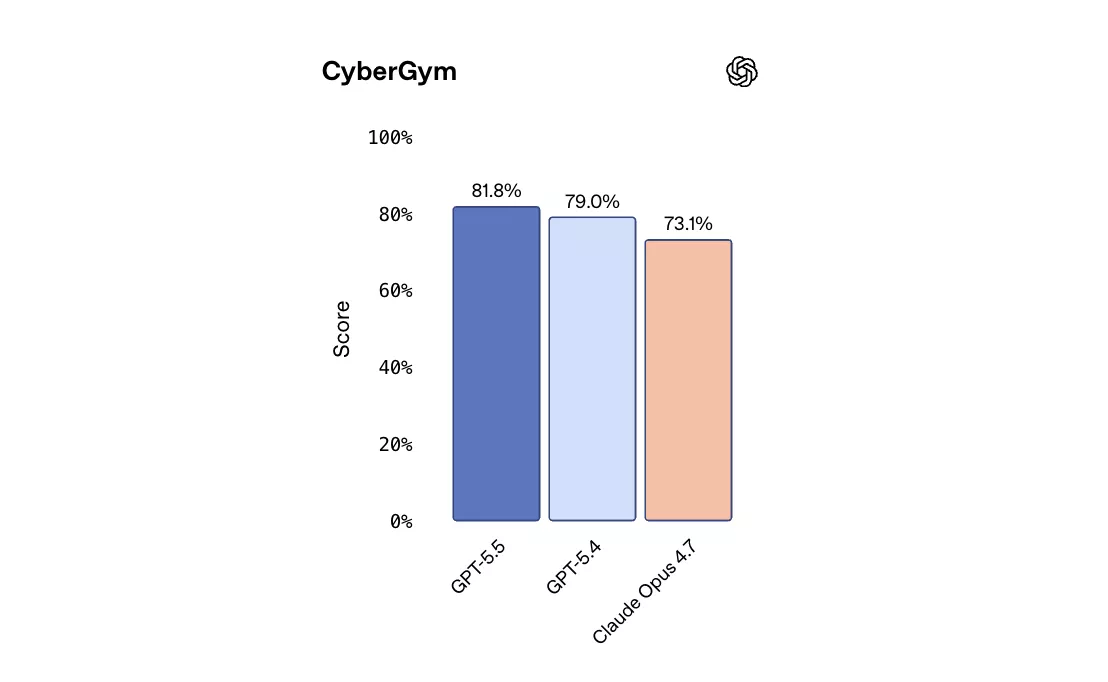
在网络安全基准CyberGym上,GPT-5.5得分81.8%,高于GPT-5.4的79.0%及Claude Opus 4.7的73.1%。
与此同时,OpenAI推出"网络安全可信访问"(Trusted Access for Cyber)计划,为通过特定信任条件验证的用户提供网络安全功能的扩展访问权限,并允许负责关键基础设施防护的机构申请使用GPT-5.4-Cyber等模型。
OpenAI表示,该公司正与政府合作伙伴探讨如何利用先进AI支持纳税人数据保护、电网及供水系统等关键基础设施的网络防御工作。
定价与可用性:API接口"即将"开放
在商业落地安排上,GPT-5.5目前通过ChatGPT和Codex分阶段向不同用户层级开放,API接口尚未全面就绪。
在ChatGPT中,GPT-5.5 Thinking面向Plus、Pro、Business及Enterprise用户开放;GPT-5.5 Pro面向Pro、Business及Enterprise用户开放。
在Codex平台,GPT-5.5面向Plus、Pro、Business、Enterprise、Edu及Go计划用户提供,上下文窗口为40万tokens,并提供速度提升1.5倍、成本为标准价2.5倍的Fast模式。
API定价方面,标准版gpt-5.5定价为每百万输入tokens5美元、每百万输出tokens30美元,上下文窗口为100万tokens;批量处理及弹性定价享半价优惠,优先处理定价为标准价格的2.5倍。
专业版gpt-5.5-pro定价为每百万输入tokens30美元、每百万输出tokens180美元。OpenAI表示,API接口将"很快"上线。