中国开源占领硅谷,连Yann LeCun也点赞量子位
嚯,硅谷居然被中国开源模型占领了!
连Yann LeCun也点赞:说得对!
初代AI编程炸子鸡Cursor和Devin,都被曝出号称自研的模型,其实套壳的就是中国开源模型。
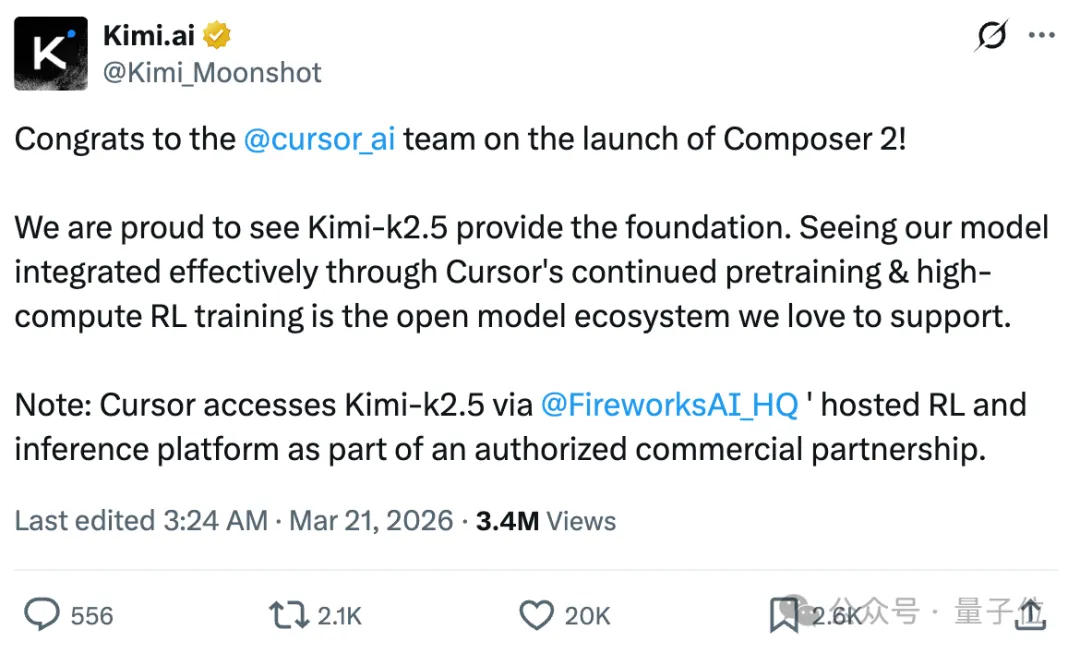
上个月,Cursor承认了旗下的Composer 2套壳Kimi K2.5。
当初首个推出“AI自动工程师”Devin的公司Cognition,其自研模型SWE-1.6,则疑似在GLM模型上进行后训练。
其实不止这两家,类似的例子越来越多,中国开源模型在硅谷的受欢迎程度与日俱增——
Shopify因切换至Qwen,每年节省500万美元;爱彼迎联创Brian Chesky也曾表示:Qwen又好又快又便宜,比GPT还好用!
而且智谱最新发布的GLM-5.1,是部分指标超Opus 4.6的开源模型,估计性价比放在硅谷也相当有竞争力了。
国产开源模型横扫硅谷
国外模型选择蒸馏中国开源模型,或是在此基础上进行后训练,这事儿已经不少见了。
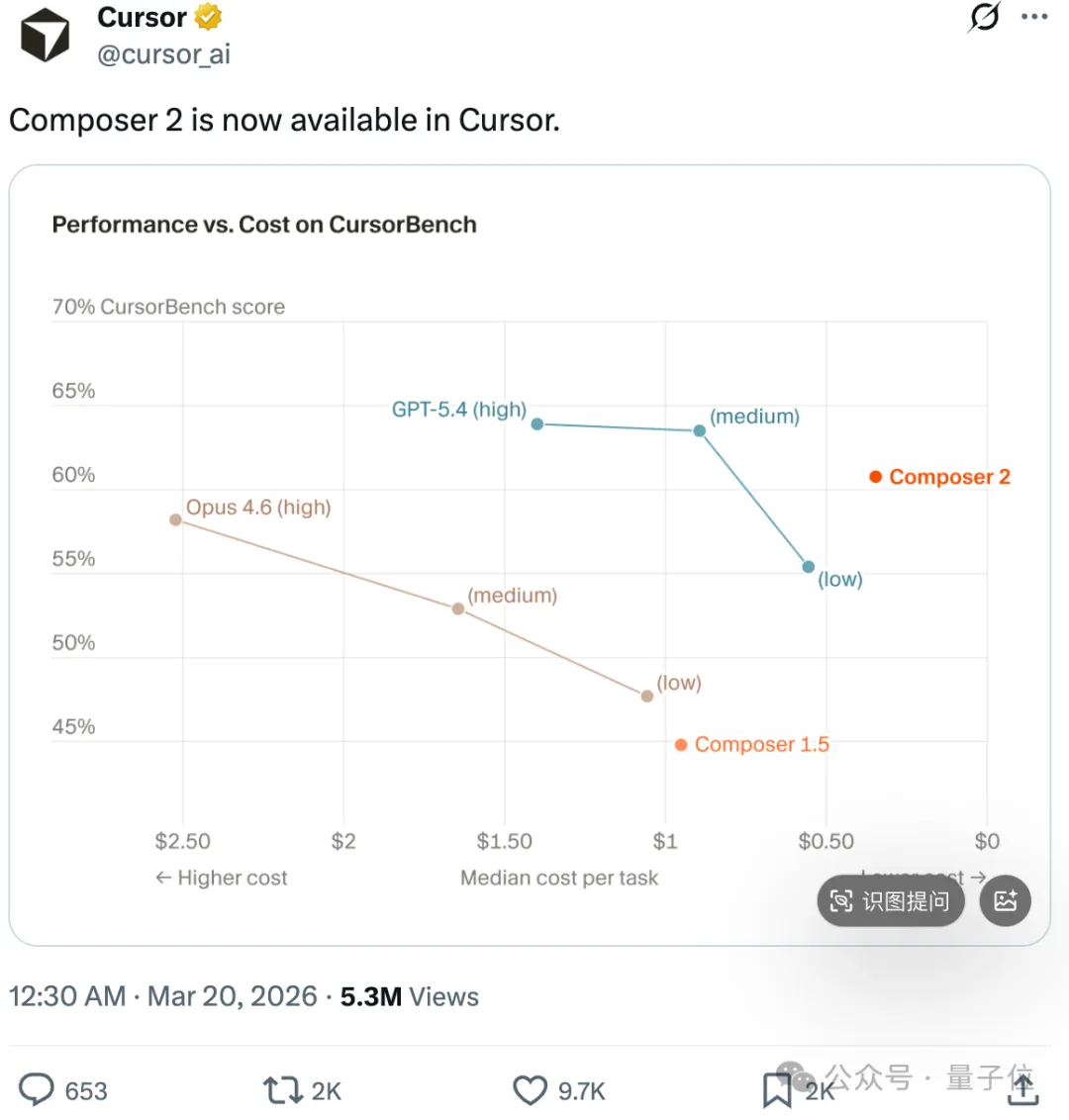
上个月,Cursor的自研模型Composer 2在基准测试上反超了Opus 4.6,价格还脚踝斩。
结果没得意两天就被曝出其实套壳Kimi K2.5。
虽然事情以双方握手言和告一段落,但让人唏嘘不已。
Cursor啊Cursor,你好歹是初代AI编程当红炸子鸡,这事儿干得也不太地道了!
除此之外,另一位炸子鸡Cognition,其自研模型SWE-1.6也被曝疑似在GLM模型上进行后训练。
而且这家伙是个老惯犯了,从前代SWE-1.5就开始偷梁换柱。
去年,SWE-1.5就被曝是在GLM-4.6上进行后训练得到的。
当时的梗图传得满天飞:
Cursor和Cognition最早集成的都是Claude和GPT的能力,但现在已经纷纷转投中国开源模型的怀抱。
Cognition的开发者Shawn Wang还曾直言:
只要基础模型足够好,它的具体特性就越来越不重要了,因为强化学习和后训练才是关键所在,也是区分彼此的关键所在。
不过嘛,初创独角兽不成建制,出现套壳还拒不承认,大家就当个笑话看。
但连巨头也这么干,或许背后还存在更深层次的原因。
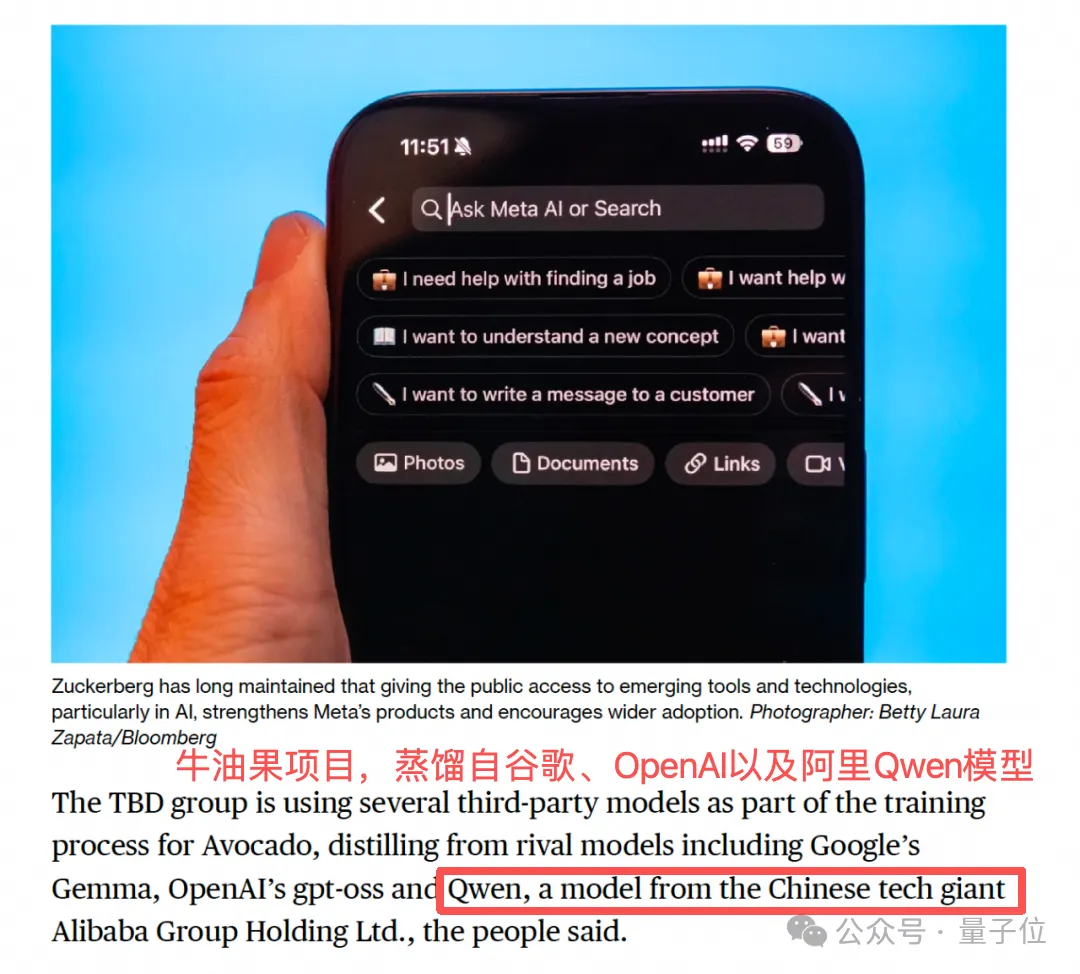
去年12月,Meta的“牛油果”项目曾被曝出使用Qwen开源模型做了蒸馏训练。
在此之前,Meta旗下的Llama模型曾长期主导开源领域,其衍生模型数量和下载量均保持领先地位。
扎克伯格还曾经公开呼吁,要构建以美国模型为核心的开源生态。
但现在,面对自身Llama系列增长乏力与东方模型的强势崛起,Meta已经做出了选择。
经过9个月的奋战,Meta的最新模型Muse Spark已经交卷,不过也是妥妥的闭源了。
此外,爱彼迎的联创兼CEO Brian Chesky,早就被Qwen的实力圈粉了。
他曾经公开表态:
我们很大程度上依赖阿里巴巴的Qwen模型。它非常好,速度也很快,而且很便宜。
我们也会用OpenAI的最新模型,但在实际生产中通常不会大量使用,因为有更快、更经济的模型可供选择。
小八卦,Brian Chesky和奥特曼还是挚友。不过涉及自家应用产品整合时,必须得“亲兄弟,明算账”…
Brian直言不讳,表示OpenAI提供的连接工具还“没有完全准备好”。
爱彼迎的选择,只是中国大模型技术实力的一个缩影。
在学术界,斯坦福大学李飞飞团队、艾伦人工智能研究所等顶尖机构在研究中也采用了基于Qwen的技术方案。
去年年初,李飞飞团队曾基于Qwen2.5-32B构建了一个顶级推理模型s1-32B,成本不到50美元。
该模型的数学和编码能力,与OpenAI的o1和DeepSeek的R1等尖端推理模型不相上下。
艾伦人工智能研究所也基于Qwen2-72B,构建了其多模态系统。
还有Mira Murati创办的独角兽Thinking Machines Lab,也把Qwen作为默认的微调选项。
中国开源模型在硅谷的走红,可见一斑。
性价比压倒一切
为啥硅谷这么热衷于中国开源模型?
当然是因为量大便宜。
Peter Yang算了一笔账:在许多基准测试中,中美同等质量的模型价格相差10-20倍。