中国Token出海凭什么横扫全球?牲产队
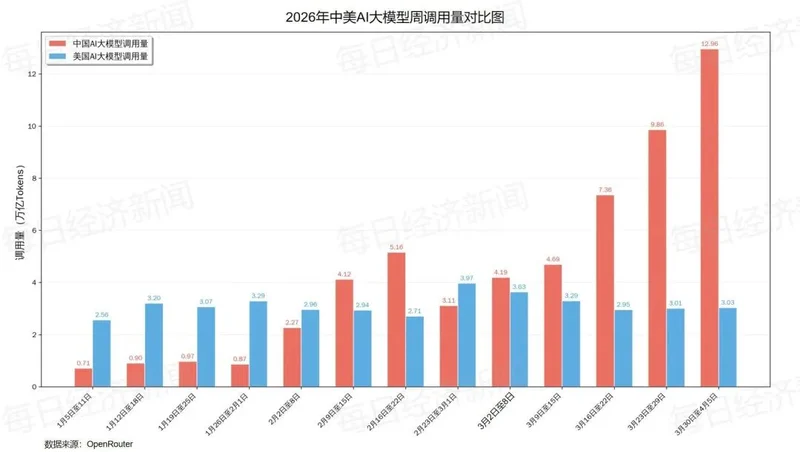
一年逆袭,中国AI甩开美国!上周,中国AI大模型狂吞12.96万亿Token,美国呢?3.03万亿Token。自2月中旬首次超越后,中国已连续5周稳定领先,而且越发趋向于碾压式领先了。这背后,到底发生了什么?中国AI的“超级马力”从何而来?凭什么把美国按在地上摩擦?
在进入正题之前,咱先科普一个新晋顶流科技术语。2026年03月25,全国科技名词委正式官宣,AI领域token标准中文名为“词元”。为什么是 “词元” 二字?可以这么理解,“词”源于语言学,锚定语言属性,“元”表示最小、基本单元。
合起来,语言处理的最小基本单元。它精准概括了介于字符与词语间的动态粒度,已被官媒与学界统一采用。那它的大小又是什么概念呢?在工业时代,我们看GDP,而在AI时代,词元调用量就是衡量一个国家人工智能发达程度的“GDP”。
接着看数据,上周,中国AI大模型的周调用量直接干到了12.96万亿词元,你没看错,是万亿!这数据一出来,OpenRouter的排行榜都快成“中国专刊”了,前10名里,前6席全是国产模型,总调用量直接碾压。
从2026年2月那一周开始,中国以4.12万亿词元首次反超美国的2.94万亿,到如今连续5周稳定领先,中国AI不仅逆袭了,还拉开了4倍的恐怖差距,这不仅是技术的胜利,更是一场国家工程能力的总爆发,怎么做到的?总结下来有三点。
一是,电力。人工智能的尽头是电力,你让AI算一次,它就得调动成百上千块显卡疯狂运转,这玩意儿是妥妥的“电老虎”,所以,首先你得有电!而中国手里握着一张王炸,全球最庞大、最先进的电网,以及“取之不尽”的廉价电力。
中国把算力中心直接建在发电厂旁边,把“瓦特”高效转化为“词元”。内蒙古的风电、光伏发出来的电,直接被数据中心就地消化,变成Token输出全球。这就相当于是把低成本电力转化成算力产能,大模型接口变成了AI界的“港口”。
二是,算力。光有电还不够,还得算得快、算得便宜。美国现在的路子是“堆砌主义”,拿着昂贵的英伟达芯片,靠堆参数、堆数据来训练模型。这就导致了一个恶性循环:模型越大,越费电,成本越高,OpenAI现在就是这个状态。
而中国呢?是被“逼”出了另一条路,因为高端芯片受限,必须把每一度电、每一块芯片的性能榨干。中国搞“推理芯片”、搞“模型架构”优化,目标不是为了发论文炫技,而是为了让AI跑得更便宜、更聪明。
三是,应用。光有电、有算力,没人用也不行。头豹研究院的数据很说明问题,2025年下半年,中国企业级大模型日均消耗词元达到了37万亿,比上半年涨了2.63倍,这些词元全用在哪儿了?
中国有全球最完整的工业体系,一条汽车生产线、一个化工厂、一座物流中心,从研发、风控,到营销、客服每个环节都能接入AI,这种大规模的真实场景数据积累,反过来又让模型越跑越准,越跑越聪明,形成良性循环。
中国AI为什么能赢?因为我们不赌运气,我们靠的是“东数西算”的宏大布局,靠的是“新能源和算力”的深度融合,靠的是“14亿人口和全产业链”的超级应用场景。两年千倍增长,只是序章,这场属于中国AI的“黄金时代”,才刚刚开始。