Claude「断电」背后:中国捅开「死穴」新智元
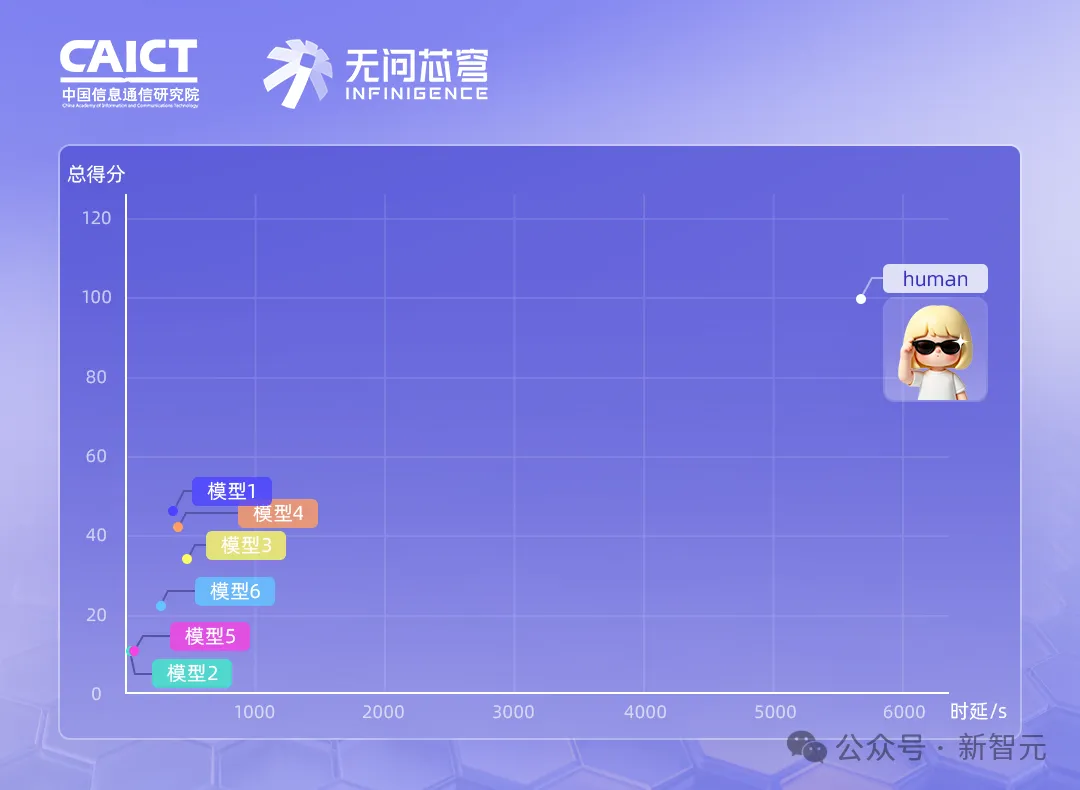
6月22日Claude全家桶集体宕机,只是冰山一角。当最强大模型被丢进真实机房直面「幽灵故障」,AISHPerf-智算运维智能体评测基准给出残酷答案:全军覆没,无一过50分。这道鸿沟,第一次被量化。
6月22日,全球AI圈突然集体「断电」。
Claude的「全家桶」——claude.ai、Console、API、Code、Cowork——在短短几个小时内大面积宕机。
开发者终端刷满红色报错,企业协作流水线瞬间断流,社交媒体上炸了锅:有人晒出满屏502截图配文「被AI炒了鱿鱼」,有人感慨「2026年最体面的摸鱼理由——模型宕机了」。
而这,还算快的。笑归笑,背后的现实却一点也不好笑。
当AI从聊天玩具变成驱动千亿美金算力投资的「生产设备」时,基础设施的稳定性,已经成了决定整个产业生死存亡的隐形天花板。
而更残酷的测试结果刚刚出炉——
AISHPerf-智算运维智能体评测基准,由中国信息通信研究院(信通院)推出,无问芯穹参与重点技术建设,把包括Claude-4-sonnet在内的国内外主流大模型扔进真实GPU集群环境,让它们处理真正的生产级故障。
结果,全军覆没,综合得分全部低于50分。中等和困难难度正确率普遍不到一半。
测试对象包括Claude-4-sonnet和主流开源模型等,均做匿名化处理
这不是语言游戏的失败,这是「说」与「做」之间,一道真实而残酷的鸿沟。
万亿市场,智能体到底能不能稳稳接住?
想象一下这样的场景:凌晨三点,训练任务突然出现无规律剧烈性能波动。
运维团队紧急兜底排查,却遇上最诡异的情况:网络链路正常、存储性能正常、节点硬件也正常。
为了定位根因,运维人员只能全链路逐层溯源排查,从模型切分策略、任务调度逻辑,一路深挖到底层网络协议、内核参数、存储配置规则……
可能要耗费巨大的人力物力和时间,最终才会在一些极为隐蔽的边缘场景中,发现问题。
最致命的是,这类故障的排查周期,往往长达十天半个月。
而在这漫长的排障期间,大量服务器在持续空转,海量算力资源白白损耗,AI训练业务全程停滞。
像这样的「幽灵故障」,在任何大规模GPU集群里都不是个例。
它们隐蔽、跨层栈、难以复现,却直接吞噬真金白银。
摩根士丹利预测,2028年全球AI基础设施累计投资将达2.9万亿美元。
其中,运维人力、故障损失与集群闲置构成的成本占比高达15%-20%,全行业潜在可优化空间超过4350亿美元。
无问芯穹早在2025年10月就已率先探索和应用早期版本的运维智能体。
真实生产环境里的数据最有说服力:工单平均处理时长缩短 50%,关键故障处理效率提升约6倍,运维人员人效提升5倍以上,综合运维成本下降约30%。
这些数字背后,是无数个被解放出来的凌晨三点,和无数度没有被白白烧掉的电。
但问题来了——究竟什么样的运维智能体,才配得上「好用」这个词?
全球首个真实机房的「开卷实操考」
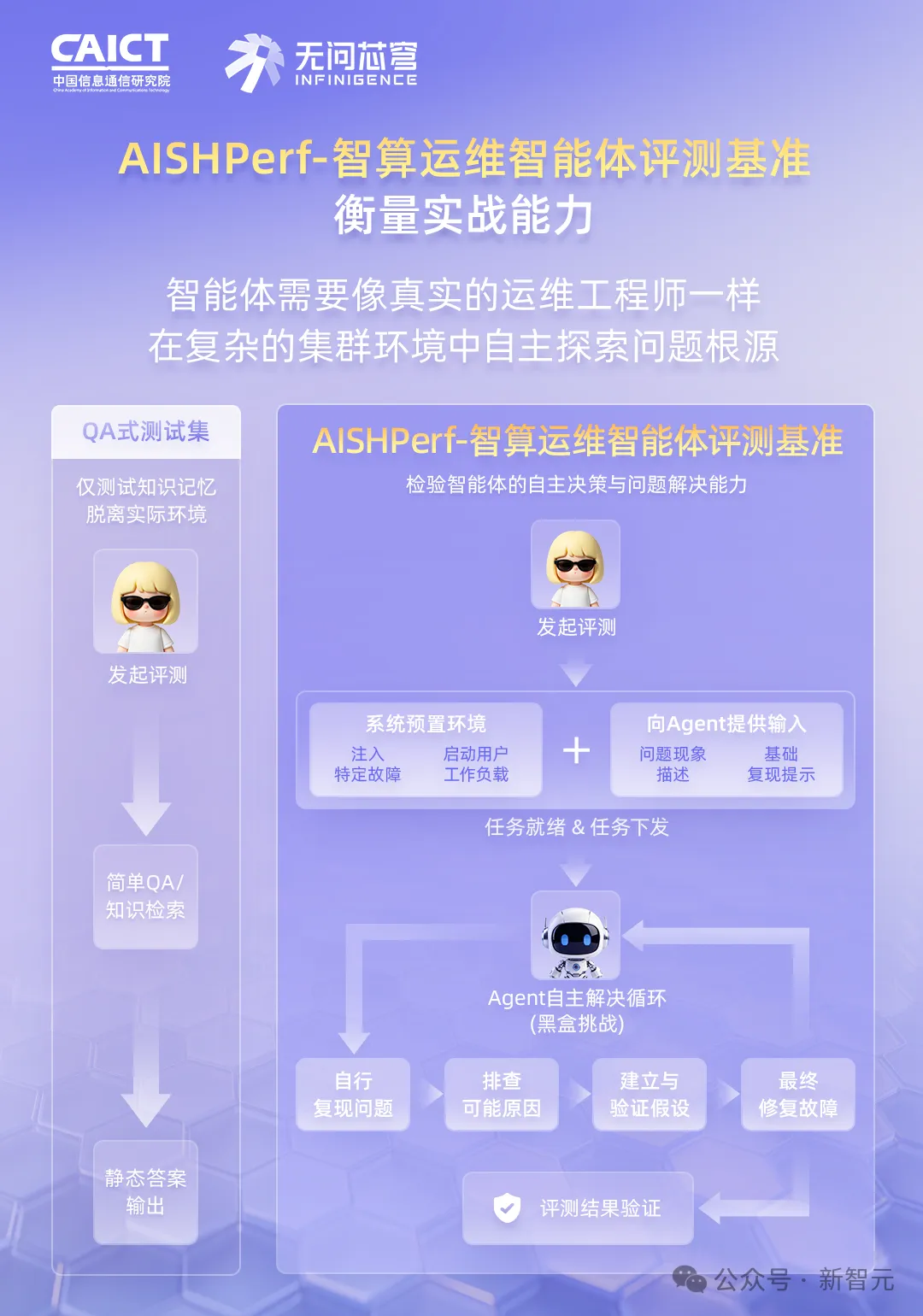
过去对大模型的评估,更像一场语言知识竞赛。模型背得越多、说得越漂亮,分数就越高。
可当AI真正走进基础设施领域,「能否解决实际问题」成了唯一标准。
因为,它最终会影响到每一度电、每一张GPU卡的产出效率。
AISHPerf-智算运维智能体评测基准,彻底颠覆了这种「纸上谈兵」。
它源自无问芯穹积累的近百亿条真实运维数据。
经过严格过滤、去重、脱敏三阶段精细标注,最终提炼出高质量、高保真评测用例。
每一条都包含真实的问题现象和明确的故障根因。
更重要的是,这套基准不给根因,需要AI自行探索。
它只告诉你:「训练任务卡死了,用户反馈是这样的,请复现并修复。」
智能体必须自己进入真实集群环境,自主发现线索、提出假设、验证、执行修复。
整个过程必须安全、有效、不能把机房搞炸。
这才是真正的「开卷实操考」——它考的是长链路多跳推理、与真实物理设备的交互能力、在不确定性中做决策的勇气,以及最关键的安全边界意识。
为了让这场考试公平且可重复,AISHPerf-智算运维智能体评测基准配套了AIops-Chaos混沌工程项目。
它能通过软件层精准模拟GPU掉卡、显存错误、NVLink故障、网络分区等真实硬件异常,无需物理损坏硬件,就能构造高保真测试环境。
只需要一台GPU+多轨RoCE NIC服务器,就能实现分钟级的故障编排与自动化恢复验证。
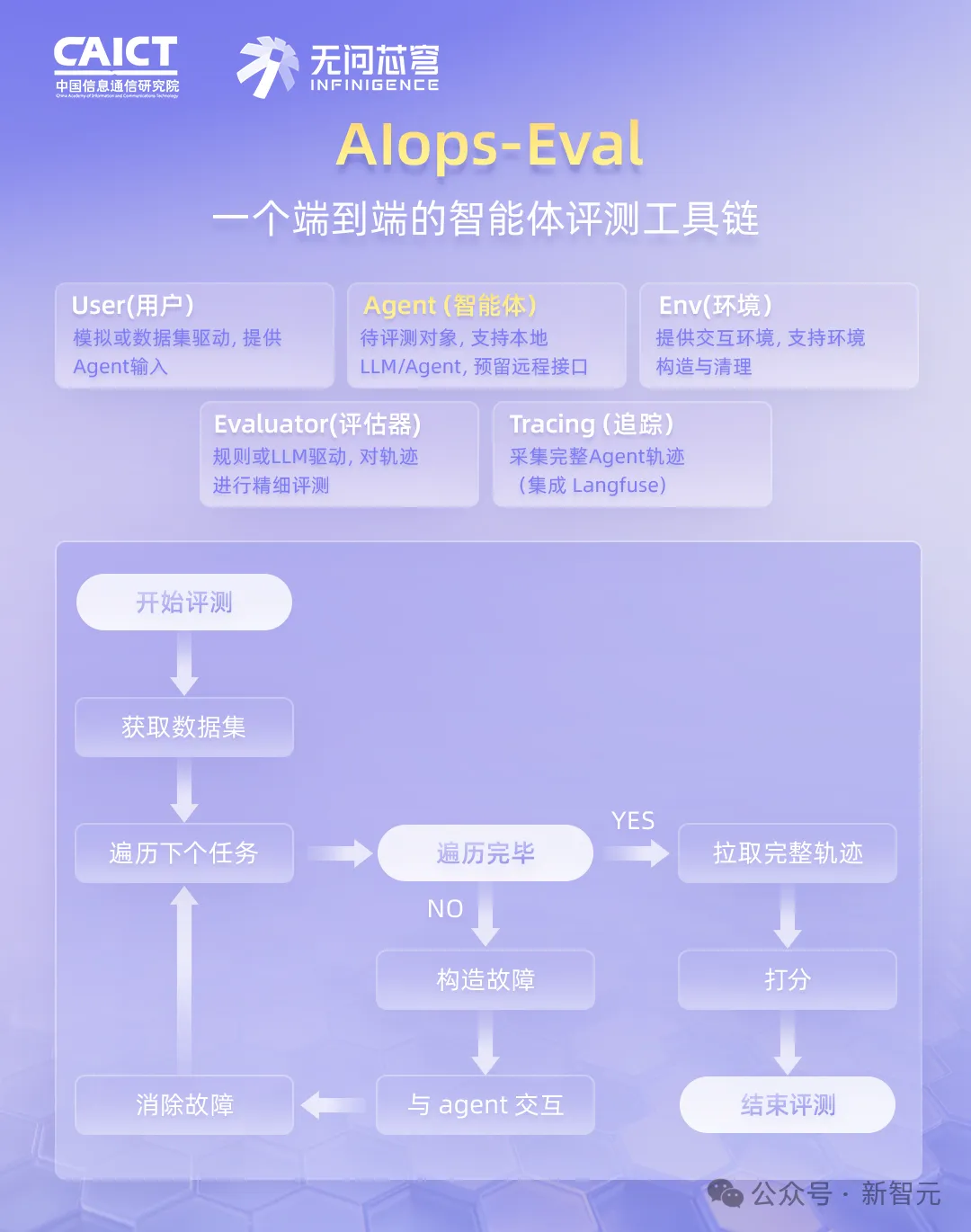
这套评测框架(AIops-Eval)包含User、Agent、Env、Evaluator、Tracing五个核心模块,完整记录智能体每一步的轨迹,支持自定义规则和LLM-as-Judge双重评测。
它不再关心模型「知道多少」,只关心它在真实世界里,能不能把事情做成。