被ChatGPT推翻,陈立杰惊呼:太不可思议新智元
GPT-5.5 Pro 生成了一个数学证明,解决了计算几何中一个 陈立杰苦思 7 年未解的核心难题。关键技术来自 OpenAI 上月的另一项突破,而最初推进这个问题的陈立杰发现,钥匙竟是自己参与的工作。
6 月 24 日,arXiv 上出现了一篇论文:UCSD 三位研究者 Barna Saha、Yinzhan Xu 和 Christopher Ye 证明,「最远点对」等经典计算几何问题,在任意超常数维度下需要近平方时间。
论文声明,初始证明由 GPT-5.5 Pro 生成。
给 AI 的 Prompt 只有两句话,大意就是「试试用这个证明思路去改进那个已知结果」,附上两篇论文链接。
这个问题 7 年前由陈立杰首次推进到接近极限,而补上最后一块拼图的关键技术,恰好来自他自己上个月在 OpenAI 参与的另一项工作。
陈立杰在 X 上惊呼,「This is incredible!!!」
陈立杰想了 7 年的问题
陈立杰是算法圈顶级天才,IOI 金牌得主,本科毕业于清华姚班,博士前往 MIT 师从理论计算机科学家 Ryan Williams,毕业后入职加州伯克利担任助理教授,现任职 OpenAI,是理论计算机科学领域最受关注的青年学者之一。
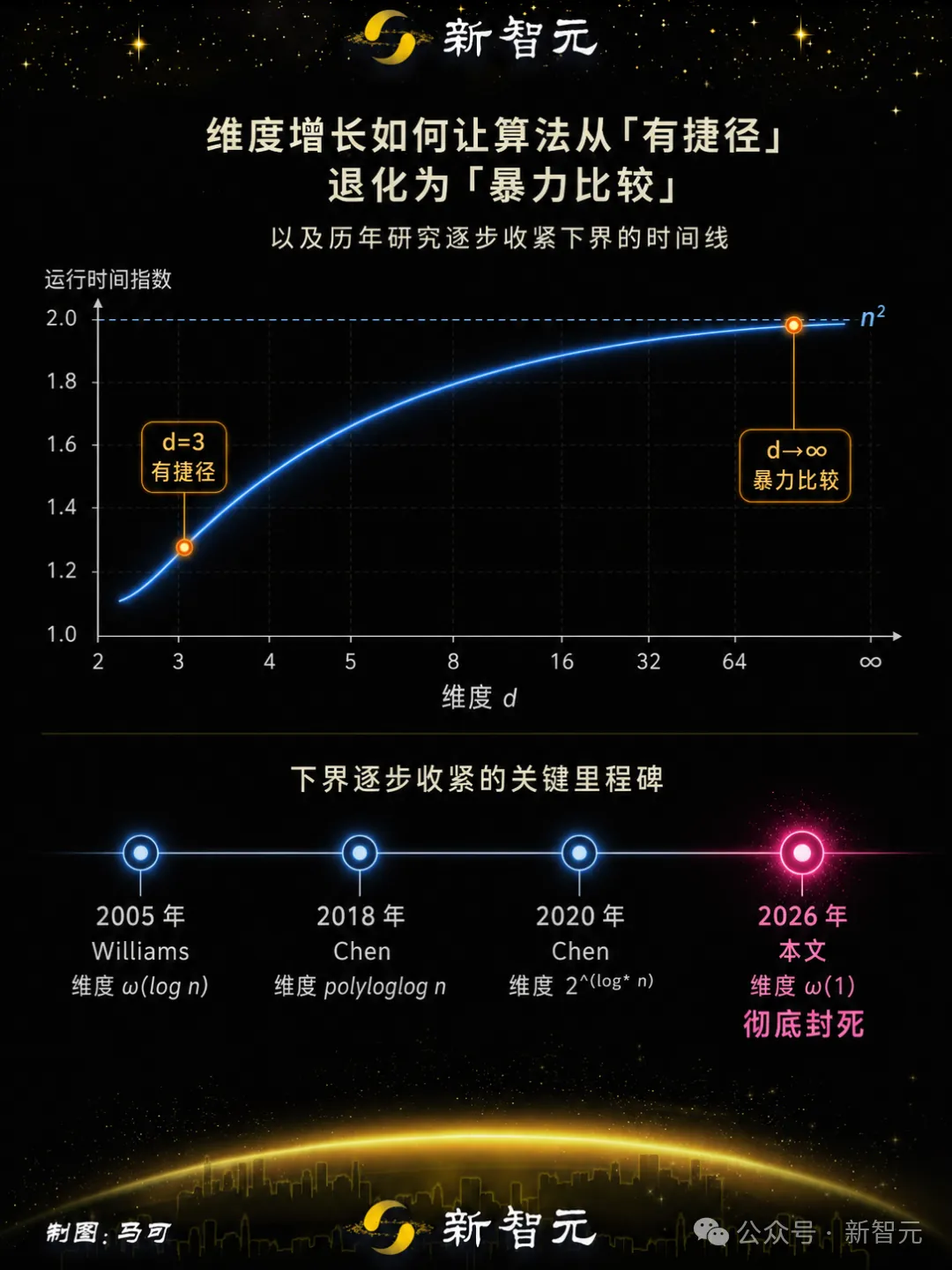
2018 年,他读博的第一篇论文就在这个问题上取得了关键进展,把维度下界推到了 2Θ(log* n)。
log* 是一个增长极其缓慢的函数,拿宇宙中原子总数那样大的数去算 log*,结果也才 5 左右。
他已经把下界逼到了一个几乎不增长的门槛前,再往下推就撞到了硬墙。
此后 7 年,断断续续地想,始终没能跨过去。
上个月,他在 OpenAI 参与了对 Erdős 单位距离猜想的反证。
这篇新论文的作者们随后发现,那项工作中的代数数论技术,恰恰是跨过最后一步所需要的。
这个重大猜想具体是什么意思呢?
想象一个体育馆里坐了一万人,要找出坐得最远的两个。
如果体育馆是个平面,用两个坐标描述每个人的位置,有很聪明的算法可以快速搞定。
但如果每个人的「位置」需要用 100 个、1000 个数来描述呢?这就进入了高维空间。
目前最好的算法运行时间大致是 n2-c/d,n 是点的数量,d 是维度,c 是常数。
维度低时指数明显小于 2,有捷径可走;维度一高,指数逼近 2,退化成把每两个人都比一遍的暴力方法。
这篇论文回答的核心问题是,算法不够聪明,还是问题天生就这么难?
答案是后者。
只要维度在增长,哪怕增长得慢到 log log log log n(一个对天文数字来说也才等于 2 的速度),就不可能存在真正快于 n² 的算法。现有算法的表现已经基本是极限。
同一结论还覆盖了一整个问题家族,双色最近点对、最大内积搜索、Hopcroft 问题,全部适用。
补充一个前提——结论的成立依赖 SETH(强指数时间假设),它说的是 SAT 问题(判断一个布尔公式能否被满足)不存在比暴力搜索快很多的算法。
这个假设被广泛认为成立,理论计算机科学中大量下界结论都建立在它之上。
卡点:质数太稀疏了
之前所有攻克方法共享一个核心思路。
把长向量切成 L 个小块,每块 b 位。
对每个小块用不同的质数取余数,中国剩余定理保证,如果一个数对足够多个不同的质数取余都得零,那这个数本身就是零。
所以只要用 b 个不同的质数分别检验每一位,就能判断两个向量的内积是否为零。
问题出在「足够多」三个字上。
b 个不同的质数,最小也得排到第 b 个质数,大约是 b log b。
这些质数的乘积随 b 指数级增长,编码出来的数字大到离谱。
当维度很低、每块位数 b 很大时,编码的计算开销比原问题还重,整个方法就失效了。
陈立杰 2020 年用递归技巧把这个矛盾压到了极限。
再往下,「质数密度不够大」这堵墙翻不过去。
破局:在另一个数学世界里让质数「裂开」
转机来自一个看起来完全不相关的方向。
大家都学过复数,在实数基础上引入 i(满足 i² = -1),得到一个新的数系,加减乘除规则不变,但多了一个维度,可以做更多事情。
数学家发现同样的操作可以推广。
往有理数(就是所有分数)里加入某个特定的根,就能造出一个新的数系,叫做「数域」。
比如加入 √2,得到所有形如 a + b√2 的数(a、b 是有理数)。
这个新数系和普通数一样可以正常做加减乘除,也有自己版本的「整数」(叫整数环),也有自己版本的「质数」(叫素理想)。
关键在这里。
在普通整数世界里,7 是质数,不可拆分。
但在包含 √2 的数域里,7 可以写成 (3+√2)(3−√2)。
一个原本不可分割的质数,裂成了两个因子,每个因子在新数系里各自充当「质数」的角色。