只用小学数学带你读懂《Attention Is All You Need》AI真人感
如果要评选出人工智能领域最著名的一句话
Attention Is All You Need
一定值得被提名
2017年,8位Google的工程师发表了一篇论文。
论文发表之后,一家创业公司敏锐地抓住了论文中架构的核心思想,用它训练了一个新模型,彻底改变了整个AI圈。
这家公司就是截止到目前市值超过 8000 多亿美元的 OpenAI。
这个模型就是 GPT 系列。
其中GPT 的 T,就是指 Transformer。
而这篇论文的标题就是这句
Attention Is All You Need。
你需要的,只是注意力。
这篇论文首次提出了 Transformer 架构,彻底改变了人工智能的技术路线,催生了OpenAI等行业巨头的迅速崛起。
后来 8 位作者也都离开了 Google,其中的 7 位选择了创业,而他们创立的公司,估值也普遍达到了数亿到数十亿美金。
一篇论文的背后催生的商业帝国价值实在让人疯狂,为什么今天的大模型,都活在《Attention Is All You Need》的影子里。
有时候,一场技术革命的开头,看起来像一句很狂的话。
《Attention Is All You Need》
这个标题翻译得再直一点,大概就是,你只要注意力就够了,其他都不需要。
说真的,这种标题多少有点要掀桌子的意思。
读懂了这篇论文,就掌握了通用生成式大模型的核心思想。
要理解 Transformer,我们先看它出现之前,到底存在什么问题。
回到 2017 年之前,AI 处理自然语言,靠的主要是一种叫 RNN(循环神经网络)的技术。
RNN 的工作方式,就像一个一字一句,按顺序读书的学生。读到「我」,记住「我」,然后读「今」,然后读「天」,然后读「买」……每读一个字,它都把前面的信息往后带一点。
后来的 LSTM、GRU,都是在这条路线上做的改良。
听起来很合理,对吧。我们读句子不也是这样吗。
可读着读着,问题就来了。
RNN 有两个非常棘手的问题。
第一个就是记性不好,一句很短的话,还撑得住。
句子一长,前面的信息就容易被冲淡。
「我昨天在书店买了一本科幻小说,晚上回家洗完澡,泡了杯茶,坐到沙发上,才开始读它。」
人当然知道最后那个「它」指的是前面的「科幻小说」。
但是机器如果靠RNN,走到最后时,那本书的影子有可能就要忘记了。
它可能会猜「它」指的是茶,或者沙发。
你想想看,这像不像传话筒。
人一多,距离一长,前面说过的话就开始失真。
越长的句子,RNN 越容易犯糊涂。
而且,还慢。
这是另一个更要命的问题。
RNN 这条路线天然很难并行。
前一个词没算完,后一个词就不好算。
这在今天的 GPU、TPU 世界里,特别吃亏。因为这些硬件最擅长的事,不是耐心排队,而是大家一起算。
但 RNN 的结构决定了它只能排队一个个来,完全浪费了快速发展的底层能力。
后来人们也不是没有想办法补救。
在 Transformer 之前,注意力机制其实已经出现了。那时候它更像给老房子加了个外挂窗户,翻译模型在生成一个词的时候,可以回头看一看原句里哪些地方更相关。
是有一定的效果。
但房子的主梁还在,还是那套一格一格往前传的结构。
2016年的某一天,谷歌工程师波罗斯库欣在公司吃饭,向同事乌兹科雷特抱怨,说搜索模型里 RNN 太慢了,达不到想要的效果。
乌兹科雷特随口说了一句话,一共五个单词,全是初中词汇:
「Why not use self-attention?」
为什么不用自注意力呢?
就是这句话,推开了一扇门。
二人一拍即合,决定推翻当时风头正盛的 RNN 和 LSTM。
乌兹科雷特后来给这个新项目取了个名字,叫 Transformer。因为他从小是变形金刚的铁粉。他们甚至在项目文档中画了一幅变形金刚的卡通图,然后写了一句底气十足的话:
「We are awesome.」
接下来的内容有点干,我们先喝口水...
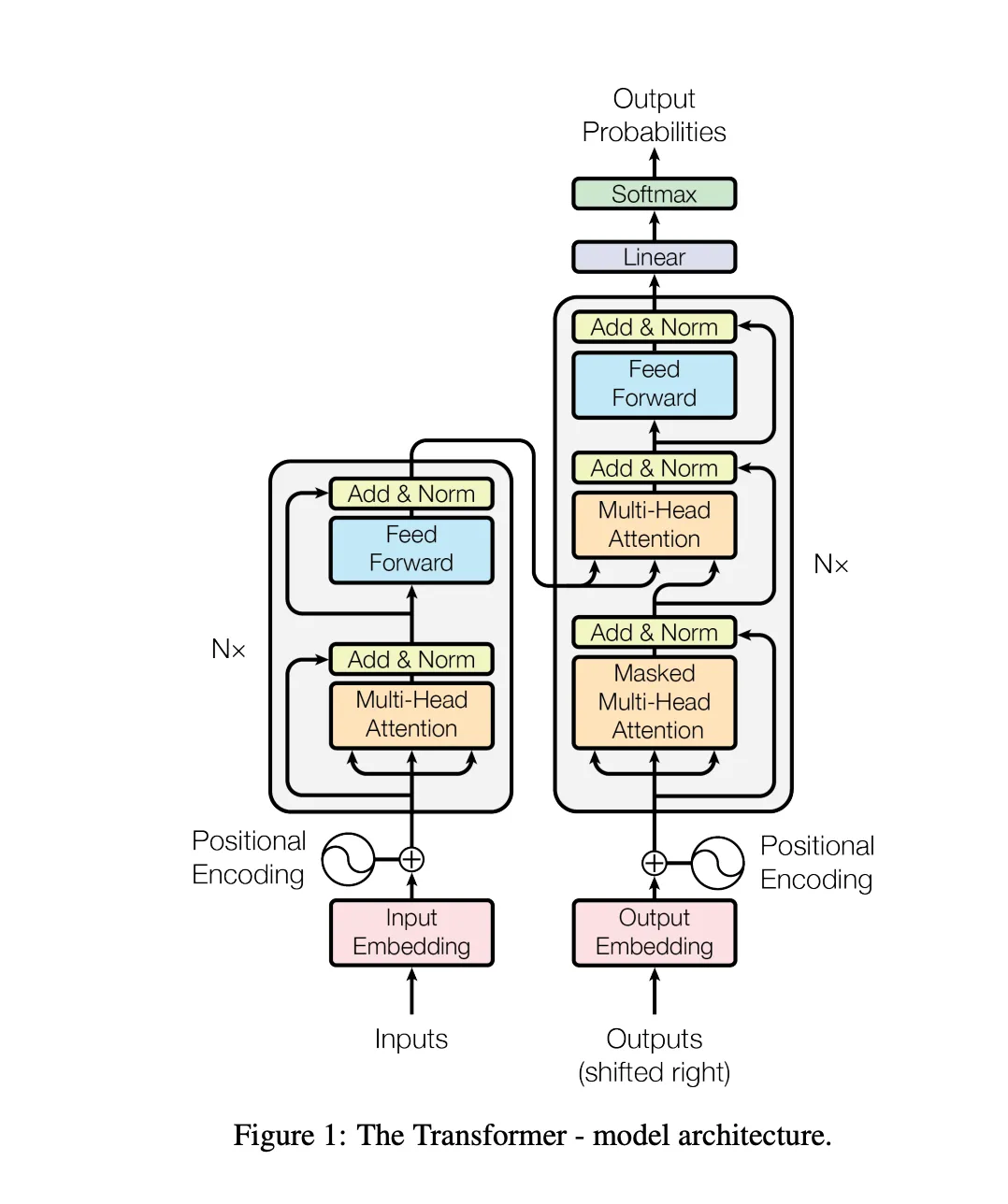
进入论文中最精髓的部分,就是这张 transformer 架构图 Encoder-Decoder,我们只用小学数学知识理解它。
先看左边的最底部 inputs
transformer 架构最初是为了处理翻译任务,在训练模型时喂给模型的语料数据就是输入
进入模型后首先进行input embedding,输入嵌入
我们平时使用的自然语言,模型是无法直接计算的,都会先经过分词被转换成另一个大家每天都能听到的词 token
token 最近也有了自己的官方中文名字 「词元」
这里插一句自然语言转换成 token,不同的模型使用的分词规则是不同的,举个最直观的例子
中文常用字级分词,‘我爱 AI’会分成 4 个 token
也有模型用词级,‘人工智能神奇’会分词 3 个 token,人工智能算成了一个词。
为了让计算机理解,所以每个词,都要先被转换成一组数字,也就是一个向量,在原始的 Transformer 论文里,这个向量是 512 维的。
比如‘我’变成了 [0.12, -0.33, 0.98 ...]
3 维空间我们很好理解,但是 512 维脑子就乱了,但是计算机可以很好的利用 512 维的空间,这样每个词的所有特征都能被标记出来,计算机就理解了每一个词的含义。
想象有 512 位侦探,每人只负责观察这个词的一个特定角度,有人专门看「这个词和食物有没有关系」,有人专门看「这个词是不是带情绪的」,有人专门看「这个词更偏向具体的东西还是抽象的概念」
512 个人各自给出一个数值,合在一起就是这个词的向量。
含义相近的词,在这个 512 维空间里会挨得很近,苹果和香蕉的距离比和石头的距离要近,程序员和代码位置也会比较近。
有了数字表示的向量,这个 512 维的空间就可以运算了。
比如我们用「湖人」的向量减去「洛杉矶」,再加上「芝加哥」的向量,结果就落在「公牛」的附近。
「长城」减 「中国」,再加上「埃及」,结果很可能就是「金字塔」。
如果你好奇,也可以用向量算一下谁更像男版的杨超越...
我们在回头看刚才的例子,湖人指向洛杉矶的向量和公牛指向芝加哥的向量,两个方向几乎一致,他们都代表 NBA 球队所在的城市,它们表示的语义非常接近,两个向量的夹角越小,它们的内积,也就是点积就越大,代表这两个向量的意思越接近,夹角越小,甚至方向相反,相关性就越小。