20岁写出Transformer的人:开源2180亿大模型新智元
刚刚,Cohere放出2180亿参数的MoE大模型Command A+,单张B200可跑,支持48种语言,还带原生引用能力。但这次发布最炸的,不在参数表上,而在那一个许可证:Apache 2.0。
「Attention Is All You Need」,正是这篇著名的论文,催生了今天所有的大模型。
5月20日,该论文的一位共同作者Aidan Gomez,在X上宣布推出首个完全开源的Apache 2.0许可的模型:Cohere Command A+。
Gomez是前谷歌研究员,如今是Cohere的联合创始人兼CEO。
Command A+是Command A家族的最后一个模型,也是Cohere的第一个MoE(混合专家)模型。218B总参数,25B激活参数:一次性把视觉输入、推理、翻译和AI智能体能力,全部塞进了同一个模型。
最低部署配置:1张NVIDIA B200,或者2张H100。许可证:Apache 2.0。
据VentureBeat报道,这是Cohere历史上第一个真正可商用的开源旗舰。联合创始人Nick Frosst称它是「我们发过最好的模型」。
2180亿参数
每次干活的只有250亿
2180亿参数,听起来就是个吞算力的巨兽。但Command A+每次生成,真正被激活的只有250亿参数。
这正是MoE架构的精髓。
一个MoE模型,会将进来的问题只路由给最擅长处理它的那几个「专家」神经网络,其余部分保持休眠。这样的设计,既让模型保留了「巨头级」的知识储备和推理能力,但运行时的算力和能耗,却接近一个小得多的模型。
VentureBeat报道,据第三方观察估计,OpenAI的GPT-5.5、Anthropic的Claude Opus 4.7参数量都在万亿级别,而Command A+每次激活的参数只有250亿。
靠MoE省算力,如今是大多数头部模型的惯常做法。但Cohere在这个基础上又叠了第二层压缩:量化。
Command A+提供BF16、FP8和高度压缩的W4A4三种版本,其中W4A4是这次发布的技术核心。
通常,推理模型一旦被压缩,复杂问题上的表现会肉眼可见地退步,业内称之为「量化税」。
Cohere的做法,是只将MoE专家压到4-bit,关键的注意力通路保留全精度,再叠加一项叫量化感知蒸馏(Quantization-Aware Distillation)的技术。
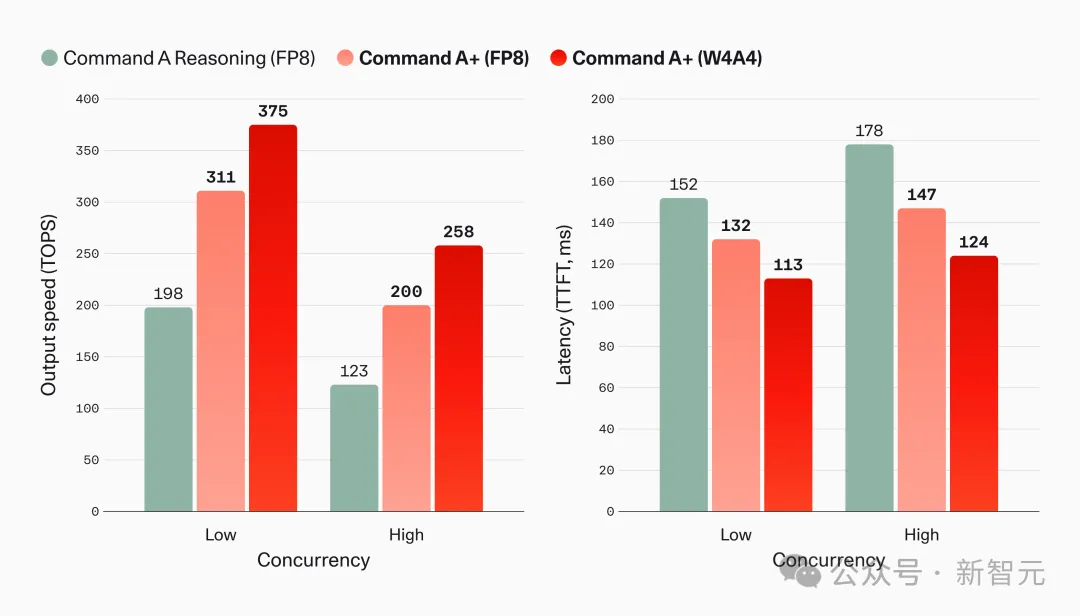
Cohere称其W4A4量化方案接近无损。据Cohere发布的性能数据显示,W4A4版本在低并发下达到每秒375个token,首token延迟仅113毫秒。
正是靠这套方案,让一个2180亿参数的模型,能跑在单张NVIDIA B200上,或者两张H100上。
不同并发与量化下,Command A+与前代Command A Reasoning的速度和延迟对比。TOPS为每秒生成token数,TTFT为首token延迟。数据由Cohere发布。
这里所谓「单卡运行」,指的是一张数据中心级的Blackwell B200,并非消费级显卡。
过去一个千亿级模型要一整个GPU集群伺候,现在一台机器搞定。
这正是Cohere这次想讲的故事:大参数,不再等于烧钱。
Apache 2.0
一张通往真开源的许可证
如果只看参数和速度,Command A+是一次强大的工程升级。但更值得开发者们注意的,是一张Apache 2.0许可证。
在今天的AI圈,「开源」是一个早被「玩坏」的词。
很多领先的AI公司放出权重,却套着限制性的商用条款:大企业不许拿去做商业用途,也不许用它训练竞品模型。下载可以,研究可以,真要赚钱,回来买授权。
Cohere过去在这个方向上也摇摆了很久。
据VentureBeat报道,它此前的Command R、Command R+,采用的是CC-BY-NC 4.0,也就是「知识共享-非商业」许可。研究者和开发者能下载、能折腾、能评测,但严禁商用。
也就是说:开放一半,留一半。但到了Command A+,另一半也松开了。
它采用了Apache 2.0,一个OSI认可的真正开源许可证。从独立开发者到世界500强企业,任何人都可以使用、修改、分发并商业化这个模型,不付授权费,也没有竞业条款。
这是Cohere首次这么做,它在一位写出Transformer的人的带领下,全面倒向了真正的开源。
据VentureBeat报道,这个决定由联合创始人Nick Frosst力主推动。
Frosst是Cohere三位联合创始人之一,曾在谷歌大脑多伦多实验室做研究员,是AI教父Geoffrey Hinton在那里最早的雇员之一。
Cohere将旗舰模型从CC-BY-NC 4.0转到Apache 2.0,意味着企业彻底不必再被供应商捆住。
一家公司可以下载Command A+的权重,用自己高度机密的内部数据做微调,部署在私有服务器甚至气隙网络里,从此不再被Cohere的基础设施、定价变动或API稳定性绑住。
Command A+
把「可追溯」做成模型的原生能力
能跑和敢用,完全是两回事。
一个模型要真正进入金融、医疗、法律的生产环境,真正的瓶颈不是模型能力,而是可信。
Command A+在这件事上,做了一个原生层面的设计:原生引用(native citation)生成。
当Command A+从外部工具检索信息时,它不只是把答案合成出来,还会生成所谓的「grounding spans(溯源标记)」。
通过在输出里嵌入特殊标签,模型把它给出的每一条事实声明,直接链接到它所引用的那份具体文档或那一行数据库记录。
举个场景。你让它出一份当日销售报告,它给出总销售额的同时,会明确标出提供这个数字的那一次数据库查询结果。出处一目了然,幻觉风险被压到最低。
这种可追溯性,对于受到严格监管的行业尤为重要。
智能体能力,也是这次发布的一个重点。
Command A+支持标准chat template下的对话式工具调用,可以无缝对接内部API、搜索引擎或SQL数据库。
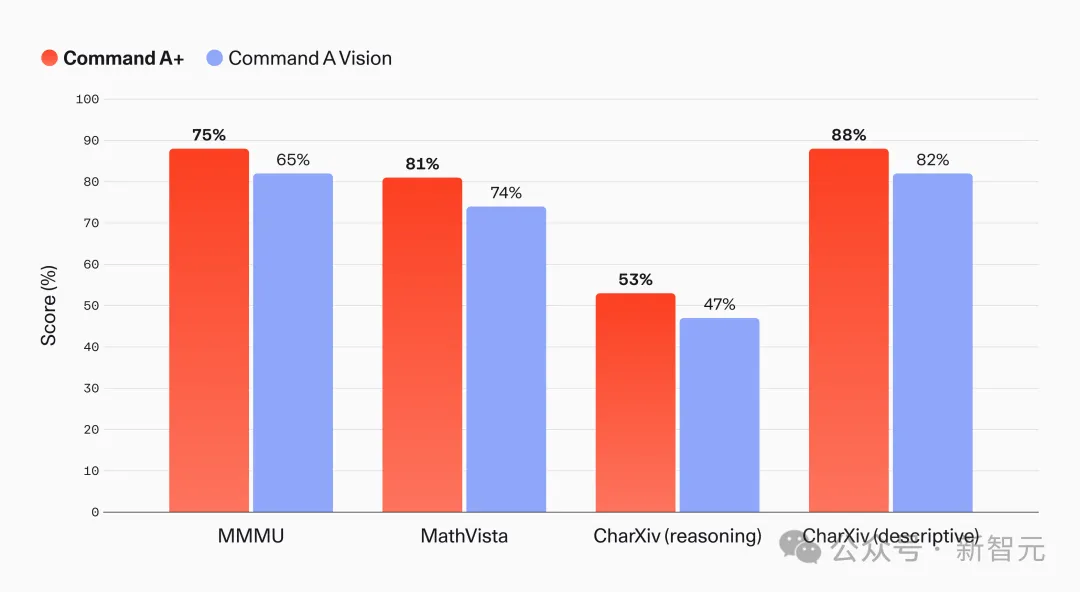
它还是全多模态的,在128K输入上下文里原生处理文本和图像,适合分析扫描发票、图表和技术手册。
Command A+与Command A Vision的多模态能力对比,Command A+是Cohere首个多模态推理模型。数据由Cohere发布。
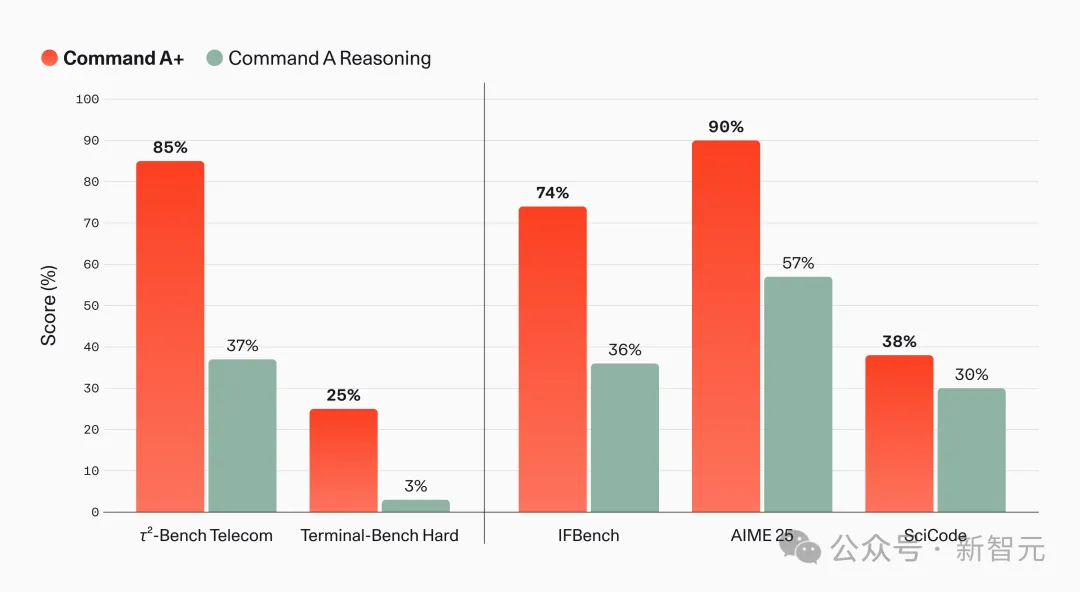
据Cohere发布的性能数据显示,在测试复杂推理的²-Bench Telecom上,Command A+从前代的37%跳到85%;在衡量智能体编码能力的Terminal-Bench Hard上,从3%爬到25%;在AIME 25数学测试上,从57%升到90%。
Command A+与前代Command A Reasoning在五项开源基准上的表现对比。数据由Cohere发布。