arXiv新规,陶哲轩附议:AI水文封一年,署名连坐量子位
上传AI水论文,被查实者封禁一年。
后续投稿须先通过同行评审,才有资格重新踏入arXiv。
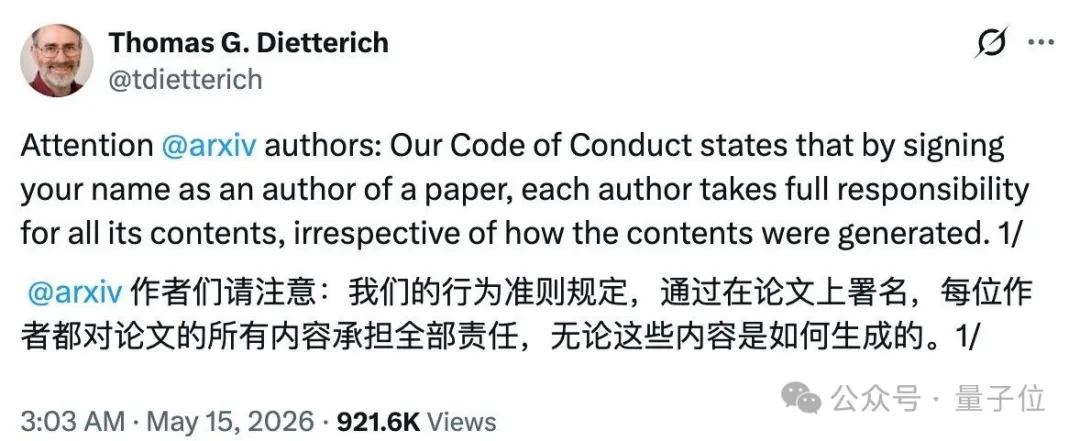
这是arXiv计算机科学版块主席Thomas Dietterich在X上刚刚公开的新规,语气干脆,不带商量。
若论文中存在作者未核查LLM生成内容的确凿证据,所有署名作者一并受罚,没有例外。
消息一出,陶哲轩也亲自下场评论。
这位数学界最活跃的AI拥抱者,专门在Mathstodon发文,用自己此前提出的四条建议框架逐一对照新政,总结为一句话:
在生成论文比消化论文容易得多的时代,这个方向是对的。
网友则炸开了锅,有人鼓掌,说早就该这么干。
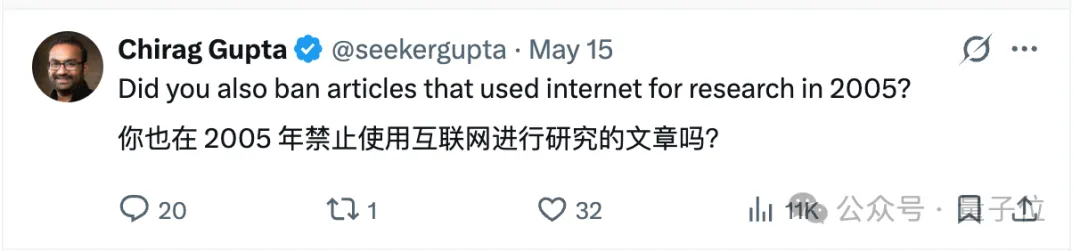
也有人反问:你会在2005年禁止用互联网进行研究的文章吗?
还有人提出质疑:这样的连坐制度,是要求论文的每一位合著者都必须检查每一条引用吗?
arXiv最严新规:签名即担责
物理、数学、计算机科学领域,绝大多数论文在进入同行评审之前,都要先在arXiv挂出预印本。
它是全球学术流通最核心的基础设施之一,正在推进从康奈尔大学剥离、转型独立非营利机构,有望获得更多资源和动力主动出手治理。
arXiv这次出手,核心逻辑只有一句话:签名即担责,无论内容如何生成。
Thomas Dietterich的原话是这样的:
如果生成式AI工具产生了不当语言、抄袭内容、偏见内容、错误、错误引用或误导性内容,且这些内容被纳入科学著作,责任由全体作者承担。
我们最近对此类行为的惩罚标准进行了明确。
注意,新政不是禁止用AI。用AI润色、用AI辅助查文献,都没有问题。
但arXiv卡的是另一条线:你有没有认真读过自己署名的论文。
什么算「确凿证据」?Dietterich列了几种典型情形。
幻觉引用,也就是引用了根本不存在的论文。
LLM元评论残留,比如稿件里留着「这是一段200字摘要,是否需要修改?」之类的字样。
占位符未填,比如表格里还写着「请用实验真实数据填入此处」。
如果正式提交的论文里还存在这些低级错误,只能说明作者十分粗心,根本没有认真检查自己的论文。
这样的证据被抓到,也意味着论文中的其他内容并不值得信任。
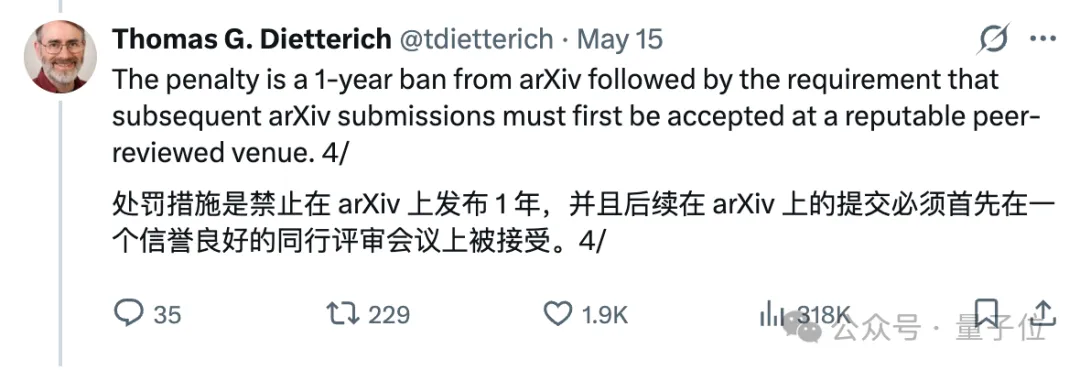
一旦被查实,后果是被arXiv封禁一年,解封后的所有新投稿须先通过正规期刊同行评审才可上传。
而且封号连坐,所有署名作者一起受罚。
Dietterich表示,这是个「一击即止」的规定,但作者可以提出申诉。
内部流程上也会先由版主记录问题,然后由分区主席确认后才能实施处罚。
不得不说,arXiv这次虽然惩罚的都是低级错误,但出手确实挺狠的。
陶哲轩附议:论文生成远比消化容易
新政太火,陶哲轩也闻讯赶来建言献策。
他在Mastodon上发了一组帖子回应此事,用自己在一次演讲中提出的四条建议作为框架,逐一对照arXiv新政。
这四条建议分别是:
1、在传统工作流中明确并严格执行AI辅助的许可边界;
2、降低对「抢先发表」和「仅仅解决问题」的强调,转而重视「消化成果」;
3、为重度使用AI的贡献者设计新的挑战,使其仍然能产生真实学术价值;
4、无论传统还是非传统工作流,都要明确说清项目目标(包括显性和隐性目标)及其背后的原因。
他的总体判断是:新政与前两条建议高度契合。
arXiv这次划定的责任边界,正是建议一的落地,明确了什么叫「许可范围内的AI辅助」。
而整个新政背后的逻辑,对应的正是建议二的核心主张。
他抛出了一个关键判断:在这个时代,生成一篇论文远比消化一篇论文容易。
任何将传统科学机构的平衡重新倾向于消化的努力,都是值得欢迎的。
至于建议三,陶哲轩认为已经有了自然出口。
viXra等平台对AI辅助投稿几乎不设限,可以作为未经消化内容的独立存档地。
但他的定性也很清楚:这类平台专注于「生产」而非「消化」,不应被纳入正统学术引用链,不应出现在arXiv或期刊的参考文献里。
换句话说,想靠AI批量产出论文的人,有地方去,但别想进正统学术体系。
不过,有网友在帖子下留言指出,这个「出口」已经堵死了。
viXra自己也禁止了AI生成论文,并另建了ai.viXra.org专门接收此类内容。
建议四则指向了一个更根本的问题:预印本平台究竟为谁服务?