AI推理大战,OpenAI换了一把“枪”华尔街日报
人工智能推理市场正在经历一场深刻的范式转变——速度,而非智能,正成为开发者愿意为之付费的核心变量。这一偏好的逆转,将长期处于边缘地位的芯片公司Cerebras推向了聚光灯下,也让OpenAI斥资数百亿美元押注一家即将上市的晶圆级芯片制造商。
据行业研究机构SemiAnalysis的深度报告,OpenAI已与Cerebras签署总规模高达750兆瓦算力的主协议,潜在扩展至2吉瓦,对应剩余履约义务达246亿美元。
这笔交易的核心逻辑在于:OpenAI旗下GPT-5.3-Codex-Spark模型在Cerebras硬件上可实现每用户每秒2000个token的生成速度,远超基于HBM的GPU集群所能提供的交互体验。与此同时,Cerebras正站在IPO的门槛上,其命运已与OpenAI深度绑定。
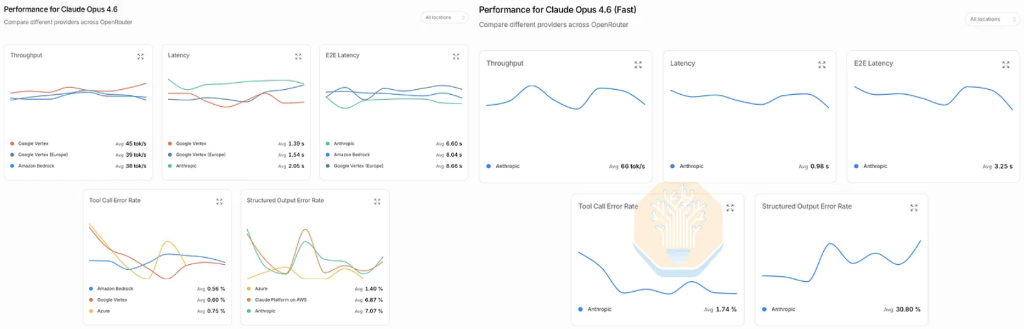
这场速度革命的市场信号已相当清晰。SemiAnalysis披露,其团队80%的AI支出(年化峰值达1000万美元)集中在Anthropic的Opus 4.6快速模式上——该模式以6倍溢价换取2.5倍交互速度。更具说服力的是,当Opus 4.7发布时,团队中多名工程师拒绝升级,原因仅仅是新版本不支持快速模式。这是SemiAnalysis团队首次主动放弃前沿智能,转而选择更快的token生成速度。
速度溢价:开发者用钱包投票
推理市场的竞争格局正在沿着一条新的轴线重新划分。
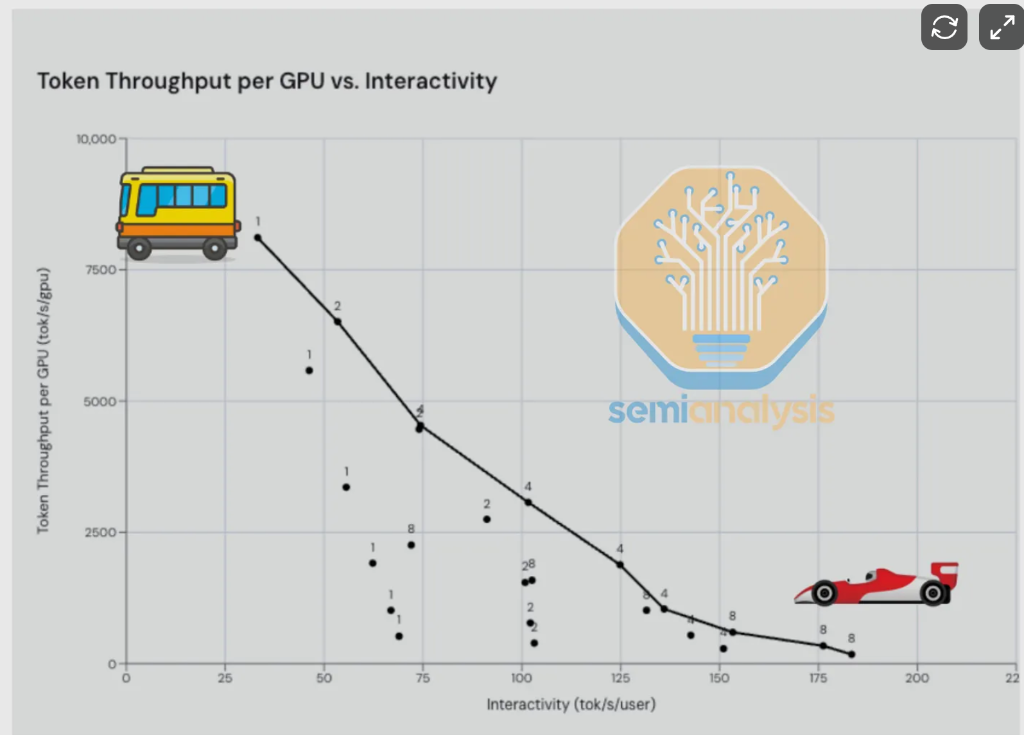
正如英伟达CEO Jensen Huang在今年GTC大会上反复强调的,吞吐量(每GPU每秒token数)与交互性(每用户每秒token数)是推理的根本性权衡——前者服务于批量处理,后者决定用户体验。SemiAnalysis将其比喻为"公共汽车与法拉利"的选择:你可以慢速服务大量用户,也可以快速服务单个用户。
市场的偏好已通过消费行为得到验证。Opus 4.6快速模式以6倍价格换取约2.5倍的交互速度,一度成为Anthropic利润率最高的产品SKU,也是其今年ARR爆发式增长的重要驱动力。然而,SemiAnalysis与OpenRouter合作收集的数据显示,该模式近期已出现性能退化——标准Opus 4.6的交互速度稳定在约40 tps,快速模式曾超过100 tps,但近期已降至约70 tps,实际加速比从2.5倍缩水至约1.75倍。
OpenAI和Anthropic均已意识到这一需求分层,并通过快速模式、优先模式、批量定价等多种产品形态,试图覆盖整个市场并寻找利润最大化的组合点。
晶圆级芯片:一场豪赌的技术逻辑
Cerebras的核心赌注,是突破光刻机单次曝光的物理极限,将整张晶圆做成一块芯片。
其第三代产品WSE-3基于台积电N5工艺制造,在一张晶圆上集成了44GB SRAM,提供21PB/s的内存带宽——比HBM高出数千倍。这一架构的本质是:用极高的内存带宽换取极低的访存延迟,使得在小批量、低算术强度的解码场景下,WSE-3能够充分发挥其理论算力,而基于HBM的GPU在同等场景下往往处于"算力饥渴"状态。
然而,这一架构也带来了显著的计算密度代价。SemiAnalysis指出,WSE-3的稠密FP16算力实际仅为15.625 PFLOPS——这与Cerebras官方宣传的125 PFLOPS相差8倍,差距源于其采用了8:1非结构化稀疏假设,SemiAnalysis将此称为"Feldman公式",并将其与英伟达的"Jensen数学"相提并论,但认为前者走得更远。
在系统成本方面,SemiAnalysis估算每台CS-3服务器的物料成本(含KVSS CPU节点)约为45万美元,远高于其硅片本身约2万美元的台积电晶圆成本。高昂的定制化电源模块(来自Vicor)、液冷系统以及每批次晶圆所需的定制掩膜版,共同推高了整体成本结构。
架构短板:网络带宽的几何困境
WSE-3最显著的弱点,是极为有限的片外带宽。
每块WSE-3仅提供150GB/s(1.2Tb/s)的片外带宽,仅为英伟达Blackwell NVLink5单GPU 900GB/s规模扩展带宽的六分之一。这一限制并非设计疏忽,而是晶圆级架构的内在约束——SemiAnalysis将其称为"岛屿问题"。
问题的根源在于晶圆的均匀步进曝光机制。WSE-3由84个相同的曝光单元(die)拼接而成,每个曝光单元必须完全相同,以确保跨die的片上2D网格互联正常工作。这意味着无法将SerDes PHY集中部署在晶圆边缘——若要增加I/O带宽,就必须在每个曝光单元中都预留PHY面积,而位于晶圆内部的PHY无法连接外部,形成大量"搁浅硅"。此外,PHY模块还会在片上网格中形成"空洞",增加数据路由延迟,削弱晶圆级架构的核心优势。
这一带宽瓶颈直接限制了Cerebras服务大模型的能力。对于参数量超过1万亿、上下文窗口达到百万token级别的现代智能体工作负载,Cerebras不得不采用流水线并行策略,将模型按层切分到多块晶圆上,仅在晶圆间传输激活值。但随着模型规模扩大,所需晶圆数量线性增加,每次晶圆间传输的固定延迟也随之累积,最终侵蚀速度优势。
SRAM扩展已死:路线图的隐忧
Cerebras面临的另一个结构性挑战,是SRAM密度扩展的物理极限。
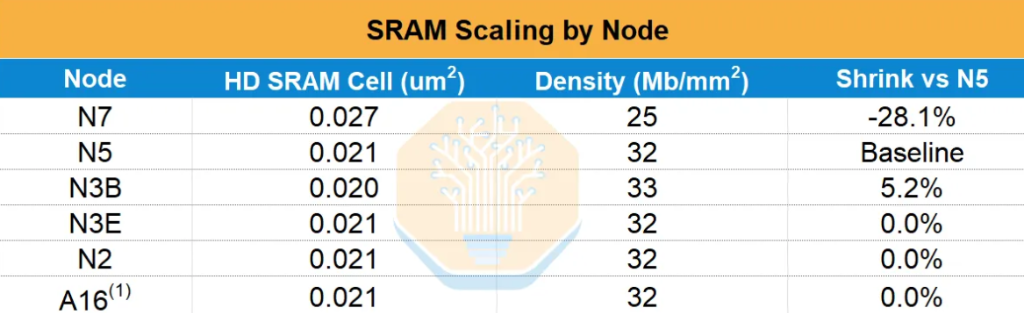
从WSE-1(台积电16nm,18GB SRAM)到WSE-2(7nm,40GB),SRAM容量实现了2.2倍的代际提升。但WSE-3从7nm升级至5nm,SRAM容量仅从40GB增至44GB,增幅仅10%,而逻辑晶体管数量增长了约50%。SemiAnalysis的数据显示,在5nm之后,台积电N3E相对N5的SRAM单元面积几乎没有缩减,N2及后续节点亦然——SRAM扩展实际上已经停滞。
这意味着Cerebras未来提升SRAM容量的唯一路径,是在固定晶圆面积内牺牲计算面积换取存储面积,形成严格的零和权衡。下一代CS-4系统将沿用基于N5的WSE-3,仅通过提升功耗来提高时钟频率和算力,SRAM容量维持不变。
相比之下,英伟达收购Groq后,可通过混合键合技术在Z轴方向叠加SRAM芯片(即LP40路线图),绕开平面扩展的限制。Cerebras也在探索类似路径——将DRAM晶圆或光子互联晶圆通过混合键合叠加在WSE上,但SemiAnalysis对其技术可行性和时间表持审慎态度,认为晶圆级混合键合面临的热机械应力和键合波挑战远比常规芯片复杂。