龙虾之父自曝token账单:130万美元机器之心
是的,你没看错!
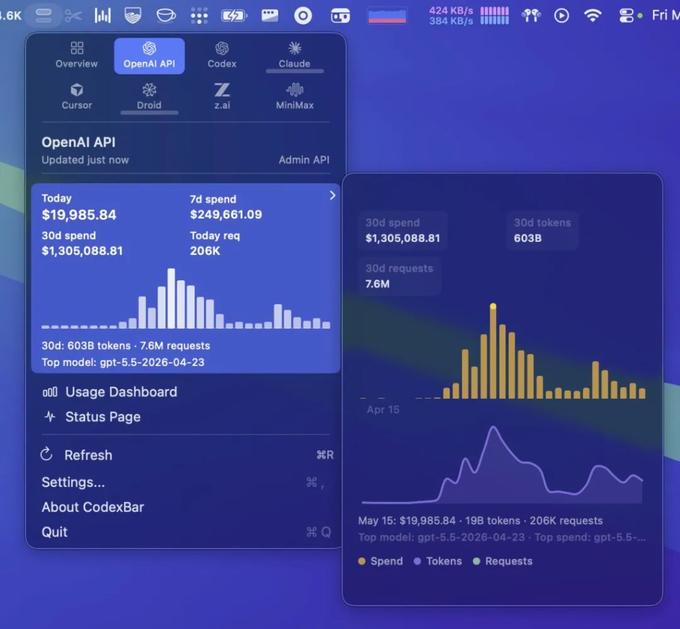
龙虾之父 Peter Steinberger 一个月的 API token 花费金额竟然高达 130 万美元+。
可以看到,30 天总 token 消耗量为 6030 亿,请求量 760 万,
网友惊呼,「雇佣一支开发团队可能都比这便宜。」
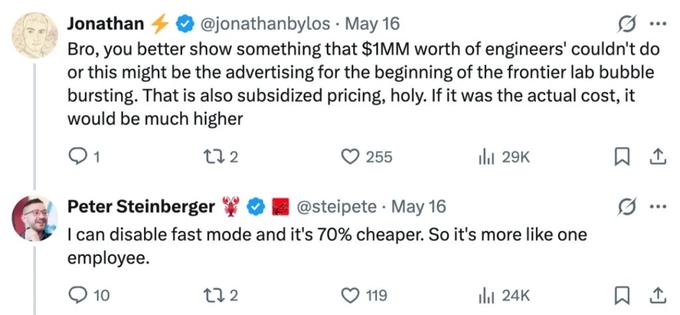
另一位网友追问道,「兄弟,你最好能亮出点真本事,做出那些百万美元年薪的工程师都搞不定的东西,不然这广告恐怕就成了前沿实验室泡沫开始破裂的信号了。而且这价格还是补贴过的。天哪,要按实际成本算,那得贵得多。」
Steinberger 回复称,「我把快速模式关掉,价格直接便宜了 70%,所以算下来也就一个员工的成本。」
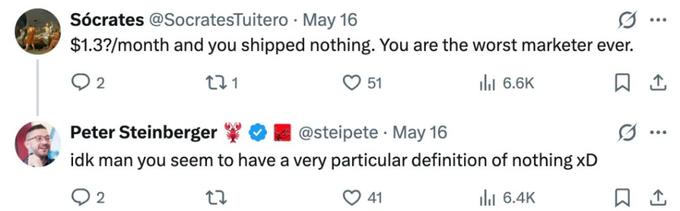
还有人直接开嘲,「一个月 130 万美元?结果你啥都没交付。你真是史上最差劲的营销鬼才。」
Steinberger 同样予以回击,「说不好啊兄弟,你这『啥都没交付』的定义未免也太特别了吧。」
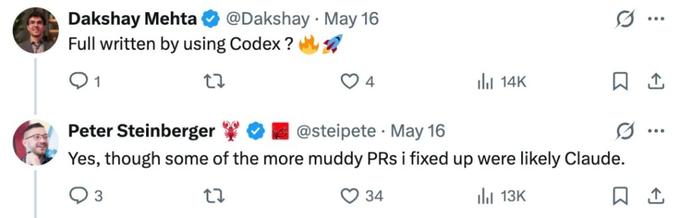
Steinberger 还表示,「这些代码全是用 Codex 写的。那些比较乱、我后来整理过的拉取请求,大概是 Claude 写的。」
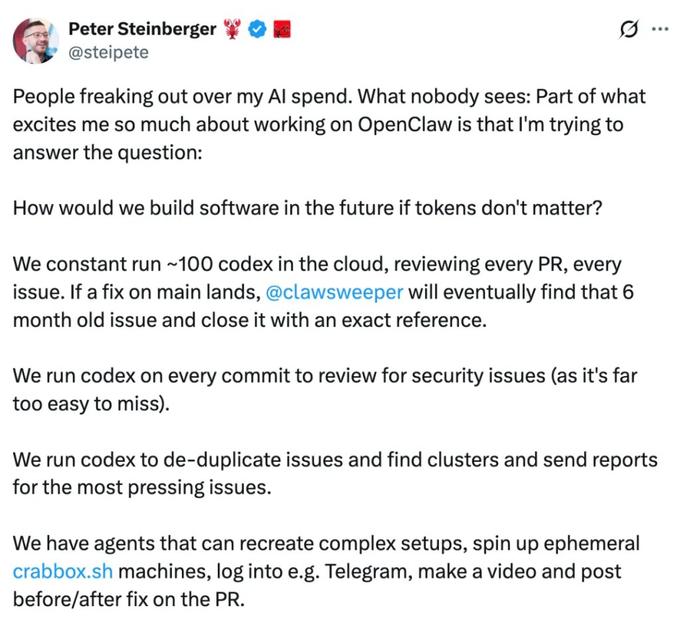
在自曝高昂的 token 花费并引发热议之后,Steinberger 很快做出了回应,他说他正在尝试回答这样一个问题:
「如果 Token 不再重要,未来我们会如何构建软件?」
我们长期在云端运行大约 100 个 Codex,审查每一个 PR、每一个 issue。只要 main 分支上合入了一个修复,@clawsweeper 最终就会找到那个已经挂了 6 个月的旧 issue,并带着精确引用把它关闭。
我们会在每次 commit 上运行 Codex,审查安全问题,因为这些问题实在太容易漏掉。
我们会用 Codex 对 issue 去重、发现聚类,并为最紧迫的问题发送报告。
我们有一些 Agent 可以复现复杂环境,启动临时的 crabbox.sh 机器,登录到 Telegram 之类的平台,录制视频,并在 PR 中发布修复前后的对比。
还有一些 Codex 会监控新 issue,如果它符合我们已经写明的产品愿景,就会自动为它创建 PR。随后,另一个 Codex 会再去审查这个 PR。
我们还运行 Codex 来扫描评论中的垃圾信息,并封禁相关用户。
我们运行 Codex 实例来验证性能基准,并把回归问题报告到 Discord。
我们有 Agent 监听我们的会议,并主动开始工作。比如,当我们在会议中讨论新功能时,它们会在我们讨论的过程中直接创建 PR。
我们构建了 clatch.ai,把所有项目拆分成功能单元,用来审查、发现 Bug 和回归问题。
在安全方面,我们也做了同样的拆分,并结合 Vercel 的 deepsec 和 Codex Security 来发现回归与漏洞。
所有这些自动化,让我们能够以极其精简的团队运转这个项目。
问题来了,这么高的开销由谁来承担呢?显然不是他自己。
「OpenAI 不会收取我的 token 费用。」
Tokenmaxxing:这场吞吐量竞赛还能维持多久
这直接杀死了比赛。
前段时间 AI 圈热议的 Tokenmaxxing ,各大厂商,包括 Meta 和亚马逊,甚至公开公司内部的 Token 使用排行榜,让使用人工智能工具,消耗 Tokens 成了员工每日工作的 KPI。
在当时,Meta 排名第一的个人用户平均消耗了 2810 亿 token,根据不同模型的定价,背后可能是数以百万计美元开销。而龙虾之父 Peter Steinberger 在一个月的时间里就消耗了 6030 亿 token,简直是降维打击。
前特斯拉和 OpenAI 科学家 Karpathy 在播客中坦言自己也感受到最大化使用 AI 的压力,「关键在于 token。你的 token 吞吐量是多少?你能调动多少 token 吞吐量?」
Token 慢慢变成了一种新的生产资料,甚至变成了是衡量 AI 运转密度的单位。一个团队,只要拥有足够高的 token 吞吐量、足够完善的任务拆分方式,以及足够可靠的验证闭环,就可能跑出过去大型团队才能承担的工程密度。
就在刚刚,OpenAI 总裁 Greg Brockman 发推表示,「Token 正在迅速成为解决问题的通用输入。」
但我们相信 Token 并非以量取胜,就像龙虾之父搭建智能体自动化开发流,一个良好的项目管理模式,或许是决胜关键。