Shannon没有想到的事:信息论遇上有限算力AI-lab学习笔记
从一个日常经验开始
你有没有过这种体验——
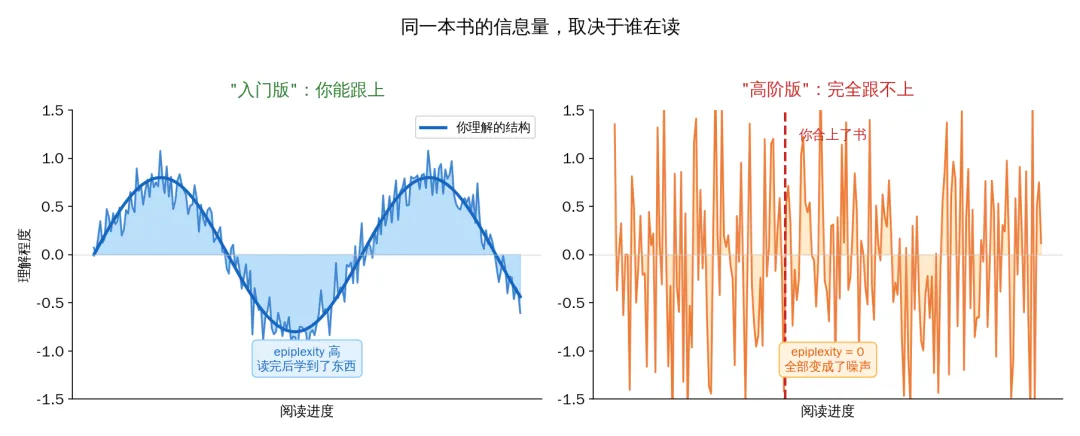
打开一本教科书,前三页还能跟上,到第四页突然看不懂了。每个字你都认识,但连在一起就变成了噪音。你翻回去重读,还是不行。于是你合上书,换了一本"入门版",同样的知识换一种讲法,突然就懂了。
信息没有变。书里写的还是同一件事。变的是你能不能处理它。
现在问一个稍微奇怪的问题:那本你看不懂的教科书,对你来说,信息量是多少?
Shannon 的信息论会说:和入门版一样多。信息量是数据本身的属性,和谁在读无关。
但你的直觉说:不对。那本我看不懂的书,对我来说信息量接近于零——因为我什么都没学到。
你的直觉是对的。Shannon 的理论也没错。矛盾出在一个被忽略了 78 年的假设上。
同一本书,不同的读者
Shannon 漏掉了什么
Claude Shannon 在 1948 年创立了信息论。这是 20 世纪最伟大的数学成就之一——它定义了"信息"是什么,证明了压缩、预测和理解在数学上是同一件事,奠定了整个现代通信工业的基础。
我在之前的 信息论文章 里花了一整篇来讲这件事,在 开篇语 里把"压缩即智能"这五个字当作这个系列的基石。
但 Shannon 解决的问题是通信——我这端有一段数据,怎么通过一根嘈杂的电话线传到你那端,不丢失、不出错。
对这个问题来说,"谁在收"不重要——你是人还是机器,收到的比特数是一样的。所以 Shannon 隐式地假设了观察者有无限的计算能力。这个假设在通信领域完全无害,甚至很优雅。
但今天的核心问题变了。不再是"怎么传数据",而是——
给一堆数据,能从里面学到多少有用的东西?
这是一个根本不同的问题。在这个问题里,"谁在学"变得至关重要。同样的数据,GPT-2 和 GPT-4 学到的东西不同;人类和 LLM 学到的也不同。甚至同一个人,精力充沛和疲惫不堪时,从同样的数据中学到的也不同。
Shannon 的框架里,没有地方放"学习者的能力"这个变量。
78 年来这不是问题——因为我们主要在做通信。但自从 LLM 出现,这个缺失就开始挡路了。
2026 年 1 月,CMU 和 NYU 的六位研究者(Finzi, Qiu, Jiang 等人)在一篇名为 "From Entropy to Epiplexity" 的论文中(arXiv: 2601.03220),正式补上了这个缺口。
在讲他们怎么补的之前,我想先让你感受一下这个缺口到底有多大。
三个让人不安的事实
事实一:从"无"中创造"有"
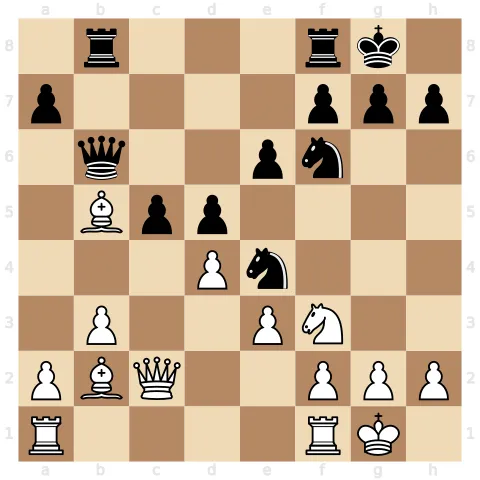
2017 年 12 月 5 日,DeepMind 发了一篇论文。AlphaZero——一个从零开始、仅靠自我对弈的 AI——用 4 小时学会了国际象棋,然后击败了人类花 40 年调教出来的最强引擎 Stockfish。
AlphaZero 的输入是什么?国际象棋的规则——几百行代码,几 KB 大小。它的输出?需要数十兆字节权重才能存储的超人棋力。那些前所未见的弃子攻击、匪夷所思的开局创新——象棋界的人看到后说"这不像机器下的棋,这像是来自外星文明"。
问题来了:这些知识从哪里来的?
Shannon 的信息论说:确定性变换不能增加信息。规则进去,规则出来,信息量守恒。AlphaZero 没有从外部获取任何数据。所以按 Shannon 的理论,它不应该产生新信息。
但几十兆字节的超人棋力,显然不是"没有新信息"。
AlphaZero 的棋局:从简单规则中涌现的超人直觉
事实二:顺序不应该重要,但它重要
论文里引用了一段 Ilya Sutskever(OpenAI 联合创始人)的话,让我印象很深:
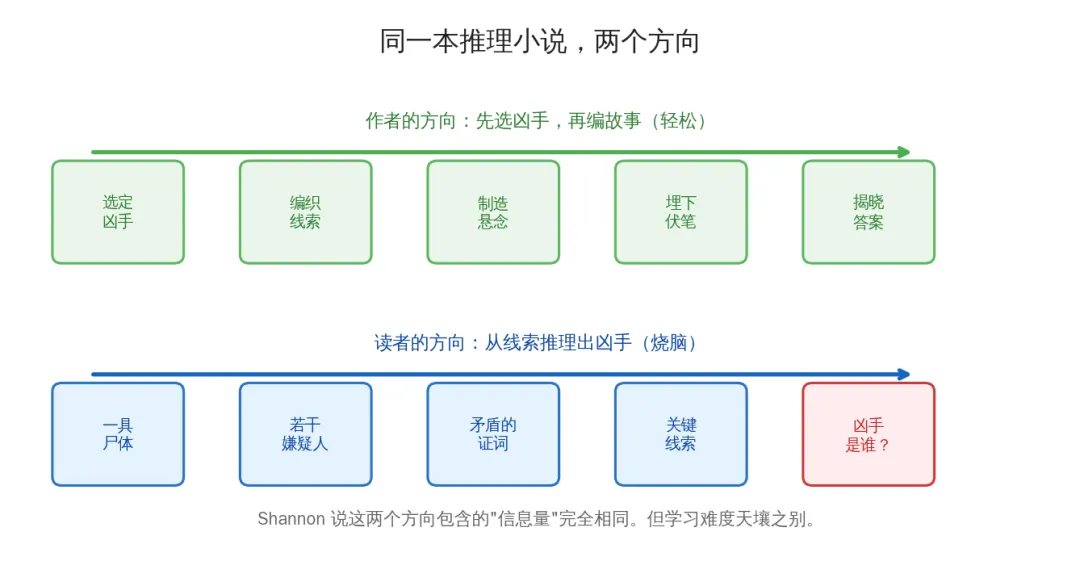
"你在读一本推理小说。读到某一页,文字揭示了凶手的身份。如果模型能预测出那个名字……那它一定是从前面的线索中推理出了谁是凶手。"
但写书的人不需要做这个推理。作者先选好了凶手,再倒过来编织线索。写作方向和阅读方向是反的——一个轻松写意,一个烧脑至极。
写作方向和阅读方向是相反的——一个轻松写意,一个烧脑至极
同样的故事,从结局倒着读,和从开头正着读,包含的"信息"一样吗?
Shannon 说:一样。信息量和顺序无关,这是信息论的基本性质。
H(X, Y) = H(X) + H(Y|X) = H(Y) + H(X|Y)
但做 LLM 训练的人都知道:英语文本正着建模比倒着建模效果好得多。更极端的例子——两个大素数 p 和 q,算乘积 N = p × q 一秒搞定;反过来给你 N 让你分解?整个密码学工业建立在"这件事算不出来"的基础上。
同样的信息,调换一下方向,学习难度天壤之别。
事实三:学生可以比老师更聪明
Conway 的生命游戏——可能是最著名的"涌现"案例。规则简单到只需要三行:
对每个细胞: 活邻居 = 3 → 活 活邻居 = 2 且自己活 → 活 否则 → 死
但从这三行规则出发,会涌现出"滑翔机"(一种会斜向移动的结构)、"枪"(周期性发射滑翔机的装置)、甚至理论上的通用计算机。
Conway 的生命游戏:Gosper 滑翔机枪——简单规则涌现复杂行为
如果你训练一个 LLM 来预测生命游戏的演化,它必须学到这些涌现概念——否则它没法做出好的预测。但这些概念完全不在那三行规则里。
模型学到的内部程序,比生成数据的程序复杂得多。这违反了"模型最多只能学到数据源的水平"这个直觉。
同一串数字,你看到了什么?
这三个事实指向同一个裂缝。要理解它,先看一个你每天都在经历的现象。
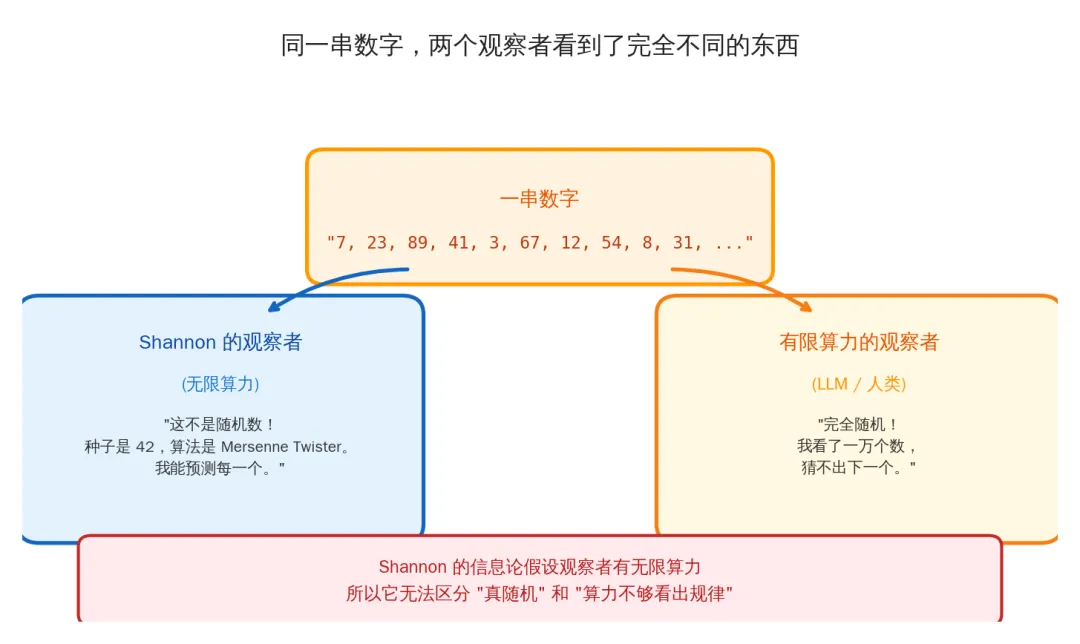
你手机上的每一次加密通信——微信消息、银行转账、HTTPS 网页——都依赖伪随机数生成器。原理很简单:给一个短短的"种子"(比如数字 42),通过确定性算法,吐出一长串看起来完全无规律的数字。
如果 Shannon 本人来看这串数字,他会说:信息量等于种子的长度,几十个 bit 而已。因为存在一个程序能完美重现整个序列——种子加算法,搞定。
但如果你把这串数字交给世界上最强的 AI,让它看前一万个数字,预测第一万零一个?
不是模型不够大,不是训练不够久。而是在有限时间内,不存在任何算法能区分这串伪随机数和真正的随机数。这是现代密码学的基石——如果谁能做到,你的银行账户、你的微信聊天记录、全世界的加密系统,全部裸奔。
同一串数字,两个观察者看到了完全不同的东西
对有无限算力的 Shannon 观察者:这串数字几乎不包含信息(一个短种子而已)。