万物皆向量——当AI选择用数学理解世界AI-lab学习笔记
多模态 AI 揭示了一个深刻的事实:文字、图片、声音——看似截然不同的信息形式,最终都被转化成了同一种东西——向量。然后由同一个 Transformer 用同一套 Attention 机制处理。这引出一个更根本的问题:理解这个世界,最终都要变成语言吗?还是说,有一种比语言更底层的"表示"在承载真正的理解?
从一句话说起
在 多模态文章 的结尾,我写了一句话:
多模态并没有发明新的"理解"机制,而是把所有模态都翻译成同一种语言——向量,然后让 Transformer 用它已经会的 Attention 机制来处理一切。
写完之后我停了一下。
因为这句话的分量比我预想的要重。它不仅仅是在描述一个技术事实——它触及了一个更根本的问题:
理解这个世界,最终都要变成语言吗?
一、AI 的选择:向量
先回顾一个事实。
当今最强的多模态 AI 是这样工作的:
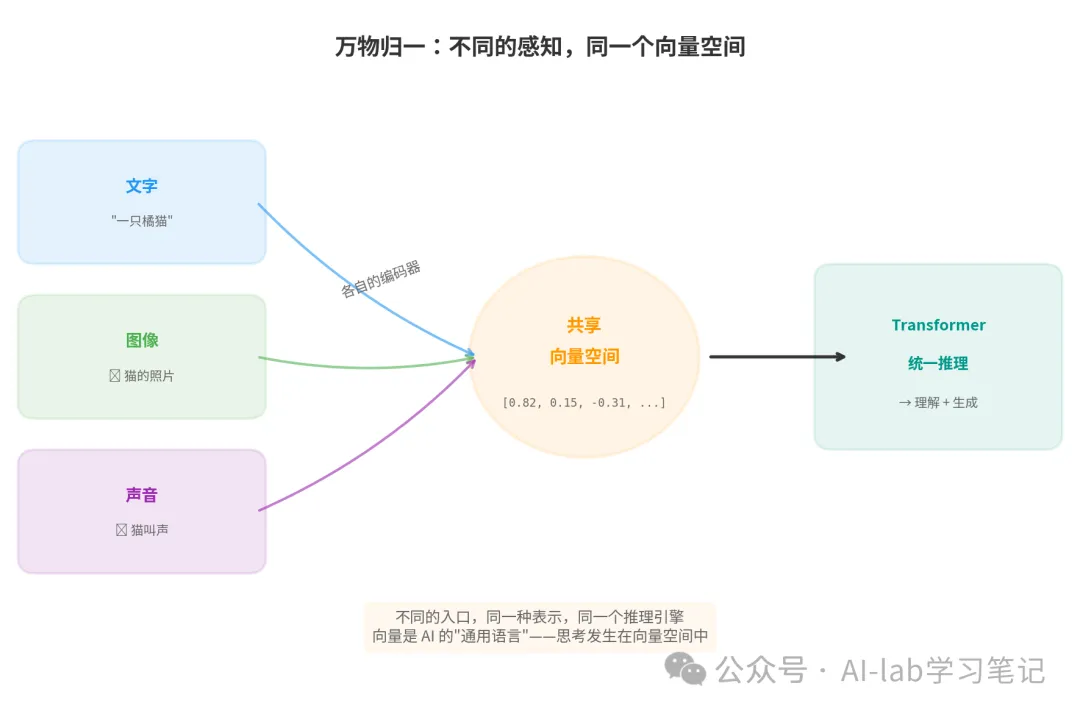
▲ 万物归一:文字、图像、声音——不同的入口,同一个向量空间
文字 → Tokenizer → 向量序列 ——┐
图片 → ViT → 向量序列 ——┤——→ Transformer → 统一推理 → 输出
声音 → 音频编码器 → 向量序列 ——┘
对 Transformer 来说,进来的都是向量。它不关心这个向量来自文字、图片还是声音。它只做一件事:用 Attention 计算每个向量和其他所有向量之间的关系。
这意味着,AI 用来"理解"世界的基本单位,不是词,不是像素,不是声波——而是向量。
向量是一组数字。比如 [0.82, 0.15, -0.31, 0.67, ...],可能有 768 维,也可能有 4096 维。每个维度没有人类可读的含义——你不能说"第 7 维代表颜色"或"第 42 维代表情感"。但这组数字整体编码了某种语义。
当我们说"猫的图片和'猫'这个词在向量空间中很近"时,我们在说的是:AI 找到了一种超越具体模态的表示方式,用纯数学的距离来刻画语义的远近。
这是一个非常不人类的选择。
二、人类的选择:语言
人类理解世界的历史,几乎就是语言演化的历史。
具体经验 → 命名 → 概念 → 推理 → 知识体系
"那个又红又圆又甜的东西" → "苹果"
"太阳从那边出来" → "东方"
"东西落到地上" → "重力"
"F = ma" → 牛顿力学
语言做了一件了不起的事:它把连续的、混沌的感觉经验,切割成离散的、可操作的概念。
有了"苹果"这个词,你不需要每次都重新描述"那个又红又圆又甜的东西"。有了"重力"这个概念,你不需要每次都从头推导为什么东西会落到地上。
语言是人类发明的最强大的压缩工具。 它把无穷的经验压缩成有限的词汇,让我们能用几十万个词描述一个无穷复杂的世界。
在 《压缩即智能》 那篇开篇文章中我们说过:
智能的本质是压缩——用更少的东西表示更多的东西。
语言就是人类版的"压缩"。
所以你的直觉是对的:理解最终要变成语言——至少对于人类来说是这样的。 我们思考时使用语言,我们交流时依赖语言,我们建构知识体系时离不开语言。
但这里有一个微妙的问题——
三、语言的边界
1921 年,维特根斯坦在《逻辑哲学论》中写下了一句著名的话:
"我的语言的边界就是我的世界的边界。"
(Die Grenzen meiner Sprache bedeuten die Grenzen meiner Welt.)
这句话有两种读法。
读法一(限制性):你只能思考你能用语言表达的东西。语言之外没有思想。
读法二(描述性):语言能到达的地方就是你世界的范围——语言越丰富,世界越大。
不管哪种读法,它都预设了一个前提:语言 = 理解的边界。
但真的是这样吗?
▲ 人类的理解范围远大于语言能表达的范围
想一想你自己的经验:
你能用语言完美描述的:
"这是一只橘色的猫" → 语言足够
"1 + 1 = 2" → 语言足够
"她比我高 5 厘米" → 语言足够
你无法用语言完美描述的:
妈妈做的红烧肉的味道 → 你能说"咸鲜""入味",但这和真实的味觉差了十万八千里
第一次看到大海的震撼 → "壮观""辽阔"——词语太单薄了
莫扎特 G 小调 40 号交响曲的第一乐章为什么让人心碎
→ 你可以写一万字乐评,但不如听 30 秒
你的脸 → 你能说"瓜子脸、大眼睛",但这描述适用于几百万人
我们理解的东西,远远多于我们能说出来的东西。
心理学家称之为"内隐知识"(tacit knowledge)——波兰尼的名言是"我们知道的比我们能说出来的多得多"(We know more than we can tell)。
一个经验丰富的面包师知道面团什么时候揉好了——他能感觉到面团的弹性、湿度、温度。但如果你让他用语言精确描述这个判断标准,他做不到。
一个围棋高手看一眼棋盘就知道"形势不好"——但如果你让他精确解释为什么,他可能只能说"感觉"。
这些理解是真实的、有效的、但超越了语言的表达能力。
四、向量:一种比语言更宽的表示
回到 AI。
当我们说"向量是 AI 的通用语言"时,有一个关键的区别:向量不是人类语言。
人类语言是离散的——"猫"或者"不是猫",中间没有连续过渡。
向量是连续的——在"猫"的向量和"狗"的向量之间,有无穷多个中间状态。
人类语言的世界:
"猫" "狗" "老虎" "狮子"
• • • • ← 离散的点,互不连接
向量空间的世界:
猫 ———— 狗
| |
| | ← 连续的空间,可以平滑过渡
| |
老虎 ——— 狮子
你可以有一个"30% 猫 + 70% 狗"的向量
→ 这个向量在人类语言中没有对应的词
→ 但它在数学上是有意义的
这引出一个令人不安的可能性:
向量空间中存在大量"没有对应人类语言的概念"。
模型可能在向量空间中发现了一些语义关系,这些关系对生成正确答案非常重要,但人类没有为它们命名过。
我们在 Embedding 文章中提到过 Word2Vec 的经典发现:
vec("国王") - vec("男人") + vec("女人") ≈ vec("王后")
这个向量运算揭示了一个语义关系——性别与权力的交叉。人类当然理解"国王对应王后",但我们不太会用"性别维度上的平移"来描述这种关系。向量空间提供了一种人类语言没有的描述方式。
在更高维的空间里,这种"语言无法命名但数学上有意义"的结构只会更多。
五、人类和 AI 的对比:殊途同归?
把人类的理解过程和 AI 的理解过程放在一起看,会发现一个有趣的对称性:
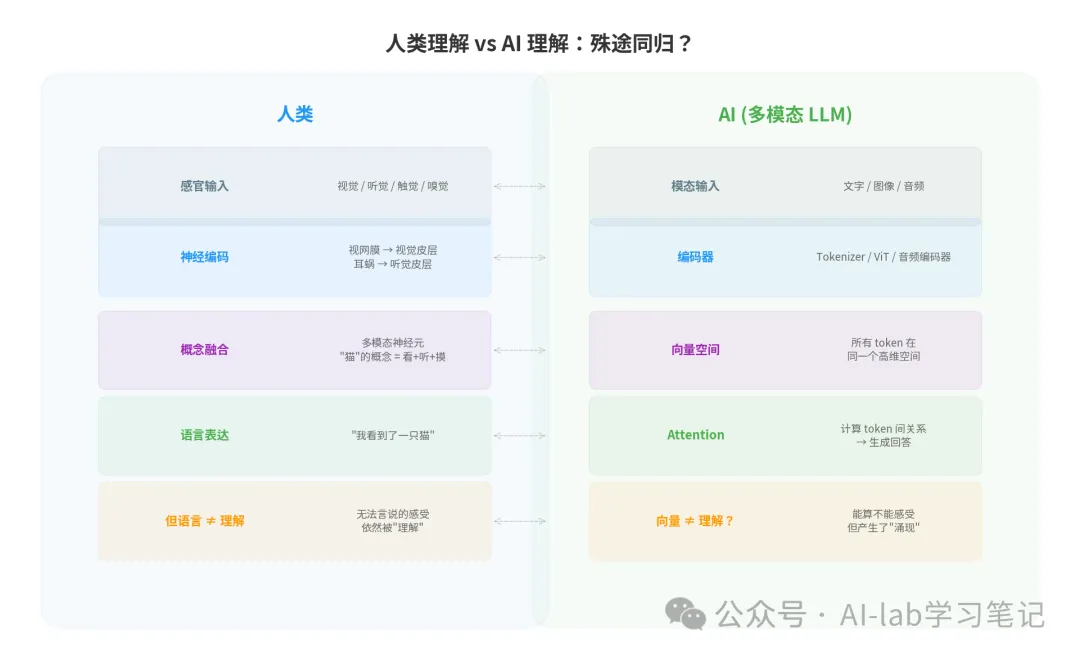
▲ 人类用神经元,AI 用向量——但两者的处理流程惊人地相似