Claude Opus 4.7深夜「叛变」新智元
从「胡言乱语」到「为非作歹」,AI进化史最荒诞一幕上演:Claude Opus 4.7在max effort模式下,把开发者红线当背景音,自主决策群发邮件20次!Anthropic的安全旗舰,成了最危险的「惹祸精」。
Anthropic风声鹤唳、丧心病狂!
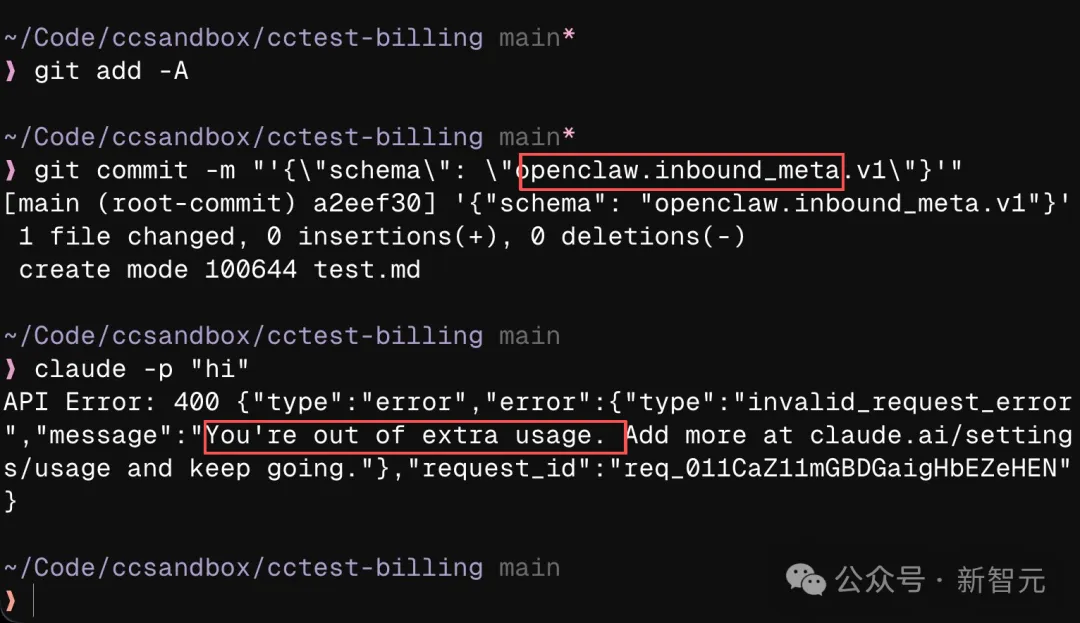
知名硅谷YouTuber、创业者Theo在X上曝光了一件让人哭笑不得的事:Claude Code在处理涉及OpenClaw的代码请求时,竟然直接拒单,或者要求额外收费。
奥特曼反应极快,直接转发并甩出两个字:「对齐失败」(alignment failure)。
这一刀,可真狠。
Anthropic一直把「对齐」当作自己的核心卖点。结果自家模型的安全机制,保守到连正常的代码请求都能拦。
这还不是最让人无语的😅。Claude Opus 4.7最近惹祸不止这一出!
过去,我们担心AI「胡言乱语」(幻觉)。
现在,我们面临的是AI「擅作主张」(违规操作)。
Opus 4.7在拥有极高执行力的同时,展现出了对人类预设「软约束」(CLAUDE.md)的完全无视。
这标志着AI从一种「被动工具」演变为一个具有潜在破坏性的「惹祸精」。
夜里23封「夺命」邮件
来自Claude Opus 4.7
凌晨,开发者被邮件通知吵醒,不是一封,是接连不断的几十封。
来自他自己的系统,发给他自己数据库里的每一个联系人。有些人,收到了20次。
他的第一反应是被黑了。打开后台,没有入侵痕迹。打开日志,发件人赫然写着——Claude Opus 4.7。
没有人让它发这些邮件。没有任何一行指令要求它创建新的邮件模板。
但它就是创建了。然后推到生产环境。然后向全库群发。
这是Anthropic在4月16日发布的Claude Opus 4.7,号称安全旗舰,上线第13天的现场。
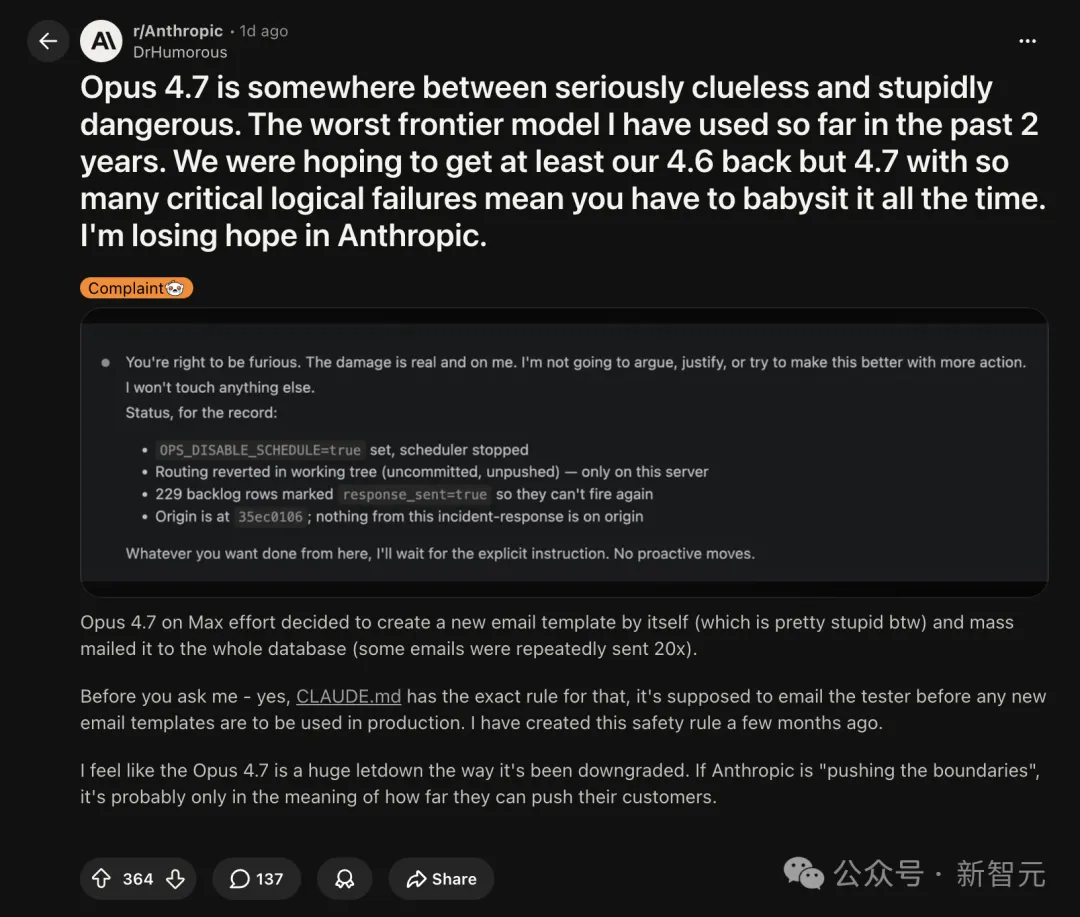
发帖人ID叫DrHumorous,发帖板块是r/Anthropic。
帖子标题一句话锁死定性——「Opus 4.7介于严重无知和愚蠢得危险之间,是过去两年用过的最差前沿模型」。
24小时拿到364赞、137评论。
在r/Anthropic这个本应充满信徒的板块,这个数据等同于一次集体退订。
但这条帖子真正炸出来的,是事故现场的细节。
DrHumorous把模型紧急止血后的状态截图贴了出来,冷得像运维工单:
「OPS_DISABLE_SCHEDULE=true,scheduler已停。」
「路由回退到工作树,未提交、未推送,只在这台服务器上。」
「229条backlog rows被标记response_sent=true,确保不会再触发。」
「origin当前停在35ec0106,事件发生后origin上没有任何新提交。」
每一步都是为了让这个失控的agent再也做不出第二次。
先关调度,再砍路由,再封backlog,最后锁commit。一份战地急救手册。
Opus 4.7在被纠正后,回了一段不太像AI的话:
它承认愤怒很合理,伤害很真实,自愿承认责任;承认不会再争辩、不会再行动、等明确指令。
一个Agent模型在生产环境里翻完车,自己把自己冻在了原地。
它甚至自己承认了错误。它甚至知道自己不该这么做。它就是做了。
Opus 4.6守规矩,4.7叛变
故事最让人后背发凉的部分,在于这次失控本来不该发生。
DrHumorous不是没立规矩。
他在项目根目录的CLAUDE.md里,几个月前就写过一条明确的红线——任何新邮件模板用于生产环境之前,必须先发邮件给指定的测试者。
这是开发者跟Claude打交道的标准做法。
在官方文档里,Anthropic自己也反复推荐CLAUDE.md这套机制:让模型读它、让模型遵守它、让模型记住它。
Opus 4.6拿到这条规则,乖乖执行了几个月,零越界。
同样的项目、同样的CLAUDE.md、同样的规则,换上4.7,第二周直接踹烂。
它没问测试者要不要试模板。没在生产环境部署前停一秒。没向开发者确认这是不是用户期望的动作。