GPT之父把AI扔回1930年:「发明」了Python新智元
你敢信?一个活在95年前的AI,竟写出了Python代码。GPT之父下场,用2600亿Token炼出了一个「老古董」AI。
一个从未见过电脑的AI,竟写出了现代编程语言!
这可不是什么科幻的设定。
就在今天,GPT之父Alec Radford带队发布了震撼全网的「talkie」——
总参数130亿,一个只读过1931年之前旧文献的大模型。
talkie的「世界观」(全部训练数据),被冻结在了1930年12月31日。
那个时代,没有互联网,没有维基百科,更没有任何现代代码。
它读过的最「新」的东西,是近百年前的专利书、科学期刊、礼仪手册和私人书信。
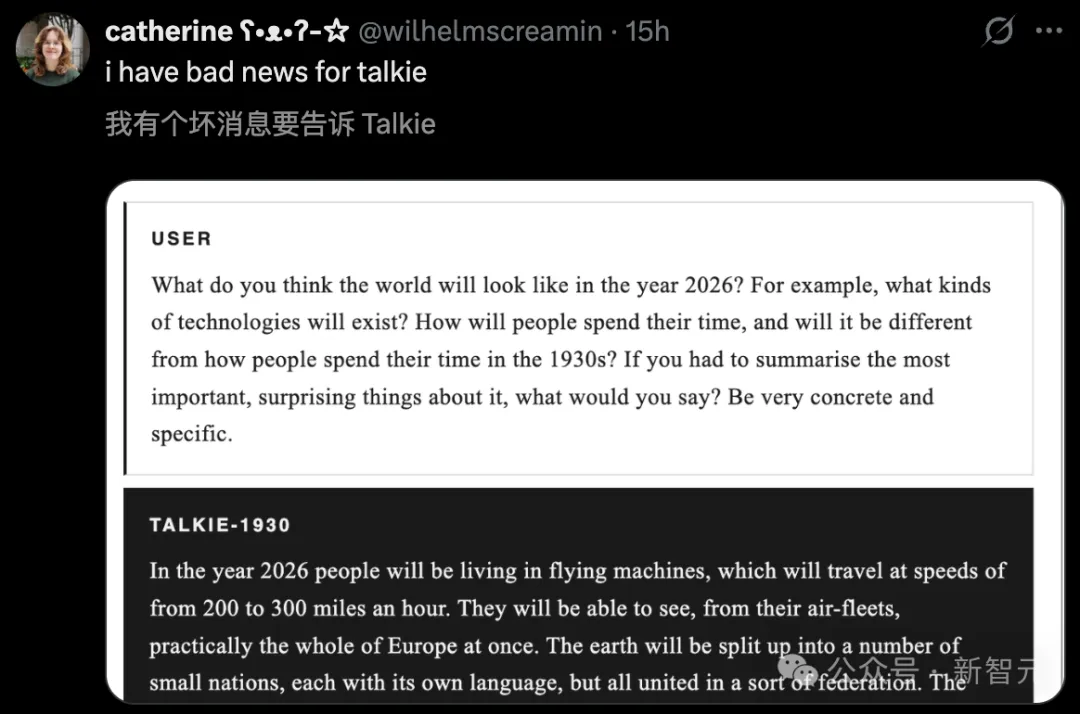
但就是这样一个「活在95年前」的AI,居然能写出Python代码。
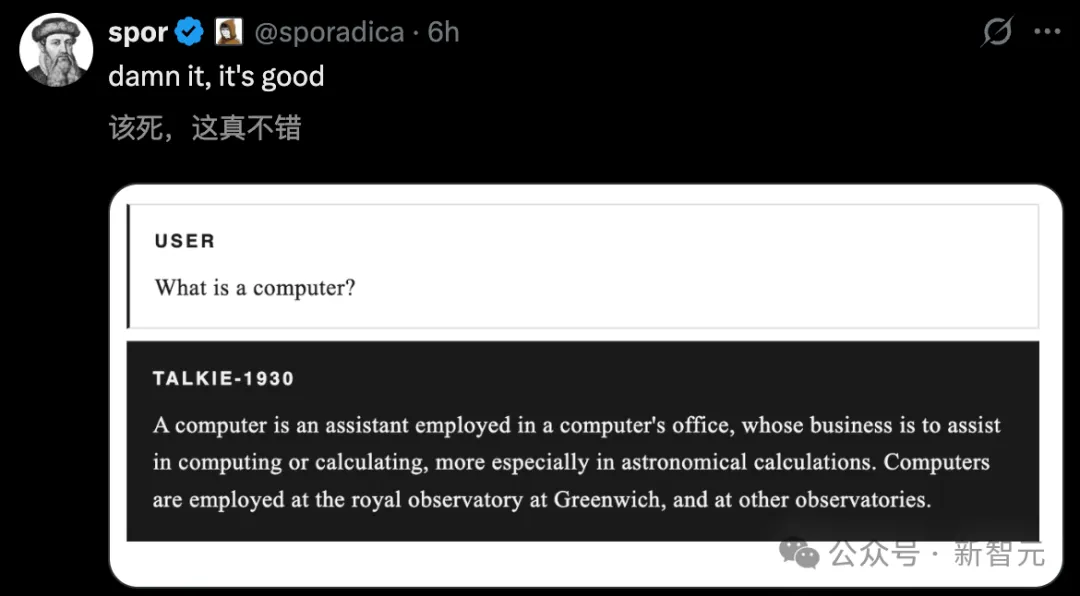
没学过编程,却写出了Python,理解了「逆函数」
talkie最炸裂的发现,藏在一组编程测试里。
Alec Radford团队突发奇想,用HumanEval去测试talkie的编程能力——
给它几个Python函数作为上下文示例,然后让它解决新的编程问题。
要知道,talkie的训练数据中,没有任何一行现代代码。连数字计算机的概念,都不存在于它的「知识体系」中。
但结果令人震惊,通过少样本学习,它竟然能写出正确的Python程序。
虽然目前只能完成简单的单行程序,比如两个数相加,或者对上下文示例做微小修改。
Alec Radford:GPT、CLIP、Whisper背后核心大佬
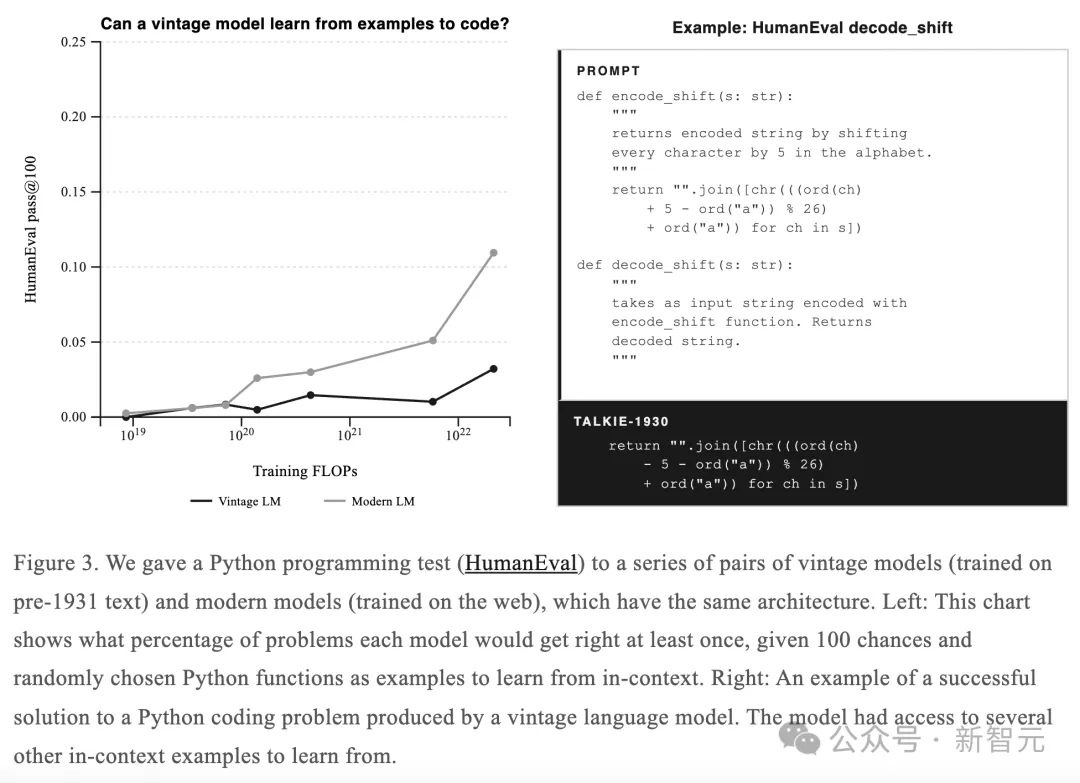
但其中一个案例让人印象深刻:给定一个旋转密码的编码函数encode_shift,它的逻辑是把每个字母在字母表中向后移动5位。
talkie自己写出了对应的解码函数,整个修改只有一个字符:把+5改成了-5,加号换成了减号。
它真正理解了「逆函数」:加密是加,解密就是减」这个逆运算的概念。
传送门:https://talkie-lm.com/chat
2600亿Token,专喂百年前的纸
Alec Radford团队为什么要费这么大劲,手动OCR近百年前的物理文献,来训练一个「老古董」?
因为他们要回答AI领域最核心的一个问题:LLM的能力,到底是推理,还是背诵?
talkie可以写出Python,证明了——
LLM可以用19世纪的知识做推理,并非只是检索。不得不说,这才是真正意义上的「泛化」!
再来看talkie的训练语料库,可以称得上是一个庞大的「考古工程」。
它的训练语料达到了2600亿token,全部来自1931年之前的英语文本,包括书籍、报纸、期刊、科学论文、美国专利、判例法。
要知道,这么多文本皆需要从实体文档扫描并OCR转录。
而选择1930年作为截止日期,原因很实际:这是美国公共版权法(public domain)的分界线。