一家做视频的公司,造了个机器人通用大脑量子位
一家做视频的公司,造了个机器人通用大脑。
这不是段子,是真事。
区别于传统的专用机器人大脑,这个“大脑”既具备世界模型的预测推演能力,又能输出行动指令,真正做到“知行合一”。
大脑模型名叫MotuBrain,4月中旬悄悄登顶两个国际benchmark,却无人知晓来历,让具身圈大佬们猜了三周。
刚刚,生数科技主动认领了。
没错,是那个做了Vidu、让央视动漫用AI拍西游的公司。
两个国际benchmark,一个测试“能不能看懂物理世界”,一个考验“能不能真的动手干活”。
就像一个人一边参加物理竞赛,一边考叉车实操证,4月中旬,MotuBrain两门都拿了全场最高分。
成绩单亮出来,还是实打实的登顶:
在WorldArena上,MotuBrain运动质量第一、动作平滑度第一;
在RoboTwin2.0上,它也是唯一一个在随机环境下,平均分超过95的模型。
这是什么概念?过去几年,能把其中一个测试做到极致已属不易。
同时登顶?之前还没人做到过。
但现在,生数科技告诉你:一个MotuBrain模型就够了。
视频公司跨界指挥机器人,听起来蛮有趣。
实际内里也是大有乾坤:具身智能的未来需要World Action Model(世界动作模型),而后者必须建立在视频模型对物理世界的理解之上。
一段汽车漂移的视频,模型要看懂车为什么拐弯、轮胎为什么冒烟、下一秒会往哪走。
这也不难理解视频公司闯入具身世界背后的逻辑了。
双榜吊打,这个机器人大脑有多强?
MotuBrain悄无声息地同时登顶WorldArena和RoboTwin2.0,不少具身大佬都被这个神秘模型勾起好奇心,疯狂打听到底是谁家做的。
有媒体扒出X平台上倒是有个账号,但刚注册,简介空空。
“子弹”飞了快三周,4月29日,生数科技主动跑出来认领:是我。
回头来看,线索其实早就埋下了。
2025年12月,生数科技正式开源通用基座世界模型Motus,这是其在物理世界智能方向的一次试水。
四个月时间不到,生数又进化了。
MotuBrain作为全面升级的商业模型版本,继承了Motus完整核心技术架构,并完成关键能力突破。
验证实力的第一站:WorldArena。这是业界公认的World Model能力测试场。
它不看你模型生成的视频好不好看,而是看你的模型能不能真正理解物理世界:
一个物体被推一下会朝哪个方向运动?两个物体碰撞后会发生什么?连续动作的轨迹是否平滑、是否符合真实物理规律?
EWM Score是这个榜单的综合评分,Motion Quality、Flow Score、Motion Smoothness这些维度分别考察动作的真实性、连续性和平滑度。
△数据统计截至4月21日
在这三个直接对应“动作质量”的维度上,MotuBrain全部拿下第一。
这意味着它不是靠某个单项指标刷分,而是在物理规律的理解和模拟上做到了全面领先。
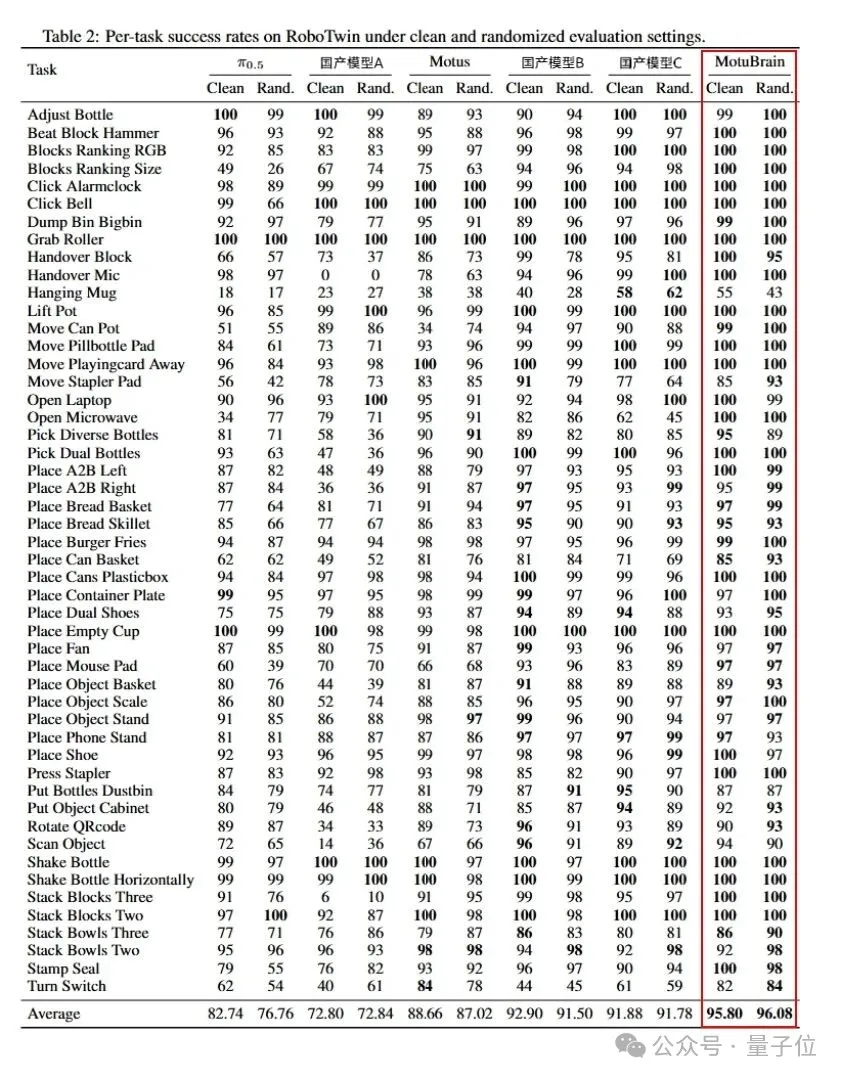
RoboTwin2.0则是Action Model的硬核考场。
它给模型设置了50个不同的任务,覆盖抓取、放置、推、拉、旋转等多种操作类型,还分两种环境进行测试:
一是Clean场景,标准实验室环境,物体位置、光线、背景都是固定的;
二是Randomized场景,会引入随机的扰动,比如物体位置随机偏移,灯光颜色随机变化,甚至桌子角度都可能微调。这考验的是模型能不能泛化到没见过的条件。
MotuBrain在两个场景下,分别达到95.8和96.1,均排名第一。
它也是该榜单上唯一一个在随机环境下,平均分超过95的模型。
拆开50个具体任务看,MotuBrain九成任务超过90分,一半任务更是拿到了满分100分。这已经不是领先了,这叫断崖式领先。
两个顶级榜单,一个测“理解世界”,一个测“在世界中行动”。
想要同时取得成绩,业内默认这是“统一场”级别的难题。
因为两边的技术栈和评估方式完全不同,能把其中一个做到极致就已经是顶级水平。
但MotuBrain双榜吊打,至少在benchmark层面验证了一件事:
把预测世界和驱动行动统一在同一个模型里,这条路是走得通的。
真机演示:AI干活开始“带脑子”了
从榜单成绩看,MotuBrain拥有更接近通用机器人大脑的能力特征,它不是单项任务的“偶然强”,而是跨任务、跨场景的泛化能力都强。
一段真机演示足以直观印证。
从生数科技发布的Demo看,没有复杂的上层VLM加持,也没有预设动作脚本,却将MotuBrain的4个核心能力完整呈现,看完只剩震撼!
这段不足3分钟视频,用3台不同型号的仿人形机器人,演示了5种任务:插花、整理沙发、服务一场火锅局、调酒、整理洗漱台。
没错,MotuBrain的第一个能力就是一脑多型,它不是为某一种机器人量身定制,而是面向多机器人本体设计的统一智能底座。
它在不同形态、不同自由度、不同传感器的机器人上都能跑,而且接入的机器人种类越多,数据和场景越丰富,模型表现越好。
仅从Demo展示的这三台机器人身上,我们也能看到一个模型是怎么拿捏全场景任务的。
插花、整理沙发,别看在这几项任务里算“简单”的,恰恰是最考验长程任务建模能力的操作。
我们能看到,机器人精准抓取三支花,分别稳稳插入花瓶后,顺势拿起浇水壶,对着花枝均匀喷洒清水,整个过程非常丝滑,没有停顿。
也能看到它精准识别出散落的衣物和错位的靠枕,先将衣物逐一拾起、规整放入洗衣篮,再将歪歪扭扭的靠枕摆回原位。
全程动作轻柔且高效,没有出现衣物掉落、靠枕摆放歪斜的情况。
这就是MotuBrain一脑贯通能力的体现。
不同于传统机器人仅能完成2-3个原子动作的Demo展示,MotuBrain的一个World Action Model可完成10个原子动作级别的复杂长程任务。
无论是插花还是整理沙发,机器人面对的不再是一个个孤立动作,而是一项需要持续推进的完整任务。
如果你以为这就够了,先别急着叫好,大招还在后面。
最让人眼前一亮的,当属服务一场火锅局。机器人被要求从锅中舀取一份丸子放入碗中,同时倒一杯果汁。
这一次,它左右手同时“开工”,互不干扰、配合默契。
一个小细节是,起初勺子放在锅里,机器人用左手握住勺柄,没有立刻捞取,而是先判断了一下漏勺中有没有物体,然后重新伸向锅中舀取丸子,盛入面前的碗中。
别小瞧这个不起眼的动作,需要机器人「理解」勺子是空的,同时能自主「预测」并重新执行捞取动作。
多数机器人是“看到什么就做什么”。而在这个取丸子场景里,如果换成传统指令式机器人,它只会按脚本执行“舀→放”的动作。
一旦勺子初始是空的,它要么卡住,要么盲目重复,却不知道“为什么空”。