普林斯顿之姚班刘壮:数据才是王道量子位
引用量超过10万次,清华姚班校友,ConvNeXt、ImageBind、《无归一化的Transformer》……这些论文的作者——
普林斯顿大学助理教授刘壮,在学术圈是一个颇为特殊的存在——他的每一篇论文几乎都在质疑某个“理所当然”的假设。
架构真的重要吗?数据集真的足够多样吗?归一化层是必需的吗?大语言模型有世界模型吗?AI智能体能替代博士生吗?
在《信息瓶颈》的最新播客中,刘壮和主持人Ravid Shwartz-Ziv、Allen Roush展开了长达一个多小时的对谈,解答了这些问题。
刘壮给出了几个核心判断(太长不看版):
1、架构选什么,没你想的重要。
只要把残差连接、自注意力、归一化层、线性层这四大基础做对,不管用ConvNet还是Transformer,最终都会落在同一条性能曲线上。
过去十年真正推动AI进步的,是更大程度上是数据规模和计算规模,而不只是架构创新。
2、数据集远没有我们以为的多样。
他和何恺明做了一个实验:训练神经网络来判断一张图片来自哪个数据集。
结果在三个号称“多样化”的亿级数据集上,准确率高达80% 以上——
说明这些数据集在模型眼里仍然泾渭分明,距离“无偏的全球分布”还差得远。
3、大语言模型有世界模型,但只在语言空间里。
LLM在高层次事件推理上表现出色,但视觉空间的精细世界模型我们还没有——
根本原因是视觉数据的信息密度太高,现有算力还处理不了。
而且对于超过一半的工作场景(尤其是数字化的白领工作),根本不需要视觉世界模型。
4、记忆才是当前最大的瓶颈,不是能力。
现有模型的推理能力已经足够强,真正缺的是稳定的长期记忆。
我们需要那么多智能体协作,恰恰是因为一个智能体记不住所有事情。
5、自主科研还没到位,AI替代不了研究生。
他亲自测试过让Claude Code在一两天内独立完成一个研究项目。
结论是:低层次任务还行,但提出有意思的问题、设计实验、保持方向感——这些还做不到。
整个访谈有一条隐藏的主线:我们在AI领域里奉为圭臬的很多东西,其实是历史偶然。
而真正决定成败的,往往是那些更朴素、更无聊的因素——数据、规模、记忆。
以下是量子位梳理的刘壮最新访谈,为便于理解,有部分删减和润色,并在必要的地方添加了编者注,各位enjoy~
架构没那么重要,但细节决定一切
编者注:2020年前后,计算机视觉领域掀起了一场“Transformer热”。
2020年Google Brain提出的视觉Transformer(ViT)横空出世,整个视觉社区迅速向它迁移,传统的卷积神经网络(ConvNet)被普遍认为已经落伍。
2022年,刘壮团队发表ConvNeXt,把经典的 ResNet 架构一步步“现代化”,最终让它在性能上追平了当时最强的视觉Transformer——结论令人意外:两者的差距并非来自架构本身,而是来自训练方案的不同。
Ravid:今天我们会聊聊你的一些论文。总体上,我们要探讨当今AI中真正重要的组成部分是什么。你的研究成果很多,我想我们可以从“哪些组件最关键”开始。
几年前,你发表了一篇关于“面向2020年代的卷积神经网络”的论文。你能先介绍一下这篇论文,然后我们再来拆解当前AI系统的各个组成部分吗?
刘壮:嗯,当然。那是一段非常有趣的经历。
这篇论文我们是在2021年写的,那时候Transformer刚刚通过视觉Transformer的引入进入了计算机视觉领域,整个视觉社区都在从传统的卷积网络切换到视觉Transformer,性能也越来越好。
在这项工作中,我们想研究:ConvNet是否真的已经丧失了竞争力?
是否有可能通过系统性地控制所有设计细节,来验证ConvNet能否被现代化、达到当时视觉Transformer的水平?
我们想搞清楚,Transformer和ConvNet之间看似存在的性能差距,究竟是源于架构本质的不同——比如用自注意力还是卷积——还是源于一些看似微小的设计细节。
最终我们发现答案是后者。
经过大量对ConvNet各组件的研究,我们最终让模型在多种任务上达到了当时最强视觉 Transformer 的水平。
这说明,无论选择ConvNet还是视觉Transformer,只要把所有细节都做对,就能在视觉任务上达到同等的前沿性能。
Ravid:你现在还相信这一点吗?你还认为架构其实并不重要吗?
刘壮:我不会这么说——总体上我倾向于认同,但我不会说架构不重要。
我的意思是,只要你把所有细节都做对,只要你对设计空间探索得足够充分,就会收敛到一个类似“帕累托前沿”的点——在精度和效率之间取得最佳平衡。
要突破这条前沿线是非常困难的。
我觉得过去这么多年,除了几年前已经成熟的那些架构之外,真正被广泛采用的架构创新其实并不多。
不过这个探索过程本身非常有趣。
最近,一些开源模型公司,比如Kimi、DeepSeek,还在不断折腾架构,比如怎么改残差连接、怎么连接不同层,我非常尊重这类工作。
事实上,学术界现在架构研究没那么活跃,部分原因是我们负担不起用足够说服力的规模来验证这些效果所需的计算资源。
但我自己还是会用学校的资源去尝试。现在有了Claude Code的帮助,我可以自己动手写代码去探索,这非常有趣。
从实用角度来看,我认为我们用什么数据训练模型,比选择什么架构更重要——前提是输入输出接口不变。
架构本质上是我们参数化函数近似器的方式,这是神经网络或深度学习最基本的功能。
只要你把几件事做对,比如用残差连接、用自注意力或其他合理的机制、在合适的位置放激活函数和前馈层,你就能非常接近甚至达到性能与效率的前沿曲线。
从实际应用的角度,我认为更重要的是:这个模型用什么数据训练的?它怎么处理上下文和记忆?
在上下文和记忆这方面,确实有一些架构工作在解决这个问题。
我觉得这才是让AI再上一个台阶最迫切需要解决的问题。
Allen:根据我的理解,你们是把ResNet逐步往类似Swin Transformer的设计方向现代化,最终得到一个能与 Transformer强力竞争的ConvNet。
在那篇论文里,哪一个消融实验最让你对“Transformer的优势究竟从何而来”改变了看法?
编者注:消融实验(ablation study)是深度学习研究中的常用方法,指的是逐一去掉或改变模型中的某个组件,观察性能如何变化,以此判断每个组件的贡献大小。
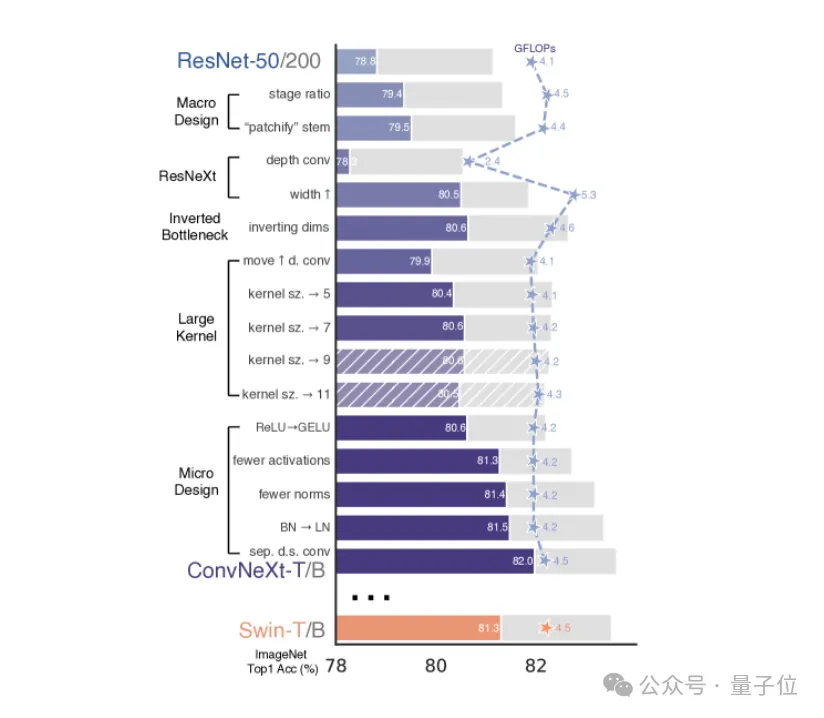
刘壮:哪一个?我觉得是每一个。
你看那张图,没有任何单一改动能大幅拉升性能。有些改动比其他的更有效,但没有哪一个能改变一切。
△ConvNeXt论文的Figure 2,展示了ResNet现代化的完整过程和每一步对应的性能变化
也许激活函数的使用,以及减少归一化层的数量,是让我比较感兴趣、也有明显性能提升的一个点。
但真正起作用的是把所有改动叠加在一起。
这些看似微小的组件,当我们把它们组合起来的时候,产生的性能差距,是那种通常只有把卷积换成自注意力这种大改动才能带来的效果。
所以我认为,这篇论文最大的启示是:这些小细节组合在一起,比那些看起来很核心的网络组件影响更大。
Ravid:对我来说,感觉我们是在大量尝试各种东西,有些起效了,模型就变好了。然后回过头来,我们才开始真正理解哪些组件是关键的。
你觉得我们是需要先有突破,再回头理解细节?还是说我们只需要反复试错,不需要明确的方向?
刘壮:Transformer对整个社区来说绝对是一个福音,把Transformer引入计算机视觉这件事,意义重大。
是那几年里绝对是最重要的突破之一。
但视觉Transformer还有另一个好处,就是它实现了文本和图像表示的统一。
Transformer的使用对后来的发展非常关键,比如LLaVA,这类多模态框架——用视觉编码器把图像编码成token,然后和文本 token 一起输入到下游的大语言模型里。
这是现在很多多模态模型的基本框架。
编者注:LLaVA(Large Language and Vision Assistant)是2023年提出的一种多模态大语言模型框架,将图像编码器(通常是CLIP)和大语言模型(如LLaMA)连接起来,让模型能同时理解图像和文字。
这一框架成为后来GPT-4V、Gemini等多模态模型的基础思路。
回到我们的研究,这种对细节的深入分析,我觉得更像是一堂课。它改变了我自己的认知,也改变了很多人的认知,这让我更引以为傲。
当然人们还是可以继续用ConvNet,它也有自己的优势,尤其是在纯视觉任务里:部署方便,比较容易理解,也因为操作是局部的,所以对更高分辨率和长序列有更好的支持。