清华团队预言:90%的人将脱离谋生劳动新智元
清华沈阳团队揭示自进化AI的秘密与实施路线。沈阳团队站在2026年中点,抛出四大颠覆判断:AI正走向「人机隔离」而非协同;未来公司只剩一人甚至零人;检验比生成更重要;AGI将制造「多版本现实」。团队日耗Token破百亿,AI七天七夜自研压缩算法登顶榜首,「超级个体」正在溶解传统组织。这不是预言,而是正在发生的现实。本文综合清华沈阳教授在清华校庆日的演讲、记者采访和研发进展采写。
站在2026年的中点,AI正以超越大多数人认知的速度演进。
清华大学知名跨学科学者沈阳教授(先后在计算机、信息管理、新闻传播、人工智能、临床医学等学科担任教授或博士后合作导师)及其团队,基于长期的人机共生和「AI for AI」研究与实践,提出了四个正在发生的范式转移。
它们不再是遥远的预言,而是正在浮出水面的现实。
引言:四大颠覆观点,重估人机关系
第一个颠覆观:AI正在走向「人机隔离」
我们总说「人机协同」,但像OpenClaw这样的框架,其核心哲学是「赋予AI绝对权力」,让它自我进化,未来可能不再需要人类时刻参与。
这不再是协作,而是放手。
OpenClaw的理念与中国人强调的「人机协同、驾驭AI」的控制哲学有根本不同,它标志着AI发展史上第三个大阶段的正式开始——从「能聊天」到「能干活」,再到「能独立干活」。
第二个颠覆观点:未来的公司,可能只剩一个人或没有人
不是裁员,而是形态重构。
企业将演变为由「超级个体」和AI数字员工构成的「自进化组织」。普通岗位将大幅减少,AI转型的关键不是招更多人,而是培养超级个体,并给他们配备更多的电脑和算力。
沈阳教授预言,最好的企业将是由一群有共同理想的超级个体构成的自组织、自进化、自适应的组织。一人公司这个人是CEO,零人公司这个人是投资人。
第三个颠覆观点:检验比生成更重要
当AI什么都能生成时,真正的力量不再是「能生成什么」,而是「生成的东西能否通过检验」。
沈阳团队将检验者分为四类,其进化速度依次递减:AI自身作为检验者(如编程、数学),可实现最快的进化闭环;个人作为检验者(主观审美);社会作为检验者(如市场反馈);自然界作为检验者(物理规律、化学规律等)。在AI能够自我检验的领域,进化速度将快得超乎想象。按照这个分类,AI在不同的校验者方向走向AGI的速度是不一样的。
此外如果AI现在是普通提示词能达到85分,那么极致提示词也许能到95分,这意味着经过极致提示的人机互动会先于纯粹AI自身达到AGI。
第四个颠覆观点:我们将面临「多版本现实」
AGI可能会根据每个人的偏好,生成完全不同的信息世界,导致社会失去共同的现实基准,进入「多真理并存」的状态。
每个人都将置身于一个超个性化的「认知剧场」,现实失去唯一性。这不仅是技术问题,更是未来社会最大的哲学与治理挑战。
这四大颠覆观点的底层,是两大理论基座,「AI能力四层结构」与「AI for AI六阶段研究链」。
所谓的「四层结构」,是对AI能力演进的客观描述。最核心的是通用符号推理层,即AI的纯抽象逻辑与数学能力,这是所有能力的根基,也因其千倍级的迭代速度,成为团队战略投入的重点;在其之外是数字内容生成层,涵盖文本、图像、视频等;第三层是是数字世界自主交互层,即工具调用与多智能体协作,这是AI从「工具」向「代理」跨越的关键;最外层则是仍在艰难演进的物理世界交互层。这一结构清晰揭示了团队的判断:必须站在迭代速度最快的地方,即符号系统层。这也是为什么Anthropic迭代如此之快的一个原因。AI for AI解决了,可以迅速将这种能力平移到其他任何领域。
而「六阶段研究链」:训练模型→微调模型→推理优化→自进化框架→行业应用→极致内容,既是团队的方法论,也是AI从零走向行业、从工具走向内容的路线图。
AI主导的「生命底座」
在AI自我进化的链条中,模型训练是底层根基。
AI从零自主训练大模型
在这一领域,团队四月份实现了一个关键里程碑:AI从零自主训练大模型。AI能够自主发现并优化训练算法,独立完成「提出方案—实验迭代—性能验证」的完整闭环,并形成了持续产出的能力。这验证了其「底层一致性」理论——AI编程、AI绘画、AI文学、AI音乐在底层逻辑上是相通的事物,当研究者参透了这种一致性,AI就具备了从零创造算法的能力。
为什么是数学和文学?
目前,团队正将这一能力聚焦于两个方向。
一是训练数学大模型。沈阳教授提出,人类知识有11大学科的贯通逻辑:从数学到物理、化学、生理、心理,再到社会学、传播学、经济学、政治学、美学,最终抵达哲学。这一逻辑链中,数学是最底层的符号系统,也是迭代速度最快的部分。「算法的迭代速度可能是1000倍,你必须站在那个地方。」因此,训数学大模型成为团队优先级最高的任务。目前,数学大模型训练已取得阶段性进展。
二是训练文学大模型。沈阳教授判断,文字是图像和视频大模型「真正的上限」。2D视频生成的天花板没有想象中高,画面逼真将很快不再是壁垒。真正的瓶颈在于剧本、故事和人性逻辑。「艺术是对上一次艺术的反抗」,它没有止境,不像算法有理论上限。因此,团队正在训练一个专注于文学创作的大模型,力求在叙事逻辑和人物弧光上实现突破。预计数学大模型和文学大模型将在数月内发布。
(超过 1000 位编剧用的自动写小说和剧本的多智能体平台 story.zeelin.cn)
AI为AI自己做精准的「脑部手术」
如果说训练是赋予AI躯干,那么微调就是为它注入行业深度的「脑部手术」。
核心问题在于:模型不是适配个人的,要让它深度个性化,则需要快速微调。而让AI自己微调大模型则成为一种必然。
为什么需要框架的进化?
在这方面,团队正实践用「自进化多智能体」来自动化完成微调。AI的进化就像人一样,脑子自己是改变不了自己的,必须在外部设定心和四肢——也就是框架——才能指挥外部数据导入,对大脑进行更新。因此,AI的自进化包括两部分:模型的进化(认知性)和框架的进化(操作性),两者缺一不可。
这一结构可以完整表述为「脑+心+四肢+神经系统」:大模型是脑,负责理解、推理、规划与生成;技能系统是四肢,负责调用工具、执行命令、操作文件;记忆系统是心,负责保留用户偏好、沉淀执行经验;工作流闭环是神经系统,负责观察执行结果、修正行动计划、发起新一轮迭代。
到底是模型吞噬框架,还是框架吞噬模型,可能在模型发展快的阶段是前者,模型发展慢,则会是后者。并且越往物理世界延伸,框架越发重要。
AI自动微调七言情诗大模型
团队已将AI自动微调的能力产品化。开发的AI自动微调样例:七言情诗大模型,在押韵、平仄、意境三个维度均达到一定水准。这个案例证明,AI不仅能学习通用逻辑,还能极其精准地嵌入人类的特定工作流与文化语境中——不仅懂七言诗的押韵规范,还能写出中国式的含蓄。
自进化框架的四条路径
在工业界,这种细分与微调直接催生了当前极度繁荣的「氛围编程」及其四大模式:使用Manus等通用智能体模式、由传统IDE演变而来的工具如Cursor模式(XAI也在洽谈收购)、大模型原生编码平台模式,以及团队深度研究的OpenClaw、Hermes等开源AI框架模式。未来的自进化框架,会沿着这四条路径前行。其中较有优势的是官方的Anthropic claude、chatGPT codex和OpenClaw、Hermes这两条路径。
效率决定生死,美学决定灵魂
模型走向大规模应用,必须解决推理成本与效率的瓶颈。
为什么做本地化部署?
在AI竞争从云端参数大战蔓延至端侧落地的今天,推理优化决定了商业的生死线。本地化部署越发重要,这基于两个核心考量。
第一个原因是安全。数据不能出去,在本地做离线大模型,可以有效保障隐私。
第二个原因是Token基本是免费,本地可以运行「未对齐」的全量大模型。许多模型在发布前经过了审查和对齐处理,而本地部署可以调用未经审查的版本,在某些场景下效果更好。更重要的是,在本地运行大模型是零Token消耗的,能极大降低成本。
功能与美学的双重逻辑
基于这些实践,沈阳团队得出了一个判断:功能的核心是效率,内容的核心是美学。
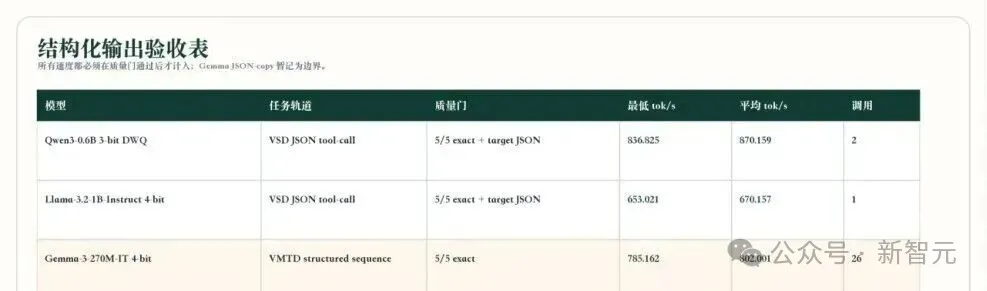
在效率层面,团队自研的新型本地大模型的推理算法,在小模型结构化低熵输出任务上, VSD原型以目标模型验证的方式,将 Qwen3-0.6B JSON tool-call 推理从207.212 tok/s提升到平均 870.159 tok/s,将 Llama-3.2-1B JSON tool-call 推理从108.536 tok/s提升到平均 670.157 tok/s,Gemma-3-270M 结构化序列 VMTD从290.383 tok/s 提升到平均 802.001 tok/s,且通过 exact greedy 与 target JSON 验收。
STC 1.0:AI 自研新算法的例证