OpenAI Image2:断崖反超 Nano Banana51CTO技术栈
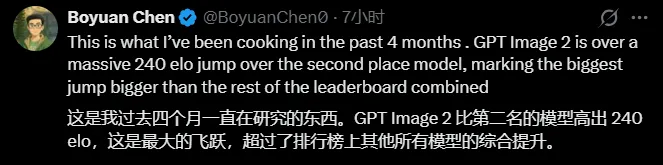
“这是我过去四个月一直在研究的东西!”
几个小时前,OpenAI 的 Image 2 成功反超 Google !
而这款上线即 SOTA 的文生图模型,直接在榜单上以碾压性的 242 分的优势超过了第二名 Nano Banana 2!
如此强悍的模型悄然而至,似乎一下让开年以来不断被 Anthropic 盖过风头的OpenAI,再次回到了舞台 C 位!
这这款模型背后,究竟是如何做到?本篇就带大家一探背后的技术实现路径。
随着 OpenAI CEO Sam Altman 的一场直播,大家开始注意到 Image 2 核心研发者:Boyuan Chen!
Chen 在帖子中爆料到:这款模型研发周期持续了四个月。
直播一开场,Sam 就为这款模型给出了一个相当高的评价:就好像直接从GPT3跳到了GPT5一样!
Text-to-Image 项目中实现了完美统治,以创纪录的+242 分领先优势 - 这是迄今为止我们见过的最大差距。
首个具备思考能力的文生图模型
这是 Image 2.0 最为让人惊艳的地方。
这是一个范式变化。用 Sam 的话来说:如果 DALL·E 是洞穴壁画,Image Gen 1 是古代艺术,那么 Image 2.0 就是文艺复兴。
简单理解,就是学前班画画水平跟专业设计师之间的区别!
这里之所以用了“文艺复兴”,其实一点也不夸张。大家只要简单回顾一下前两代模型的使用经历,再试一把 Image 2.0 就能明显感觉到代际差异。
先看下这个例子就知道了。小编考了一道中学生未必都能半分钟回答出来的问题:帮我在一张A4纸上用红色中性笔证明一下勾股定理。
Image 2 似乎理解了我所提的每一个概念要素:A4 纸、红色中性笔、勾股定理、证明。
结果就这么水灵灵的给出了一个几何证明题的作业纸。“白纸红字”,不服不行!
这就如同文艺复兴时期,人们开始走出原始表达和理想化审美的束缚,开始系统地理解世界,并学会用科学方法去重建现实。
具体怎么触发这一功能?
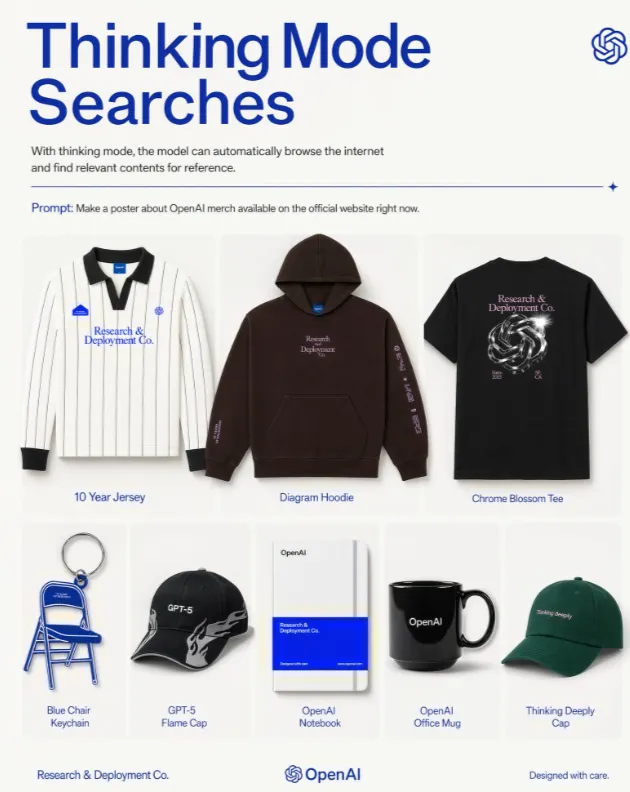
只需要在 ChatGPT 里选 thinking 或 Plus、Pro 模型即可。然后你吩咐模型做图,模型就会做三件事:联网搜索实时信息、基于用户上传的文件生成可视化解释内容(一次产出最多 8 张连贯图)、图像生成前自我检查输出质量。
升级后的模型,作图过程也变得更加专业范儿:
先打个草稿,生成初稿中,搭好场景,打磨细节,收尾中,最后润色中,最后微调一下,创建完成。
下面这个例子,很好的体现了这一过程,在不同画面中保持人物、物体和风格的一致性。
总结一下,OpenAI 这波释放了一个图像模型的演进方向:
模型不只是生成图像,它在“思考”。它可以进行研究,甚至能搜索网络,以最准确的信息生成图像。
基于这些能力,它可以生成解释复杂系统的信息图,甚至用带证明的方式解决数学问题。
OpenAI 表示,这将使生成漫画页面、社交媒体视觉内容系列,或整套家居设计方案变得更加容易。
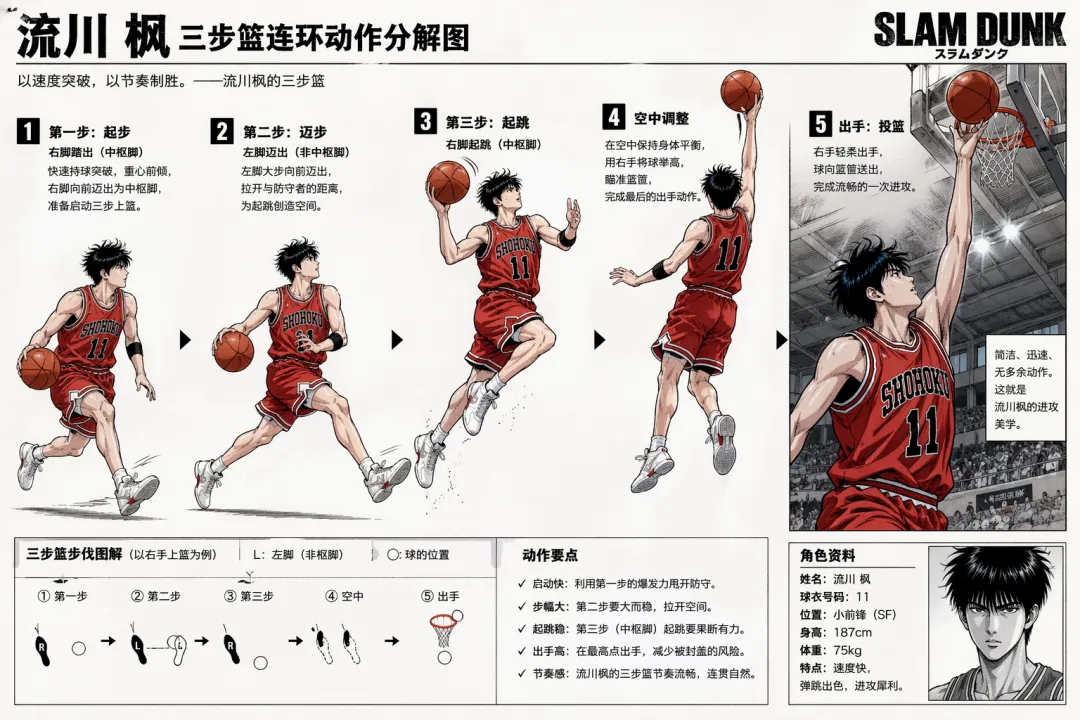
比如,我们已经可以在毫无上下文背景的情况下,让 Image 2 生成一张流川枫三步篮的动作拆解图。
可以看出,原本需要专业体育+绘画知识的一张分解图,就这样被 OpenAI 分分钟秒出了。文本内容非常专业准确,而结构化的构图设计也非常合理,视觉布局能力也没的说。
毫无疑问,OpenAI 这次是真的瞅准了生产级环境的视觉内容。
那么,如此聪明的会思考的模型是如何实现的呢?
目前,OpenAI Imagegen 团队研究员 Ayaan Haque (多说一嘴,前 Luma 团队成员),透露了一些工程信号:模型先做研究,再去做。
以前,如果你让图像模型去研究一个主题,它其实并不具备足够的世界知识,也缺乏各个领域的专业能力。