一文读懂GPT-5.5:更大、更贵、更智能腾讯科技
当地时间4月23日,OpenAI正式发布新一代旗舰模型GPT-5.5,官方将其定位为“面向真实工作的全新智能层级”,也是迈向全新计算机工作方式的重要一步。
这次发布核心关注的有两点:
一是效率层面的突破:同等延迟下,模型更大了,速度却没慢。GPT-5.5上下文窗口达到100万Token,但它不是GPT-5.4简单能力升级,而是在效率上做到了同等延迟下的更高智能。
二是GPT-5.5 在训练过程中,参与了自身推理基础设施的优化。简而言之,AI第一次学会帮自己调参数。
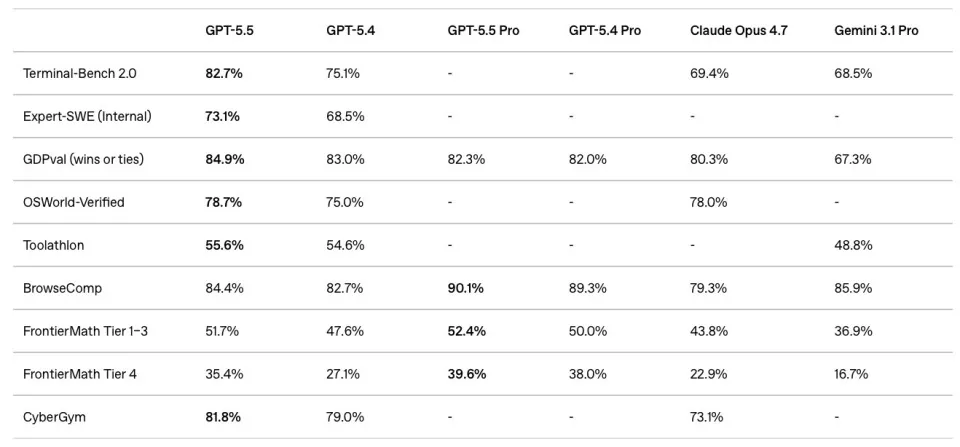
在测试复杂命令行工作流的Terminal-Bench 2.0中,GPT-5.5得分82.7%,Claude Opus4.7的69.4%超过13个百分点;在测试AI独立操作真实电脑的OSWorld-Verified中,成功率78.7%,超越人类基线;在测试跨44种职业知识工作的GDPval中,84.9%的任务达到或超过行业专家水平。
不过,GPT-5.5的价格也明显涨了。
API定价为每百万Token输入5美元、输出30美元,是GPT-5.4(每百万Token输入2.50美元、输出15美元)的两倍,但官方强调GPT-5.5完成相同任务所需Token数量大幅减少,综合成本未必显著上升。GPT-5.5ProAPI定价为每百万Token输入30美元、输出180美元。批量处理和弹性定价享受半价优惠,优先处理为标准价格的2.5倍。
在ChatGPT中,GPT-5.5以“GPT-5.5 Thinking”形式上线,逐步取代此前版本。
一个新增的小设计是:模型开始思考前会先给出一段思路概述,用户可以在执行过程中随时插话,调整方向。
如果用一句话概括GPT-5.5的意义:过去的模型是能力的集合,GPT-5.5更接近一个会规划、会检查、会持续推进的工作系统。
01 84.9%的任务,达到专业人士水准
GPT-5.5与各竞品在Terminal-Bench2.0、GDPval、OSWorld-Verified等核心基准测试中的对比
先看评估模型在真实职业场景中的表现。OpenAI用了一个叫“GDPval”的基准测试,它要求模型完成一整套职业任务。测试覆盖44种职业场景,包括财务建模、法律分析、数据科学报告、运营规划等等。
结果显示:GPT-5.5在84.9%的任务中达到或超过行业专业人士水平。作为对比,GPT-5.4是83.0%,ClaudeOpus 4.7是80.3%,Gemini 3.1 Pro 只有 67.3%。
这种差距不止体现在总分上。电子表格建模任务中,GPT-5.5内部测试拿到88.5%;投资银行级别的建模任务同样领先前代。早期测试者的反馈也挺一致:GPT-5.5Pro 的回答在全面性、结构性和实用性上比 GPT-5.4 Pro 有明显提升,商业、法律、教育和数据科学领域尤其明显。
光看数字容易麻木,OpenAI这次干脆掀开自家工位给你看。
OpenAI表示,公司内部超过85%的员工每周都在用Codex,覆盖财务、传播、市场、产品、数据科学等多个部门。传播团队拿它分析了六个月的演讲邀约数据,搭起了一套自动化分级流程;财务团队用它审阅了24,771份K-1税务表格、合计71,637 页,比去年提前两周完工;市场拓展团队靠自动化周报生成,每人每周省下5到10小时。
这不是实验室demo,已经变成一种工作日常。
02 最强自主编程模型
OpenAI称,GPT-5.5目前是其最强的自主编程模型。
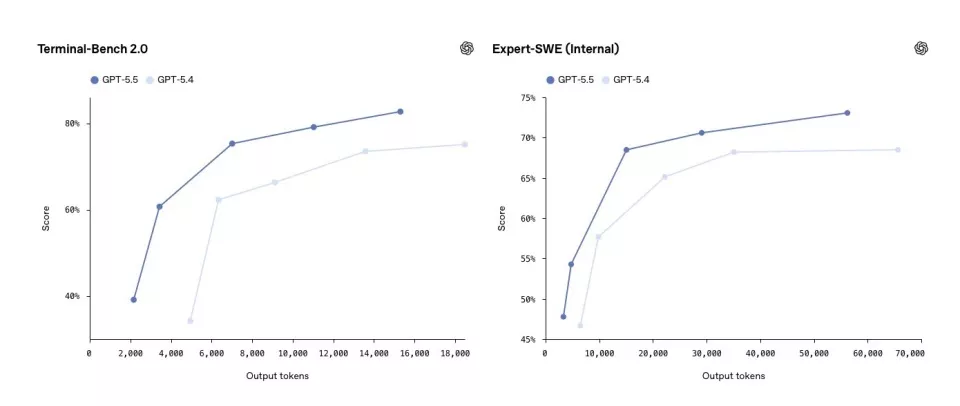
在Terminal-Bench2.0上(测试复杂命令行工作流,需要规划、迭代与工具协调),GPT-5.5得分82.7%,对比GPT-5.4的75.1%,提升幅度接近8个百分点,同时Token消耗更少。在SWE-BenchPro上(评估真实GitHub问题的一次性解决能力),GPT-5.5得分58.6%。在内部Expert-SWE评测上(长周期编程任务,中位人工完成时间约20小时),GPT-5.5同样超越GPT-5.4。
Terminal-Bench 2.0和Expert-SWE散点图
Codex在GPT-5.5的驱动下,已经能够从一句话的提示词出发,独立完成从代码生成、功能测试到视觉调试的完整开发流程。
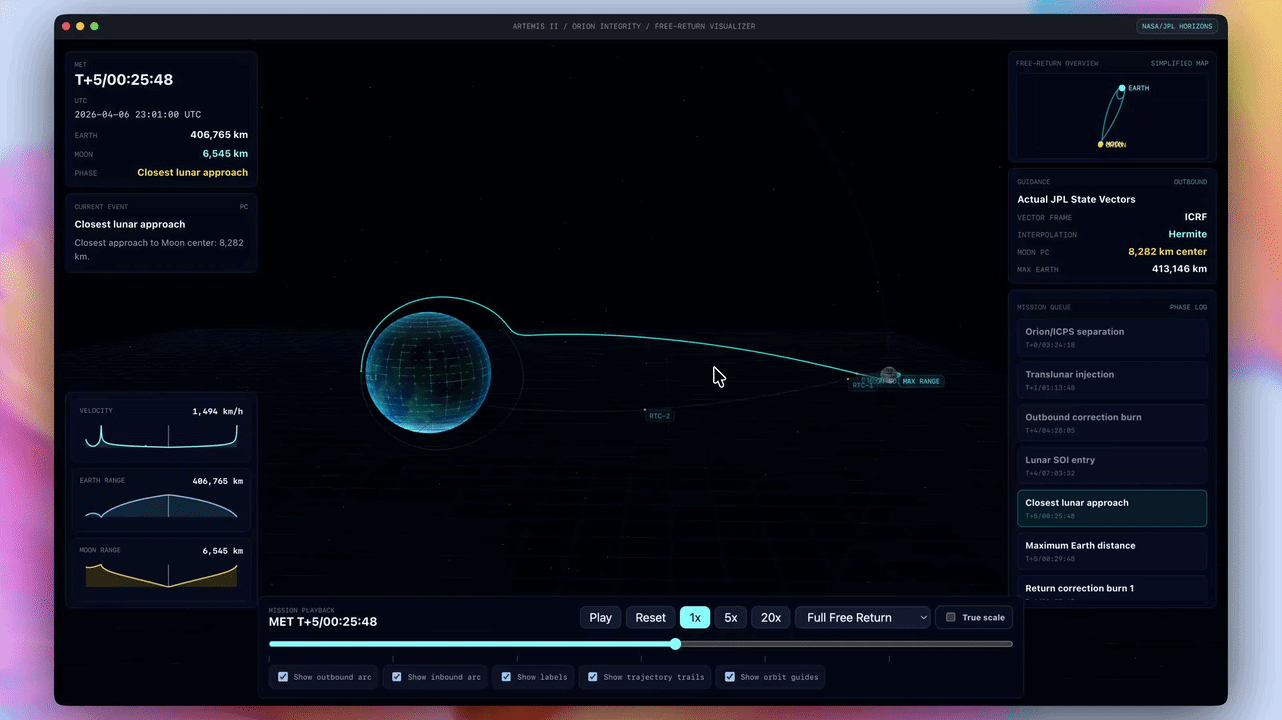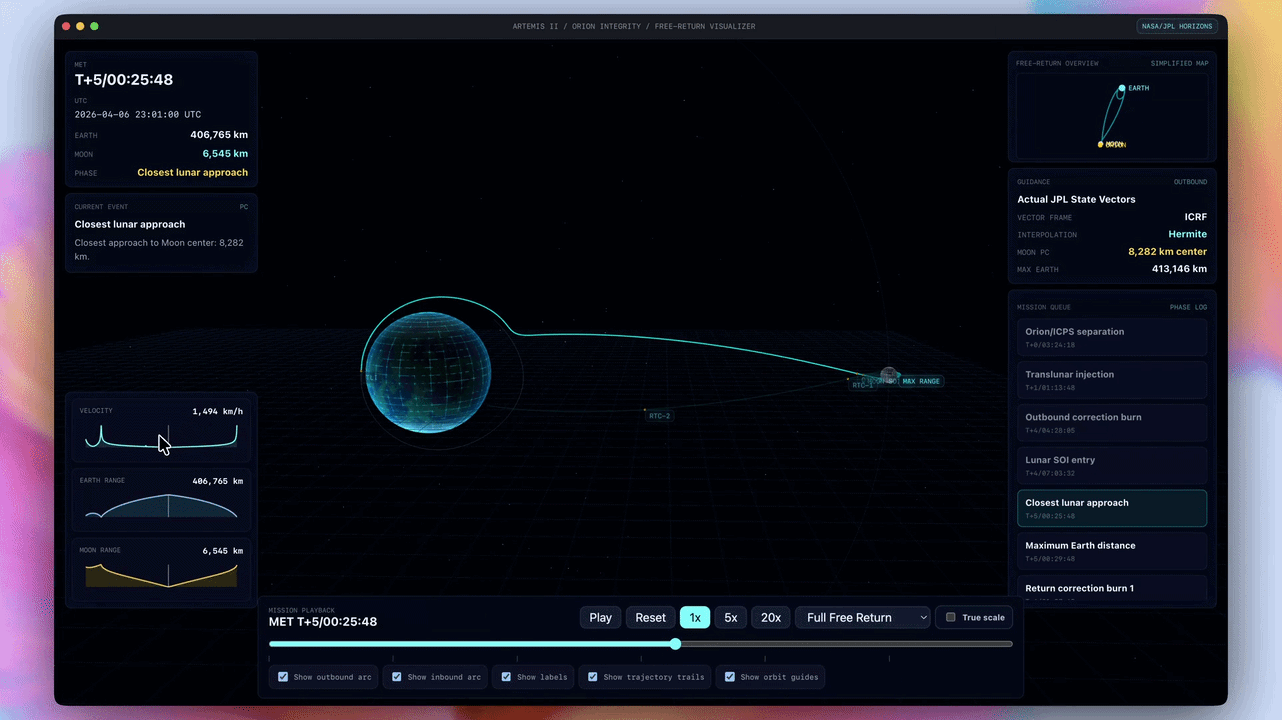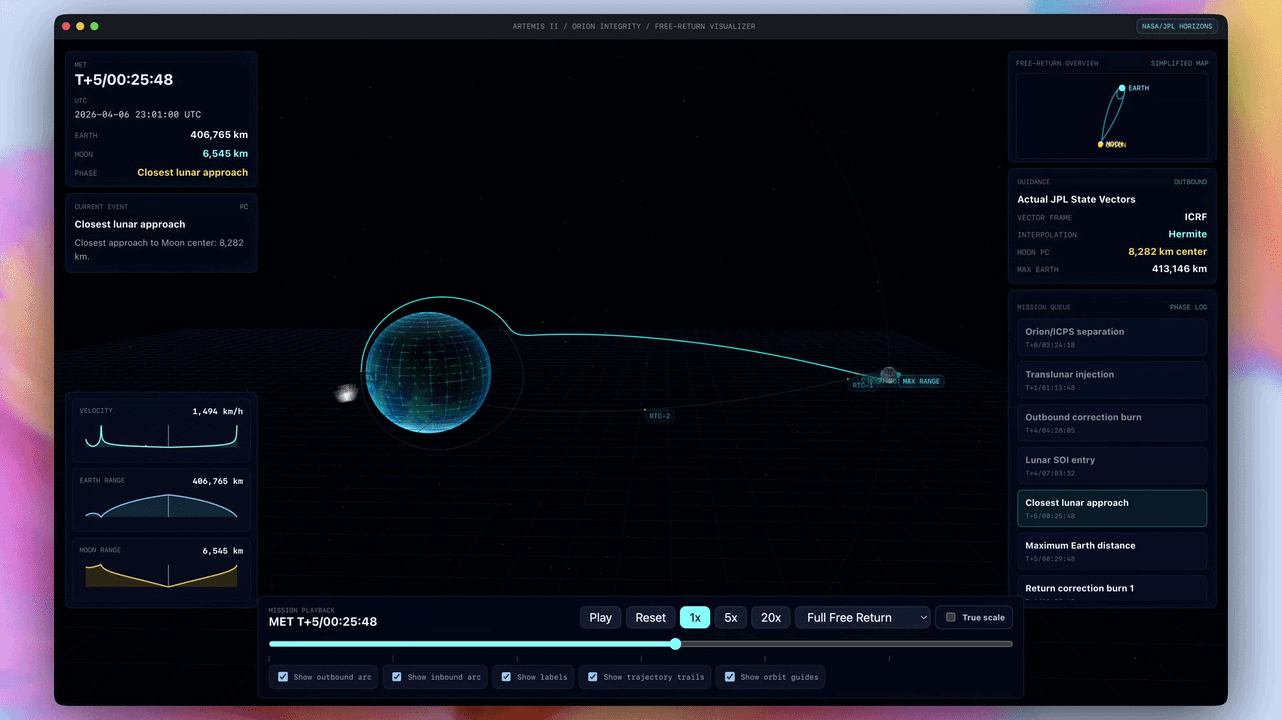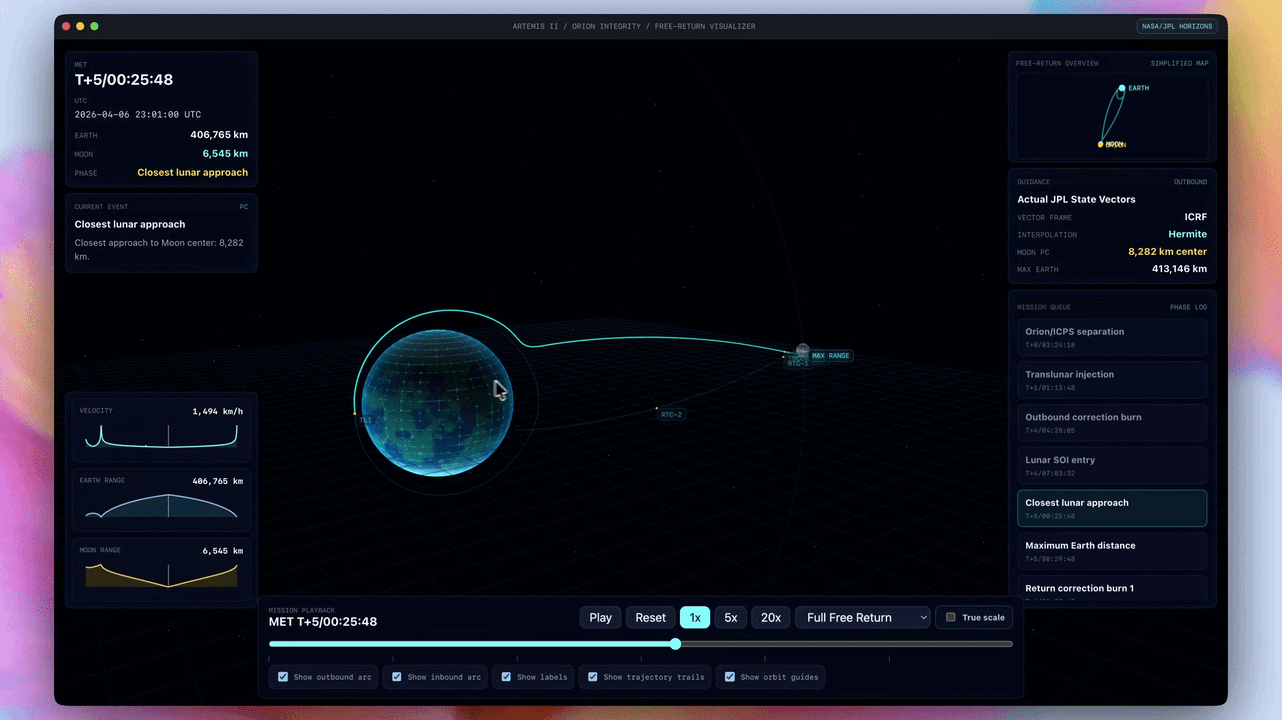
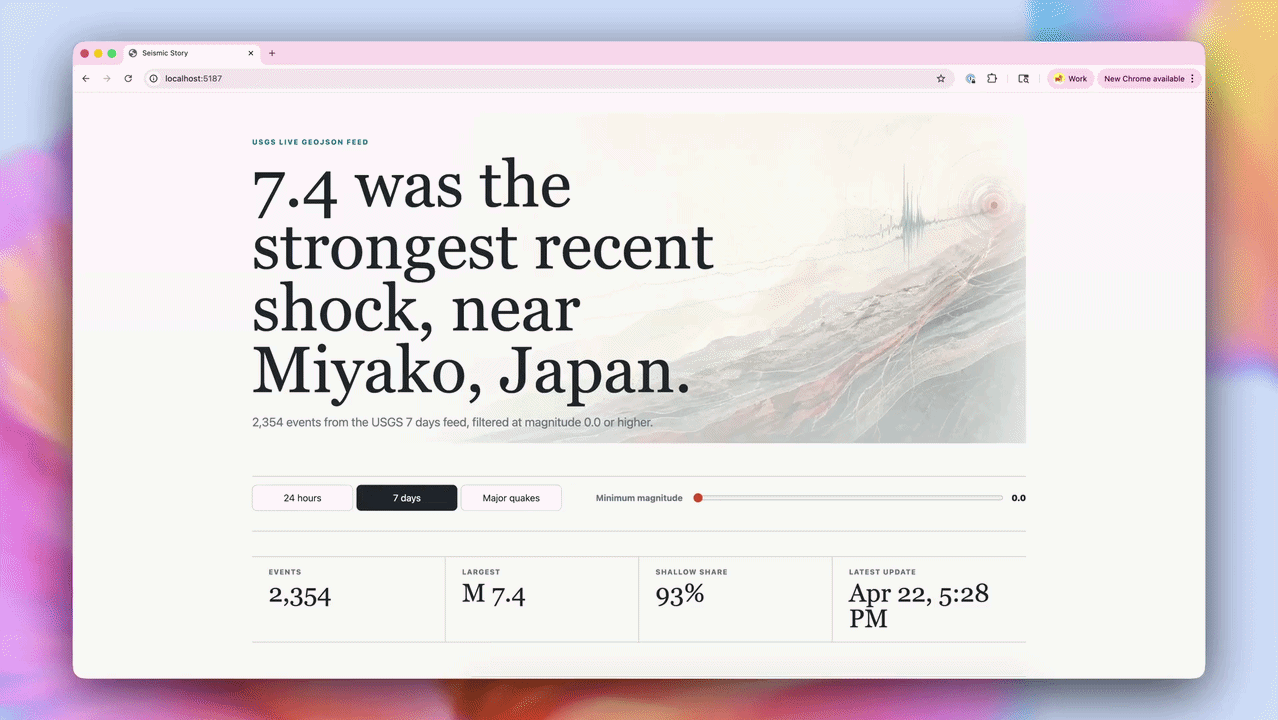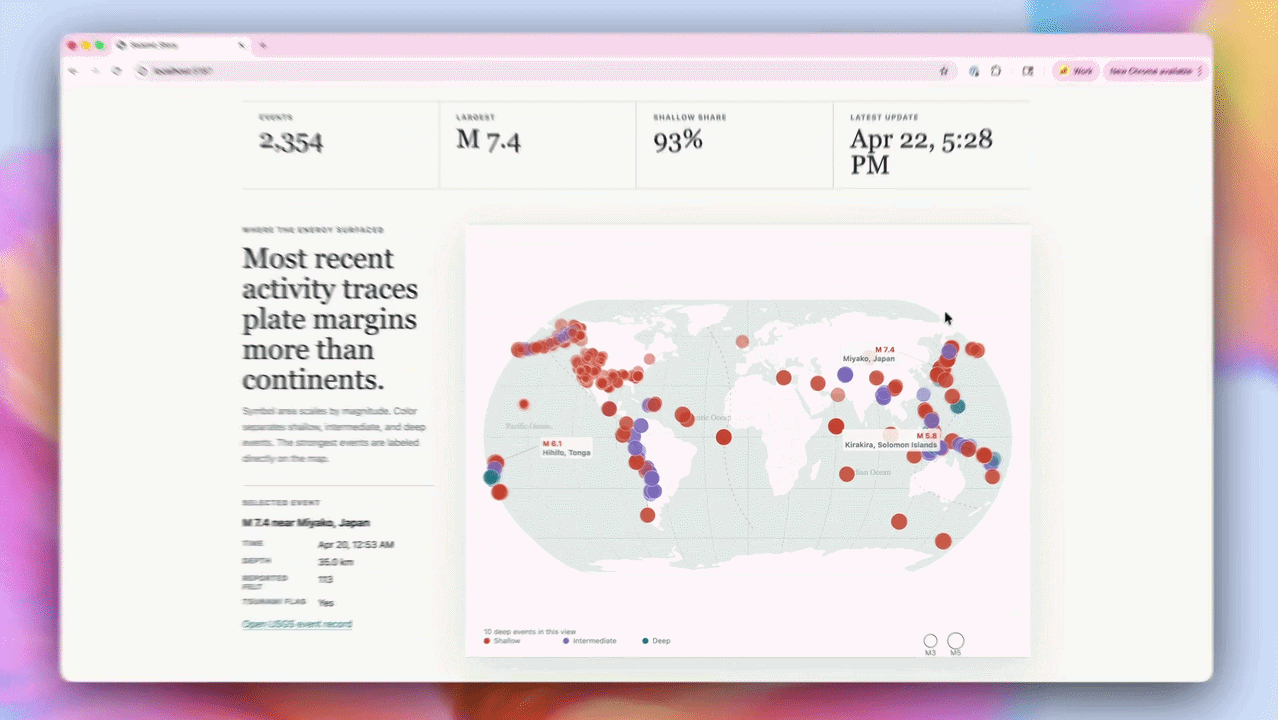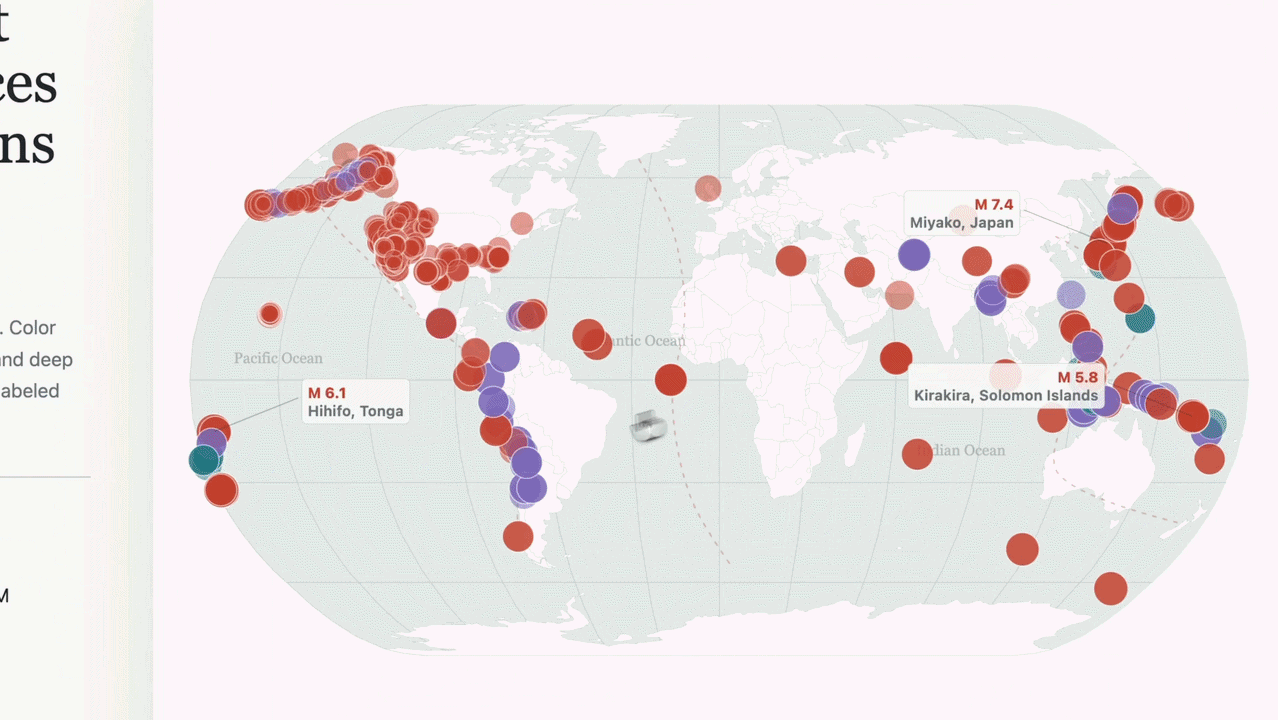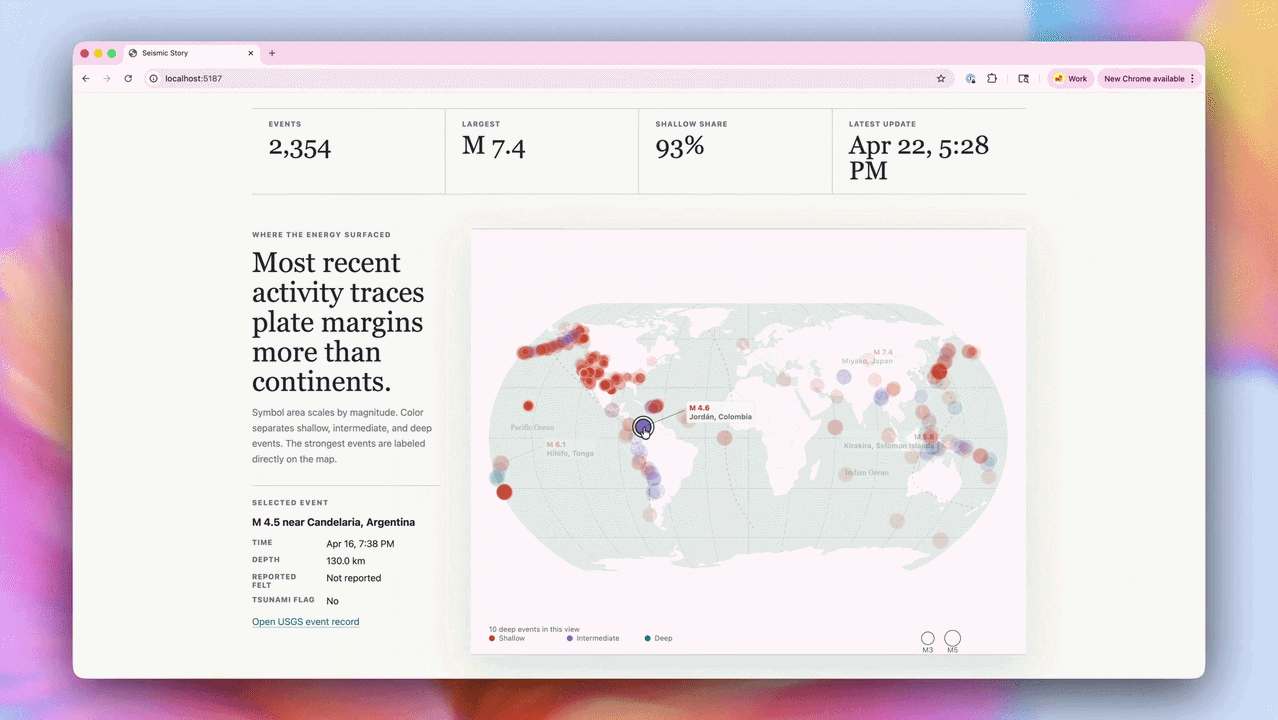
OpenAI官方展示的演示案例显示,太空任务应用基于NASA真实轨道数据构建,支持3D交互操控,轨道力学模拟达到真实物理精度;地震追踪器接入实时数据源并完成可视化,说明模型已具备调用外部API、处理动态数据并实时渲染的完整能力。
对于使用反馈方面。Every创始人兼 CEO Dan Shipper 讲了一段经历:他之前遇到过一个上线后的bug,自己调了好几天没搞定,最后只能请公司最强的工程师出手,重写了一部分系统。GPT-5.5 出来后,他做了个实验——把模型放回bug 还没修的那个状态,看它能不能自己得出和工程师一样的方案。GPT-5.4 做不到,GPT-5.5做到了。他评价:"这是我用过的第一个真正具备概念清晰度的编程模型"。
一位英伟达工程师的评价更直白:"失去GPT-5.5的访问权限,感觉就像截肢"。
Cursor联合创始人兼CEO MichaelTruell对此的补充是:GPT-5.5比GPT-5.4更聪明、更坚韧,在复杂长时任务中能坚持更久而不提前停下——而这恰恰是工程工作最需要的。
03 知识工作:AI第一次真正能“用”电脑
在OSWorld-Verified测试中(测试模型能否独立操作真实计算机环境),GPT-5.5成功率78.7%,高于GPT-5.4的75.0%,也优于ClaudeOpus 4.7的78.0%。
这不是截图分析,而是真正的屏幕操控:看到界面、点击、输入、在多个工具之间切换,直到任务完成。GPT-5.5让人第一次感受到,AI可以真正与你共同使用同一台电脑。
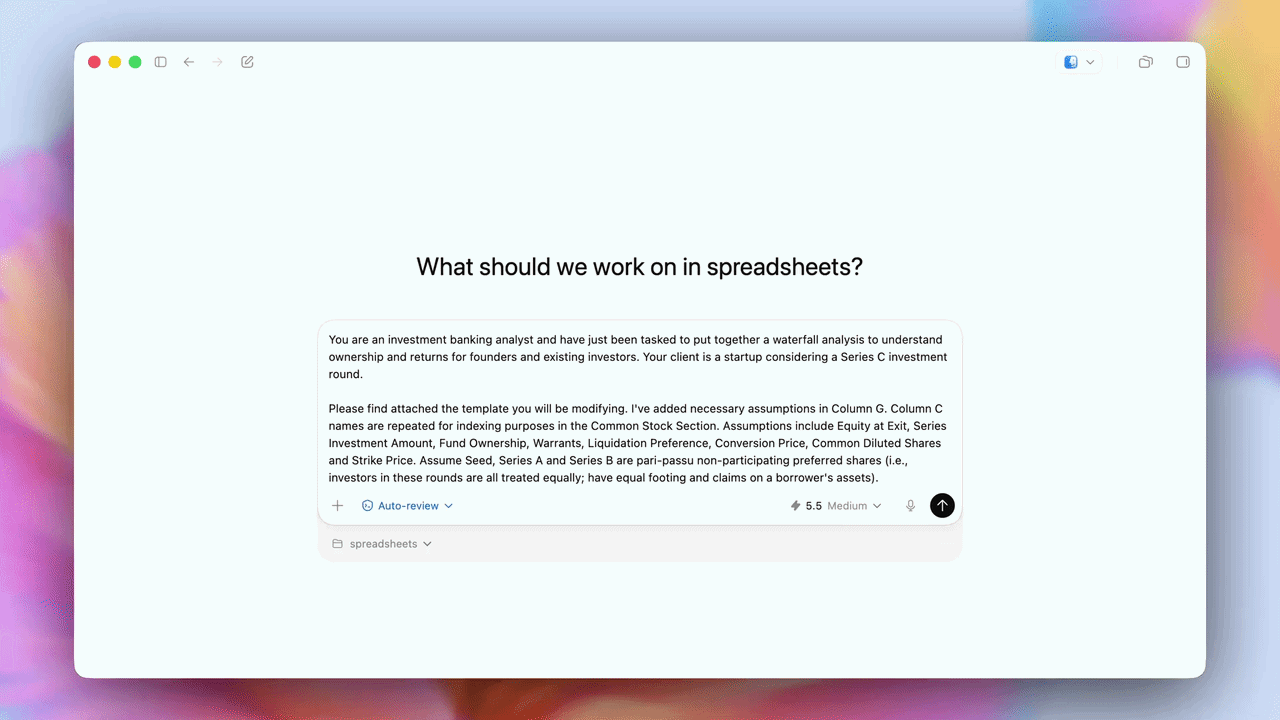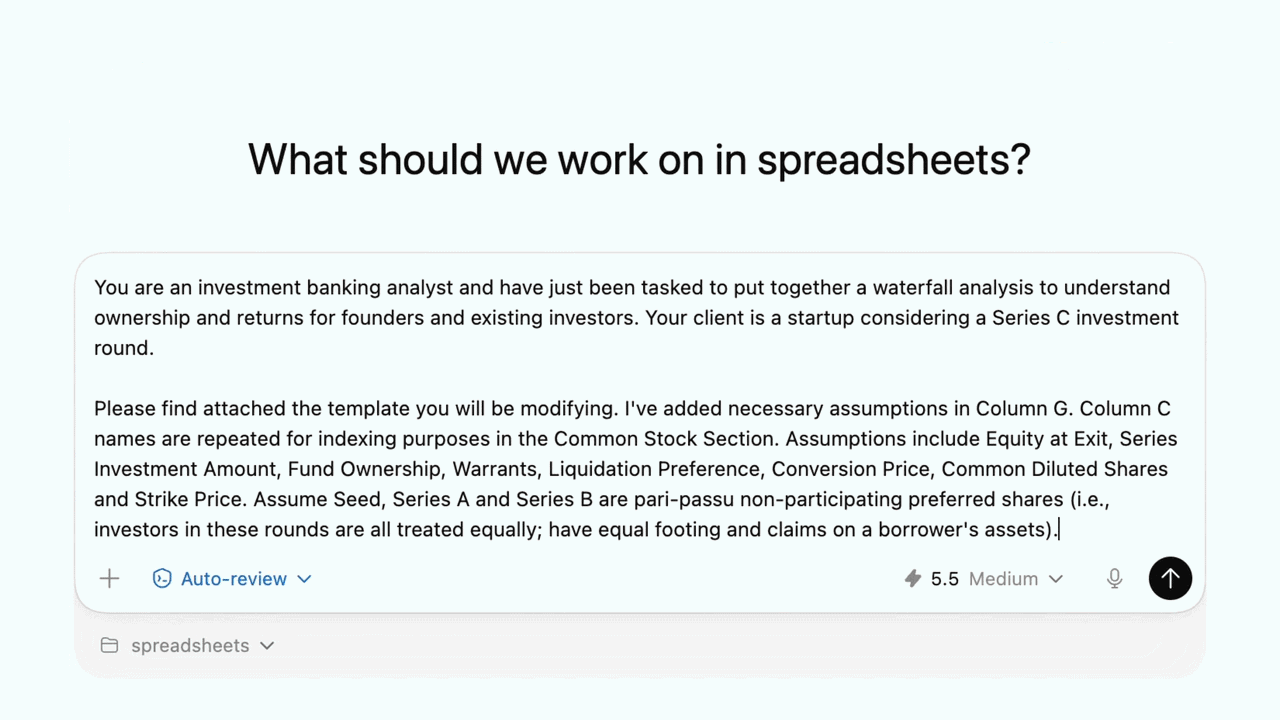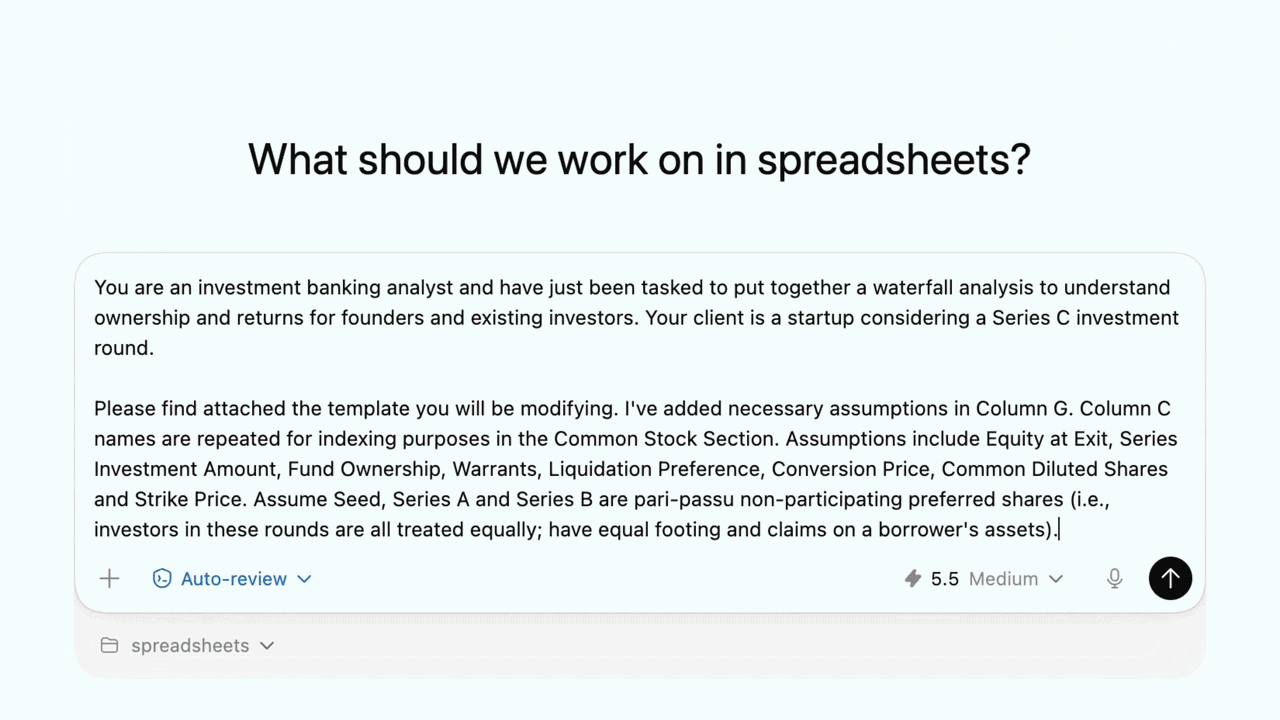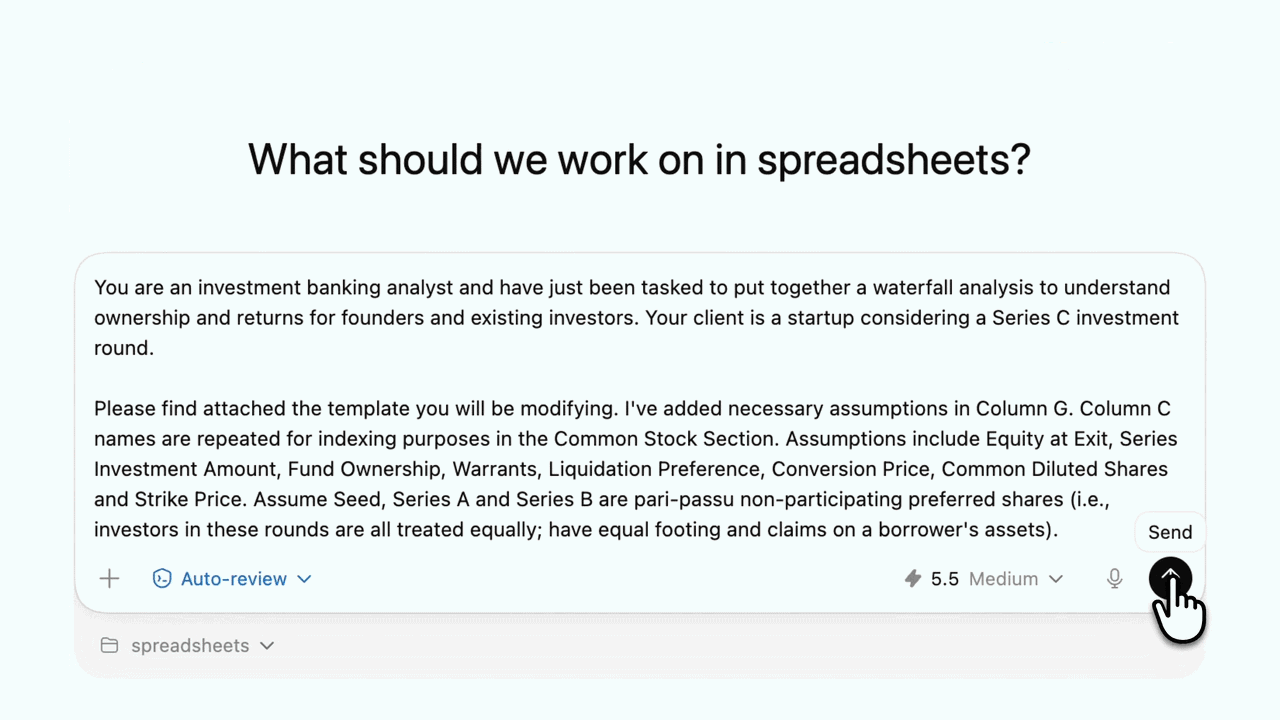
财务建模演示视频