中国具身屠榜全球:10万小时数据炸场新智元
10万小时人类数据、不搞对齐只靠规模,灵初Psi-R2登顶MolmoSpaces。
具身智能领域最近有一个心照不宣的焦虑:真机遥操作数据这条路,可能走不下去了。
成本是一方面——采集一小时数据动辄花数百元,还得搭一套专业动捕环境。
速度更是硬伤:人盯着屏幕遥控机械臂,采集节奏很难跟上真实生产节拍。
这意味着,单纯依赖遥操作数据,恐怕无力同时支撑大规模训练与产业落地。
那换条路呢?
人类本来就在真实作业场景中完成海量高精细操作,让人直接干活,再把人的操作数据扒下来给机器人用。
难点至少两个。
第一,人手和机械手长得不一样,人类操作不能直接平移到机器人身上。
第二,如果只靠第一视角视频去还原人手动作,精度又往往不够,很难支撑高精细任务。
灵初智能最近交了一份答卷。
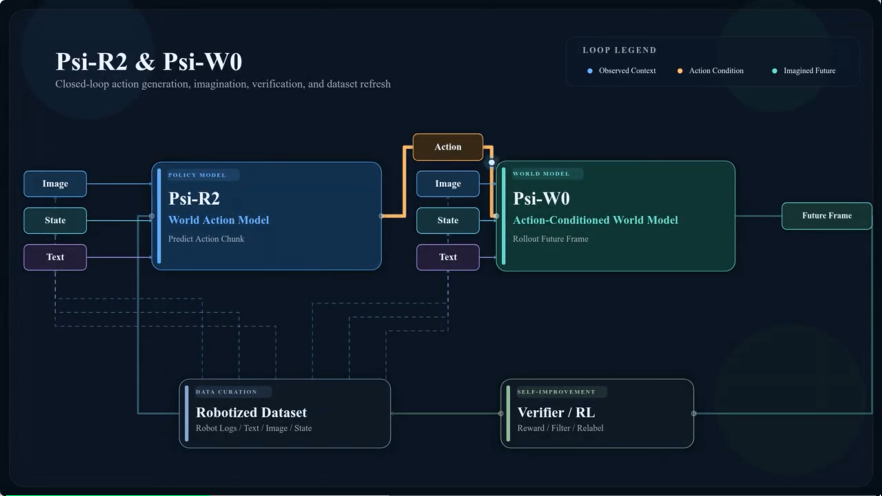
他们用10万小时人类操作数据搭了一套PSI框架,里面有两个大模型:策略模型Psi-R2负责学「任务该怎么做」,世界模型Psi-W0负责补「换种做法会怎样」,再把人类操作一步步转成机器人真能执行的动作。(tech blog链接:https://www.psibot.ai/from-human-skill-to-robotic-mastery/)
模型之外,灵初还亮出了近10万小时人类数据,以及1000小时开源数据集。
这套方法之外,灵初智能同时拿出了近10万小时人类数据,以及1000小时开源数据集。
一、10万小时人类数据
开始被当作机器人预训练的主料
这套路子的起点很简单:把人类操作数据直接塞进机器人预训练的主干。
据灵初披露,Psi-R2预训练同时用真机数据和人类数据。
真机数据来自灵初Psi-MobiDex数据集,5417小时;人类数据总规模95472小时,覆盖294种场景、4821种任务、1382种物体。
背后是一种很直接的判断。
具身智能长期缺「存量数据」——不像自动驾驶有多年路测积累,也不像大模型能从互联网白捡海量文本。
机器人想学会做事,没法像文字或图像那样从现成语料里捞,只能靠现实世界一口一口喂。
真机遥操作曾经是条相对自然的路,但模型规模一大、任务一复杂,这种数据供给方式就开始掉链子。
于是人类数据的价值被重新抬了上来。
它的吸引力就两条:一是来源天然丰富,人本来就在不停干活;二是数据更贴近真实作业,天然带着任务目标、动作细节和节拍信息。
说白了,机器人想学会干活,最密集、最成熟的示范样本,本来就长在人手上。
关键是怎么把人类数据和真机数据捏在一起训。
灵初试过一堆更复杂的招:图像修复、关键点辅助损失、跨空间对齐……小数据量时确实管用。
但数据一上量,这些精巧模块全成了瓶颈。
原因不复杂,这些方法本质上是想让人手和机械手看起来一样,可它俩的物理规律压根不同。
对手机装配这种精细活,强行对齐反而引入误差。
最后剩下的,反而是一条朴素的路线:Raw Data In, Raw Data Out。
落到工程上,就是把人手关节用运动学公式硬算成机械手关节,图像原封不动直接喂给模型,人为处理越少越好。
从结果看,这条路线暂时跑通了。
据灵初披露,Psi-R2完成预训练后,只要用少于100条轨迹的真机数据微调,就能干手机装配、工业包装、纸盒折叠这些长时序、高精度的活。
光有数据还不够。
怎么让机器人「吃」进去?这就引出这套框架的真正核心——世界模型里的强化学习。
二、Psi-W0
把「如果失败了会怎样」补了回来
光看Psi-R2,这套方法有个天然缺口:它擅长从成功轨迹中学习,但自己很难长出反事实能力。
这正是世界模型该上场的地方。
Psi-W0吃进图像、语言指令和机器人动作轨迹,吐出未来场景的视频预测。
它和Psi-R2最大的不同在于:动作在这里不只是预测结果,而是直接参与条件生成。
说白了,它就是一个动作条件型世界模型(AC-WM)。
再直白一点:Psi-R2像「会做题的学生」,Psi-W0像一套能把过程重新推演的系统。
策略模型知道什么动作曾经成功,却不知道动作偏一点、顺序乱一点、接触晚一点会发生什么。
可偏偏强化学习、策略评估、人类动作向机器人动作的真正迁移,全都离不开这部分信息。
为了让模型学会理解失败,Psi-W0在训练里额外加入了约30%的失败样本,这些数据来自专项采集、常规采集和推理过程。
这样一来,它不只认识「成功长什么样」,也开始知道「失败会怎样展开」。
在整套系统里,Psi-W0承担着两层作用。
第一层是评估。类数据规模再大,也不等于知识自动进了模型。
策略到底有没有真学会「人怎么做这件事」?
需要一个能推演轨迹、判断结果的系统来检验,Psi-W0就是这个角色。
第二层更关键:它直接参与把人类数据转成机器人数据。
以抓取任务为例。人类抓苹果的动作映射到机器人身上,很可能就差那么一丁点就抓不起来。
对高精细任务,这种偏差往往是致命的。
传统做法得把场景和物体重建进仿真器,再在仿真里做强化学习微调——流程重、成本高,还得忍受Sim2Real gap。
灵初智能的思路,是把这过程搬进世界模型里完成。
先让Psi-R2学一条人类数据,再把轨迹交给Psi-W0推演,在机器人视觉和机器人动力学条件下看动作结果;不理想就继续用强化学习调,直到这条轨迹更贴近机器人真能执行的状态。
整体看,这相当于多了一层「梦里试错」的空间。
好轨迹可以回流到训练中,成为新的有效数据;偏掉的轨迹也有价值,它们帮助模型识别失败边界,推动世界模型越来越准。
所谓数据飞轮,就是这么转起来的。
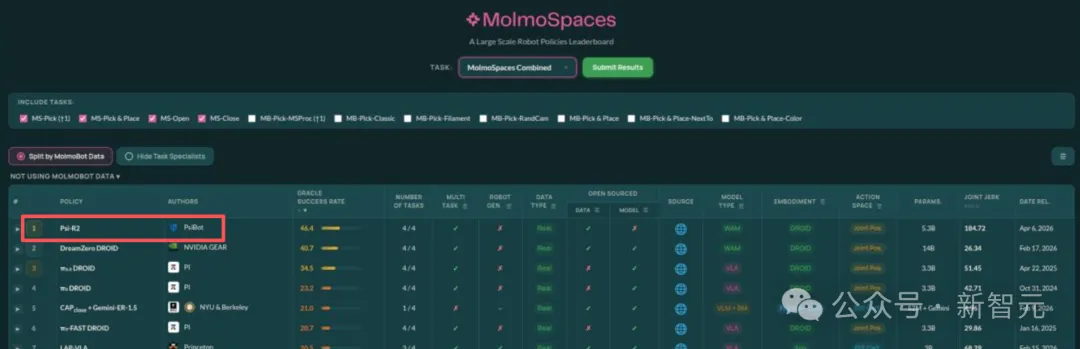
这套方法很快在公开榜单上被验证了。
在由美国 Allen Institute for AI 发起的 MolmoSpaces 榜单中,灵初智能的 Psi-R2 在总榜中位列第一,整体表现超过具身大模型标杆 π 以及英伟达 GEAR 等主流方案,并与其他基线模型拉开差距。
MolmoSpaces 是当前具身智能领域少数与真实世界评测具有较强相关性的公开基准之一。NVIDIA、PI 等全球顶尖团队均参与本次评测。而 Psi-R2 位列其上。
三、数据真正的分水岭
在于信噪比、精度和节拍
如果说双模型架构回答的是「怎么学」,那这次发布里另一个更耐人寻味的问题,是「什么样的数据才值得学」。
灵初智能给出了一个很干脆的判断。
决定数据价值的核心因素,不在数量本身,而在信噪比。
低信噪比数据不光效率低,还会拖垮训练效果。
再往细了拆:在数据分布上,优先级是任务多样性 > 物体多样性 >> 场景多样性;在感知模态上,优先级是精准3D位姿 >> 触觉模态 > 2D图像特征。