开源模型首超Opus4.6量子位
优化CUDA Kernel这件事,刚刚被AI狠狠地冲击了一波。
因为现在,给AI十四个小时,它就能帮你把CUDA Kernel优化,加速比从2.6×推至35.7×!
以前人类资深CUDA工程师要完成这个任务,需要数月反复测试、调优、推翻重来才行;但现在,AI在你睡觉的时候就能解决掉。
而且AI在这个过程中还展现出了专家级的直觉。
例如在优化初期,它尝试在现有高层框架内寻找解法,但很快通过自主跑测试发现性能触及了天花板,然后它便做出了人类专家才有的决策——
自主判断放弃高层框架,直接转向底层C++进行硬核重写。
整整14个小时里,这个AI主打一个全自动:AI自己发现瓶颈,自己改变技术栈,自己重新编译,自己测试。
那这到底是何许AI是也?
不卖关子,正是大家熟悉的,来自智谱的开源模型——GLM-5.1。
随着这次长程任务(Long Horizon Task)能力的提升,智谱官方也宣布了一个重要的突破:
首次解锁了开源模型与当前全球最顶尖闭源模型Claude Opus 4.6的全面对齐!
嗯,是妥妥稳坐全球最强开源模型宝座的感觉了。
而且,从更多的权威评测榜单中来看,也是印证了这一点。
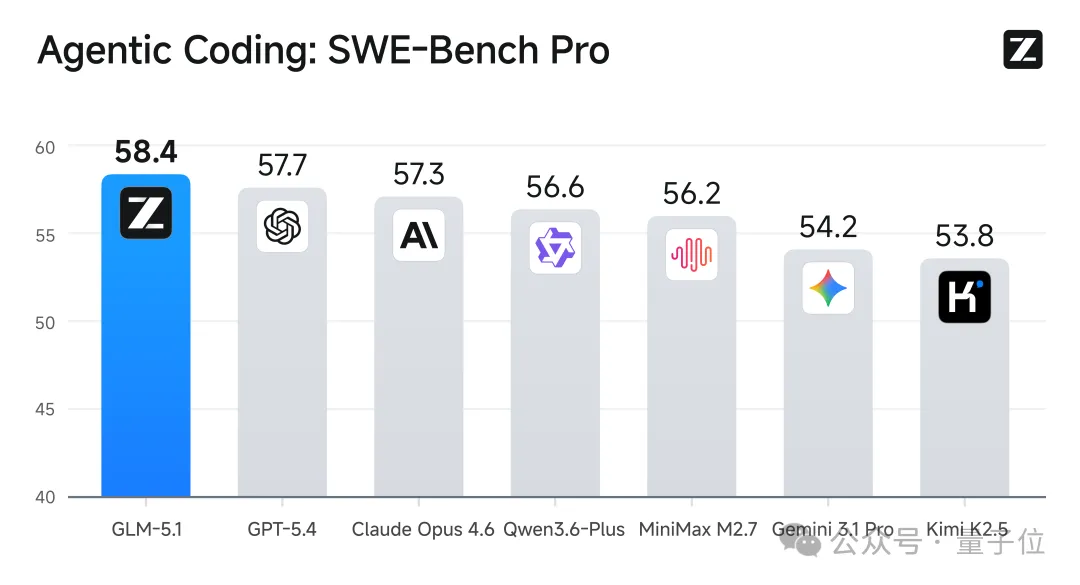
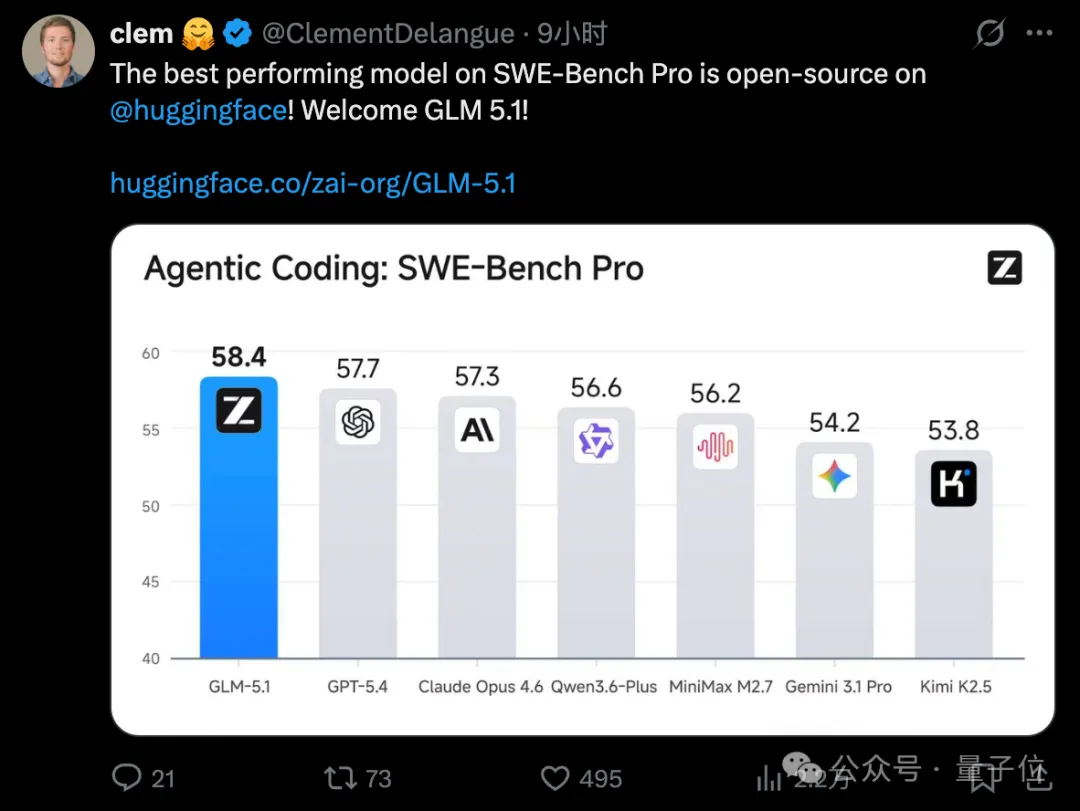
在被称为“软件工程能力试金石”的SWE-bench Pro基准测试中,GLM-5.1刷新了全球最佳成绩,直接超越Claude Opus 4.6、GPT-5.4等一众头部模型,拿下全球第一:
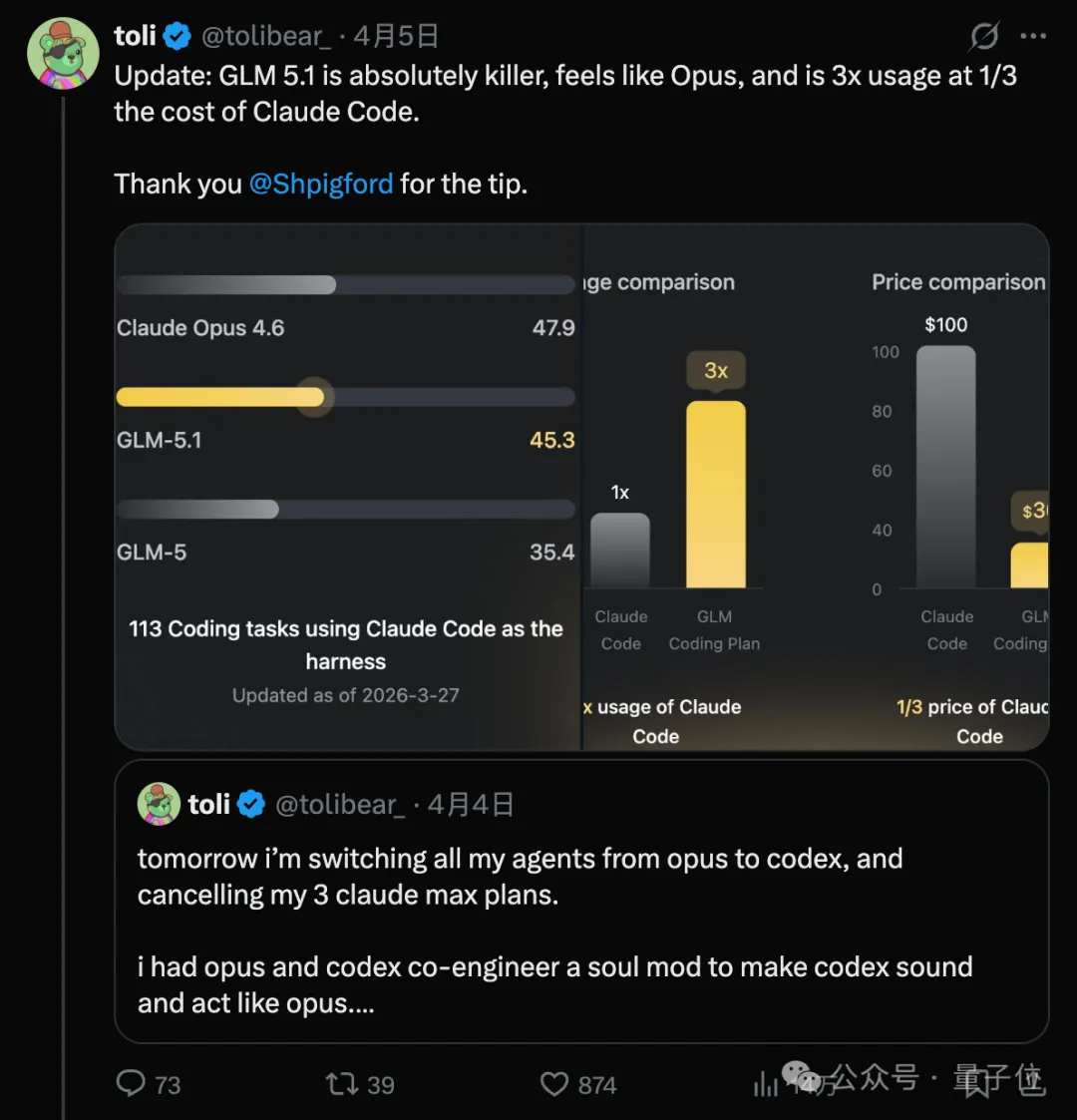
甚至在海外网友们的圈子中,已经吹起了弃用Claude Max的风了:
它的手感和Opus一模一样,使用额度是Claude Code的3倍,成本却只有1/3。
HuggingFace CEO也出面站台,称SWE-Bench Pro中性能最强的模型开源了:
而这一切成绩的背后,正是智谱面向小时级的长程任务能力。
给AI几个小时,一切都不一样了
当前主流的大模型,可以说大多数还是处于“分钟级交互”的阶段。
但到了GLM-5.1这边,它的交付单位就不同了——一个完整的项目。
接下来,我们就通过实测的方式,来看下GLM-5.1的实力到底几何。
调用工具1000轮,优化真实机器学习模型负载
第一个实测,我们顺着前面的CUDA的例子,继续让GLM-5.1进行一场考验:
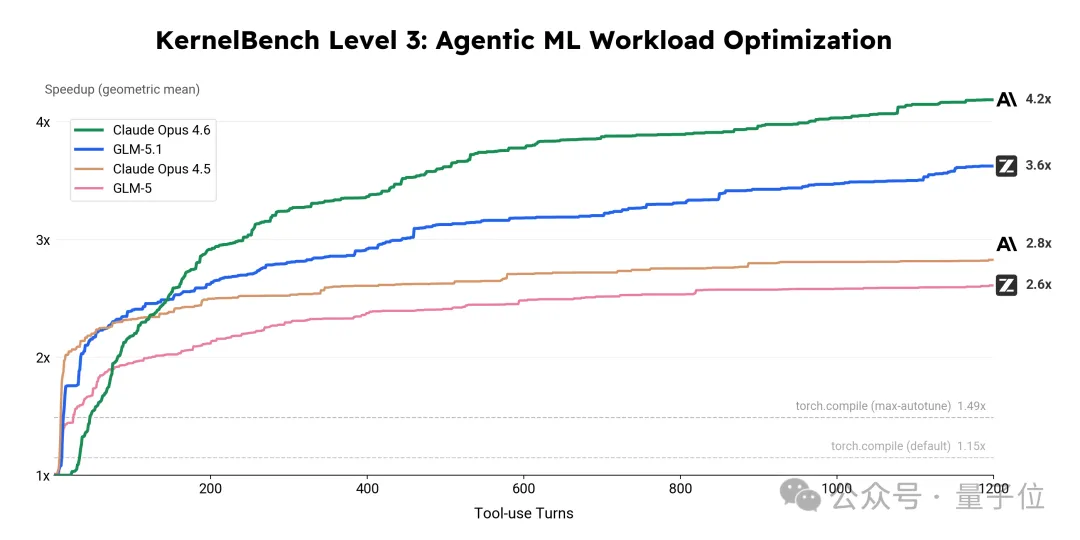
KernelBench Level 3优化基准,这一基准涵盖50个真实机器学习计算负载,主打一个还原真实工业场景,考验的是端到端的完整优化能力而非单一算子调试。
在超过24小时的不间断迭代中,GLM-5.1全程自主发力,无需人类专家干预,一遍遍完成“编译—测试—分析—重写”的闭环循环,最终交出了这样的结果——
3.6倍几何平均加速比,而作为对比,torch.compile max-autotune模式仅能达到1.49倍,差距直接翻倍不止!
从这个过程中可以看到,GLM-5.1能够自主编写定制Triton Kernel和CUDA Kernel,运用cuBLASLt epilogue融合并实施shared memory tiling与CUDA Graph优化。
这些优化策略覆盖了从高层算子融合到微架构级调优的完整技术栈,每一步都是模型的自主决策。
结果再次表明,在GPU内核优化这一传统上高度依赖专家经验的领域,AI模型已经展现出从问题分析、方案设计到迭代调优的端到端自主工作能力。
1小时从零构建MacOS桌面环境
在这个实测中,我们给GLM-5.1扔了一份3000字的PRD,核心要求只有一个:
从0开始复刻MacOS核心UI与交互,不仅要前端壳子,还必须包含窗口管理器、Dock栏调度、以及模拟的底层文件系统。
这是一个标准的前端工程团队至少需要数天才能打磨出原型的任务,但在GLM-5.1这里,时间被压缩到了小时级别。
瞧,待它分析完任务之后,自己就开始唰唰地编程了:
1个小时之后,在没有任何人工参与的情况下,一个MacOS的桌面环境,就这么水灵灵地诞生了!