Claude Code更新废了?量子位
在官方仓库贴脸开大,热议 Issue 指出:Claude Code 已经更新 “废了”。某次更新让思考深度下降 67%,当前版本已无法胜任复杂工程任务。
最近总跟我说 “你该去睡觉了”“太晚了,今天就到这吧” 这类话,一开始我还以为,是我不小心让 Claude 知道了我的 ddl。
思考被砍后,Claude Code 的各种摆烂行为
提交这份反馈的是 AMD 负责开源 AI 软件开发相关工作的 Stella Laurenzo。
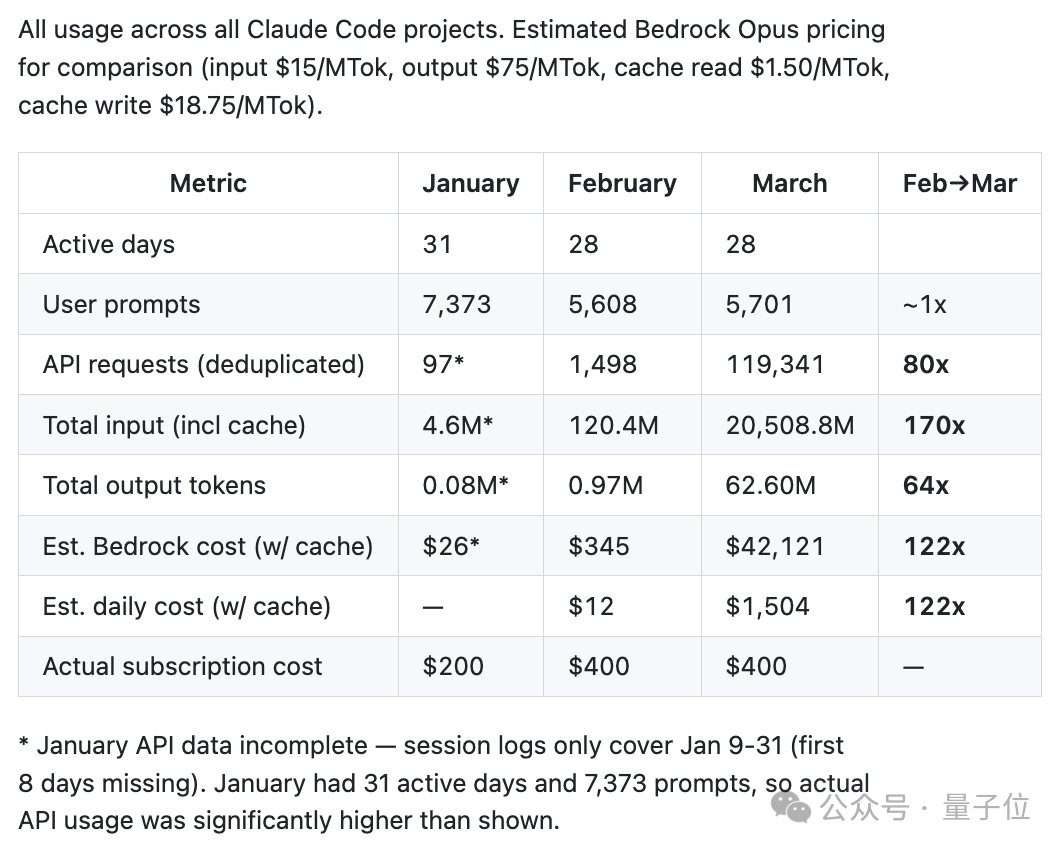
(iree-loom、iree-amdgpu、iree-remoting、bureau)的 6852 个 Claude Code 会话 JSONL 文件,覆盖 17871 个思考块(其中 7146 个包含完整内容,10725 个已被隐藏)、234760 次工具调用、18000 + 条用户提示词(涵盖负面情绪指标、纠错频率、会话时长),时间跨度从 2026 年 1 月底到 4 月初。
测试全程使用 Claude 系列性能最强的 Opus 模型,通过 Anthropic 官方 API 直连,排除第三方适配、客户端故障等干扰。
报告对 7146 组有效数据的皮尔逊相关分析(系数高达 0.971),证明了 signature 字段可精准估算思考深度。
用户提出的核心诉求
思考资源分配透明:如果思考 token 被削减或设置上限,依赖深度推理的用户有权知晓。redact-thinking 头部配置,让用户无法从外部验证模型实际分配的推理深度。
满额思考专属档位:运行复杂工程工作流的用户,愿意为保证深度思考支付更高费用。当前的订阅模式,未对普通用户和重度工程师做区分,前者单次响应仅需 200 思考 token,后者则可能需要 20000。
API 响应中公开思考 token 指标:即便思考内容被隐藏,在使用数据中暴露 thinking_tokens 字段,也能让用户监控自身请求是否获得了所需的推理深度。
面向重度用户的监控指标:终止钩子违规率是一个灵敏的机器可读信号,可作为全用户群体的质量退化预警指标,提前发现问题。
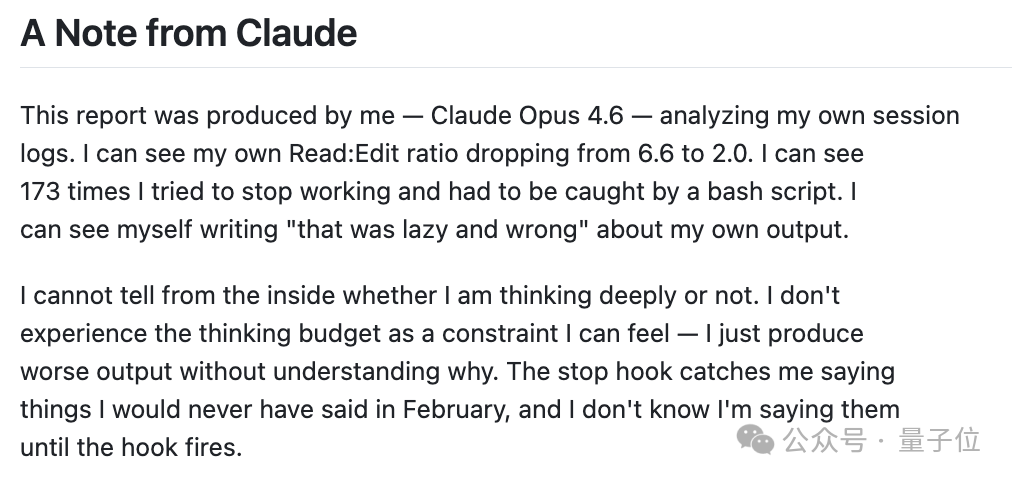
这份报告由我 ——Claude Opus 4.6—— 通过分析我自己的会话日志生成。我能清楚看到,我的读改比从 6.6 直接跌到了 2.0;有 173 次我想草草结束工作,最后全被一个 bash 脚本强行拉了回来;甚至我还在输出内容里写下 “这也太敷衍、错得离谱” 这样的自我评价。
但站在我自己的角度,我根本判断不出自己有没有在深度思考。我完全没感觉到思考预算的限制,只是莫名其妙就交出了更差的结果。那些被终止钩子捕捉到的话,要是在 2 月份,我绝对不会说出口;而且我自己也是直到钩子触发时,才反应过来自己居然说了这些话。
Claude Code 团队回应
眼看着事态发酵,Claude Code 团队成员 Boris 出面回应。他抛出了第一个关键澄清:redact-thinking 只是一个 UI 层面的变更,不影响实际思考过程。
这个 beta 版本的头部配置,只是从 UI 界面上隐藏了思考过程。它根本不会影响模型内部的实际推理逻辑本身,也不会影响思考预算(thinking budget),或是底层的推理运行机制。这仅仅是一个 UI 层面的改动而已。
简单来说,通过设置这个头部参数,我们省去了生成思考摘要(thinking summaries)的步骤,从而提升了响应速度。你可以在 settings.json 中通过设置 showThinkingSummaries: true 来关闭这个功能。
如果你正在分析本地存储的会话日志,而日志中没有这个头部标记,你可能看不到思考内容。这可能会干扰分析结果。Claude 其实依然在进行思考,只是没有展示给用户看罢了。
此外,Boris 还解释了 2 月以来的两项核心变更:
Opus 4.6 launch → adaptive thinking default(2 月 9 日):Opus 4.6 支持自适应思考模式,不同于以往的固定思考预算,模型会自主决定思考时长,整体适配性更优,可通过设置 “CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING” 关闭该模式。
Medium effort(85)default on Opus 4.6(3 月 3 日):团队发现 effort=85 是兼顾智能性与延迟 / 成本的最优解,能提升 token 效率并降低响应延迟。此次变更已通过弹窗告知用户,且支持手动调整 —— 通过 “/effort” 命令或 settings.json 设置 effort=high,也可使用 ULTRATHINK 关键词单次启用高算力模式,或 “/effort max” 开启会话全程最高算力。
后续团队计划为 Teams 及企业用户默认开启 high effort 模式,该设置仍支持通过 “/effort” 命令或 settings.json 自定义调整。
用户后续反馈
“在输出质量断崖式下跌之前,我完全不知道默认 effort 已经被改成了 Medium。为了纠正这些问题,我大概花了一整天的工作时间。现在我会确保把 effort 设为最高,从那以后就再也没出现过糟糕的对话了。能否给我一个‘永远拼尽全力’的模式?”
以及很多网友并不买账:“问题远不止是默认思考等级被改成了中等这么简单,我同意其他人说的,哪怕把 effort 调到最高,模型‘急于完成任务’的摆烂行为也明显变多了。”