一句话生成无限逼真3D场景量子位
VLM看图像描述头头是道,一遇到3D空间推理就“晕菜”。
物体一多、视角一换,认知底线直接被击穿。
更麻烦的是,想测也测不明白:真实数据集贵且没法调参数,程序生成的3D场景又假又反物理,业界一直缺一套多样化、可扩展且支持完全自定义的测试基准。
为了打破这一僵局,来自匹兹堡大学的研究团队提出了InfiniBench框架,并在最新论文中系统阐述了该方法的核心机制,该论文已被计算机视觉顶会CVPR2026接收。
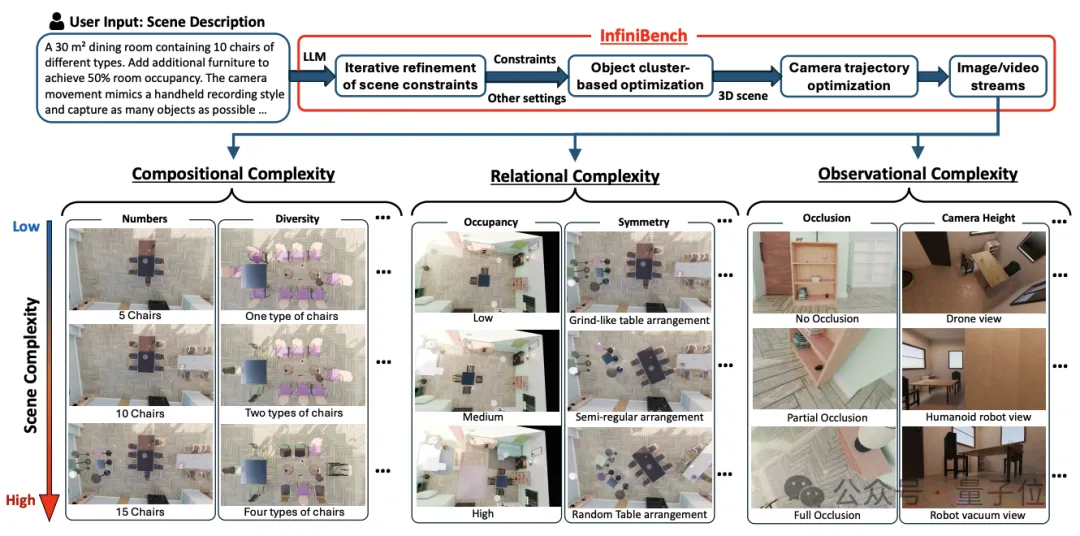
该方法通过引入大模型智能体(LLM Agent)进行迭代优化,并结合创新的“基于簇的布局优化策略”,只需一句自然语言提示词,就能全自动生成理论上无限数量、且高度逼真的3D视频基准测试场景。不仅如此,它还能完全按照用户的意愿,精确控制场景的复杂度。
这项研究不仅为诊断大模型(如Gemini 2.5 Pro、GPT-5等)的空间推理失败模式提供了利器,也为未来VLM的空间感知能力训练指明了方向。
为何需要一个“无限”的基准生成器?
在真实世界的3D空间中,理解物体的摆放、朝向和相互关系,是人工智能走向通用化的关键。但现有评估VLM空间推理能力的数据集存在严重局限:
维度混淆,难以归因:现有测试往往只用简单的“房间数量”来定义复杂度,导致模型一旦回答错误,研究人员根本不知道是因为“无关干扰物体太多”(组合复杂度),还是“物体排列太诡异”(关系复杂度),亦或是“相机视角被严重遮挡”(观察复杂度)。
生成工具的“常识缺乏”:直接用LLM生成3D布局,当物体数量一多,经常会出现“物体穿模”、“悬空”或“超出房间边界”等违背物理常识的失误。而传统的3D程序化引擎虽然符合物理规律,但又很难听懂人类复杂的自然语言指令。
为了实现可定制、高度逼真且物理合理的3D场景生成,匹兹堡大学的研究人员提出了InfiniBench。
InfiniBench不生产固定且僵化的数据集,而是提供了一个全自动的基准生成引擎。你只需要告诉它:“生成一个30平米的餐厅,里面有10把不同类型的椅子,再加点家具让空间占用率达到50%”,它就能自动进行布局规划、物理校验,并最终渲染出一镜到底的视频。
技术方案:大模型智能体与聚类优化的完美结合
InfiniBench的整体管线分为三个核心阶段,彻底分离了“高层语义规划”与“底层物理执行”。
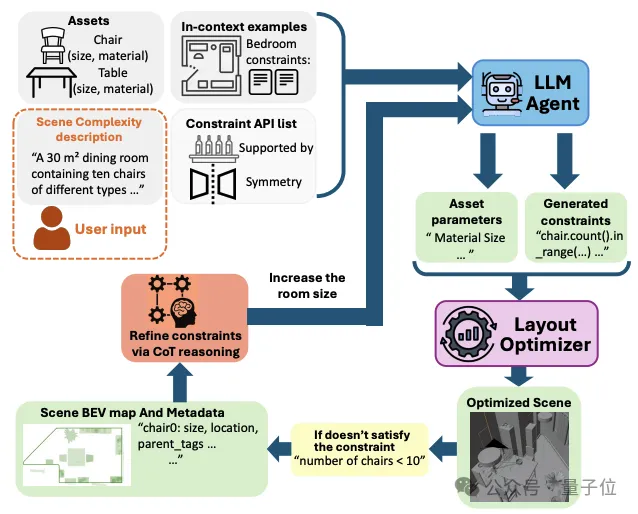
步骤1:大模型智能体迭代生成场景约束(Agentic Generation of Scene Constraints)
传统的程序化3D生成往往需要专家手动编写晦涩的代码脚本。InfiniBench通过引入LLM Agent打破了这一门槛。系统会提供给大模型一套包含可用程序API和少样本示例(Few-shot)的知识库。LLM负责将用户的自然语言需求,翻译成机器可读的约束条件。
亮点在于其“自我反思与修正”机制(CoT反馈循环):
如果生成的约束在物理上行不通(例如,LLM想把3个显示器放在一张普通尺寸的书桌上,显然放不下),底层的布局优化器就会报错,并返回一张带有碰撞信息的“鸟瞰图(BEV)”和错误摘要。LLM接收到反馈后,会启动思维链(CoT)推理,分析失败原因(例如桌面面积不足),从而自动修改约束(例如更换一张更大的书桌),直至生成合理的规划。
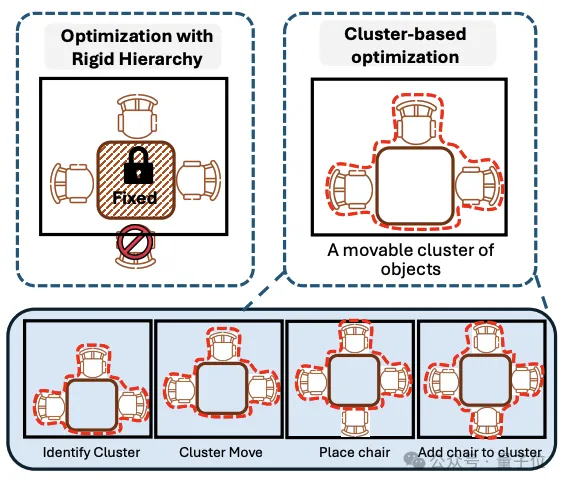
步骤2:突破高密度极限的“基于簇”布局优化(Cluster-based Layout Optimization)
这是InfiniBench超越传统3D生成引擎的核心亮点。当场景复杂度(物体数量、空间占用率)急剧攀升时,传统的“层级优化策略(Hierarchical optimization)”往往会陷入死胡同——它们习惯先固定大物件(如桌子),结果发现剩下的小物件(如椅子)根本塞不进去了。
为了解决这个问题,研究团队创新性地引入了“可移动簇(Movable Cluster)”的概念:
1. 识别簇:系统自动解析场景的语义图,将关系紧密的物体(例如:一张餐桌和它周围的一圈椅子)打包成一个“大块头(父子对象群体)”。
2. 扩展动作空间:在布局优化时,允许整个“簇”在不破坏内部相对位置关系的前提下,作为一个整体移动到房间的更优位置。
3. 碰撞检测:使用整个簇的集体边界框进行物理碰撞检测。
这一极其灵活的策略,使得原本传统算法根本无法生成的“高密度、重度杂乱”场景变得轻而易举,且完全符合物理规律。
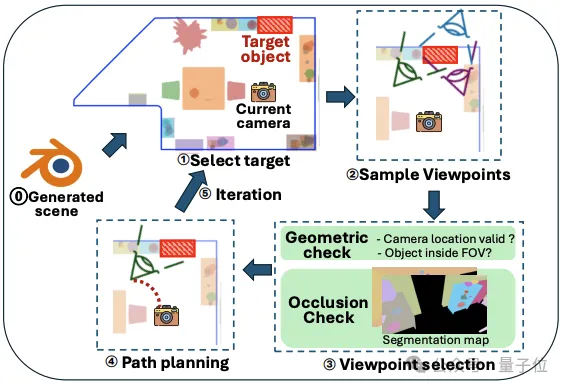
步骤3:任务感知的相机轨迹优化(Camera Trajectory Optimization)
有了3D场景,还需要为VLM提供完美的2D视频输入。一个糟糕的运镜可能会遮挡关键物体,导致VLM无法答题。
受机器人经典导航技术“基于前沿的探索(Frontier-based exploration)”的启发,InfiniBench开发了一套相机轨迹优化算法。
系统会将“未访问的关键物体”视为前沿目标,自动为每个物体采样无遮挡的最佳视角,并利用Dijkstra算法在2D平面图上规划出一条无碰撞的极简导航路径,确保所有与测试任务相关的物体都能被清晰、完整地捕捉在视频镜头中。
实验结果:物理真实度满分,精准定位大模型缺陷
研究人员在多个配置(少/中/多 物体数量,低/中/高 空间占用率)下,将InfiniBench与现有的LLM驱动生成方法(如LayoutGPT、Holodeck)和程序化生成方法(如Infinigen、Luminous)进行了对比。随着场景变复杂,现有方法在“提示词保真度(Fidelity)”和“物理合理性(碰撞率/越界率)”之间往往顾此失彼。
而InfiniBench不仅提示词契合度比肩顶尖LLM方法,更在物理合理性上达到了近乎完美的水平(碰撞数量和越界物体数量均无限逼近于0.0)。