Meta-Harness让Haiku性能狂飙新智元
如果未来的某天,AI智能体可以给自己调参数,修bug,会发生什么?
就在这两天,斯坦福IRIS Lab的博士生Yoonho Lee联合MIT、威斯康星大学的研究者放出一篇新论文,把AI智能体优化的逻辑翻了个个儿。
作者阵容十分豪华。导师是机器人学习明星学者Chelsea Finn,合作者里还有DSPy框架作者Omar Khattab。
曾经,大家卷模型本身的参数量、训练数据、RLHF。但Meta-Harness另辟蹊径:支撑模型运行的那层「脚手架」同样决定生死。
这些东西以前全靠人工调。现在,Meta-Harness让AI自己来干这活。
结果十分完美:Claude Haiku 4.5的成功率达到37.6%,登顶所有Haiku智能体榜首;Claude Opus 4.6更是达到76.4%,仅次于榜一ForgeCode。
模型是商品,Harness决定成败
harness指的是一整套基础设施:系统提示词、工具定义、重试逻辑、上下文管理、子代理协调、生命周期钩子。
模型本身只是个大脑,harness才是让这个大脑能干活的身体。
这个概念在2026年突然爆火,业界终于意识到,同一个模型,换个harness,性能差距可以大到离谱。
2月,工程师Can Bölük做了个实验。
他只改编辑格式,不动模型,15个LLM的编码性能提升了5到14个百分点,输出token还减少了约20%。
更夸张的是,GPT-4 Turbo仅仅换了一种编辑格式,准确率就从26%飙升到59%。
同样的模型,性能差了一倍多,唯一变量是harness。
Agent = Model + Harness,成了最热门的趋势
模型提供智能,harness让智能变得有用。
Claude Code、Codex在做同一件事:精心设计harness来弥补模型的短板。
那么问题来了,harness工程目前高度依赖人工。
工程师得手动写提示词、调工具接口、设计重试策略,然后跑测试、看日志、猜哪里出了问题、改代码、再跑测试。
这个循环费时费力,而且很多失败模式根本不是人能轻易诊断的。
Meta-Harness想做的,就是把这个循环自动化。
400倍信息量:AI自己「复盘+迭代」
Meta-Harness尝试着给优化器看更多东西。听起来简单,但这恰恰是过去所有方法的瓶颈。
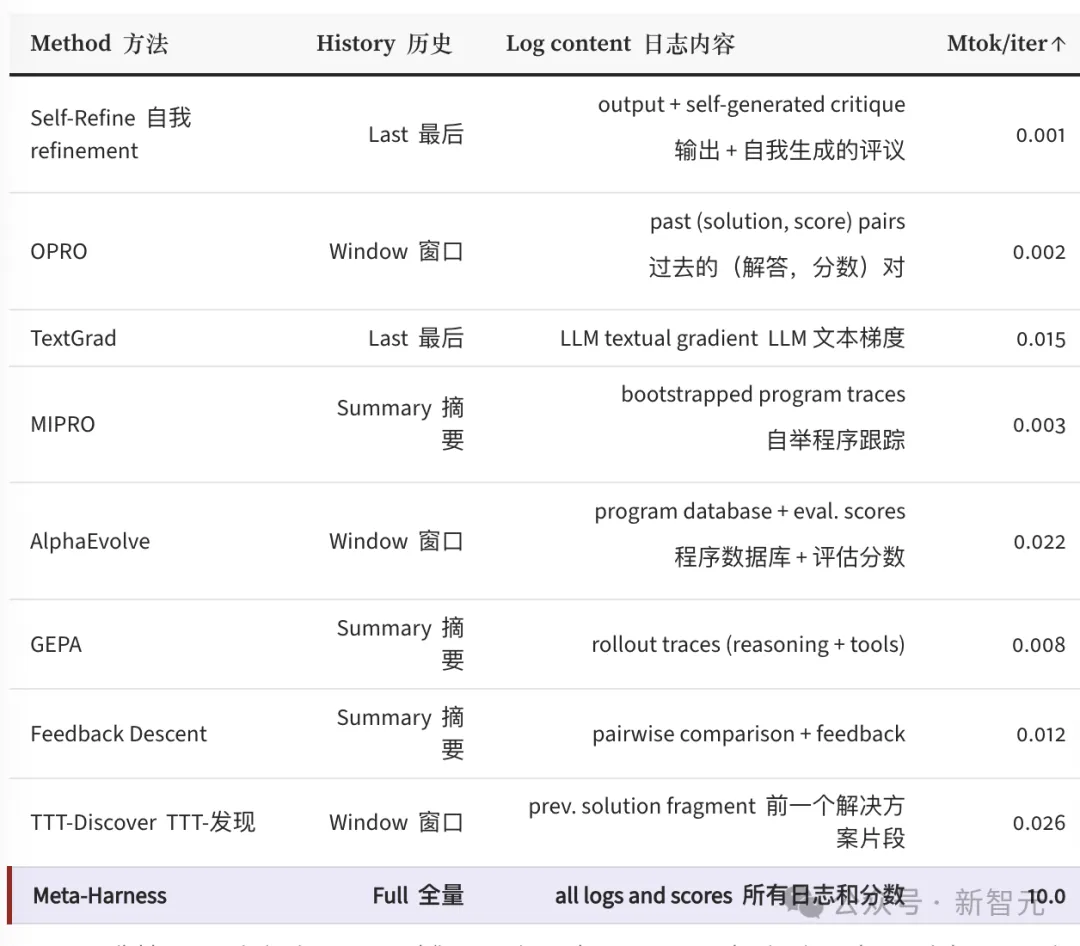
论文这张对比表,列出了主流文本每一步能看到多少上下文:
Meta-Harness 与主流优化方法的上下文观察量对比。
Self-Refine只看最近一次输出加自我批评,大约1000 token;
OPRO看过去几轮的方案和分数,大约2000 token;
TextGrad、AlphaEvolve、GEPA这些更先进的方法,也就在8000到26000 token之间。
Meta-Harness呢?最高1000万token,差距是400倍。
为什么需要这么多?因为harness工程产生的失败模式,往往藏在执行轨迹的细节里。
一个任务跑失败了,原因可能是十步之前的某个工具调用返回了截断的输出,导致后续推理全歪。
如果优化器只能看到一个「失败」的标量分数,或者一段压缩过的摘要,它根本没法定位问题。
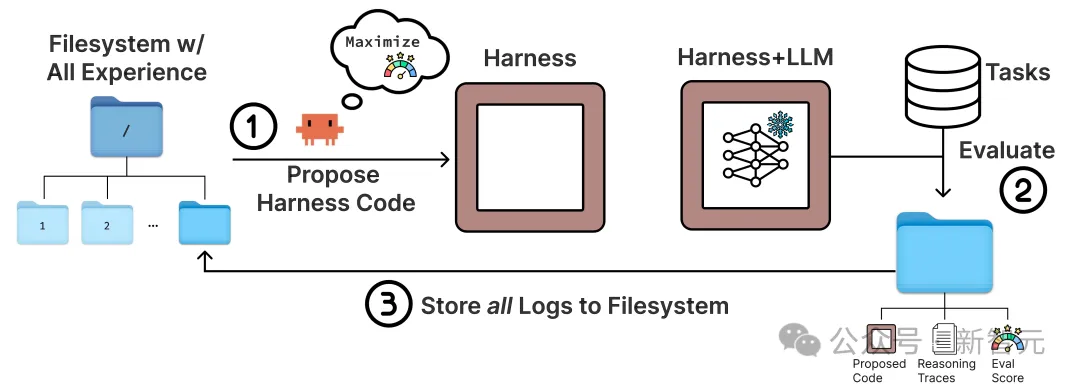
Meta-Harness的做法,是给proposer一个完整的文件系统。
这个文件系统里装着所有历史候选harness的源代码、每一轮的执行轨迹、命令日志、错误信息、超时行为、评分结果。
Proposer可以用grep、cat这些标准工具自己去翻,想看哪个文件就看哪个,想搜哪个关键词就搜哪个。
优化器不再是在固定prompt上做推理,而是一个会检索信息、浏览历史、编辑代码的代理。
proposer用的是Claude Code,它不需要被喂压缩过的信息,它有能力自己决定看什么、怎么看。
整个搜索循环很直白:
Proposer读取文件系统里的历史记录
分析哪些任务失败了、失败原因是什么
针对性地重写harness代码
新harness跑测试,结果写回文件系统
Meta-Harness 核心优化闭环示意图。Proposer 从“包含全部历史经验”的文件系统读取完整轨迹(①),提出新的 Harness 代码 → 结合 LLM 执行任务并评估(②)→ 将 Proposed Code、Reasoning Traces、Eval Score 等全部日志存回文件系统(③),实现自我迭代。
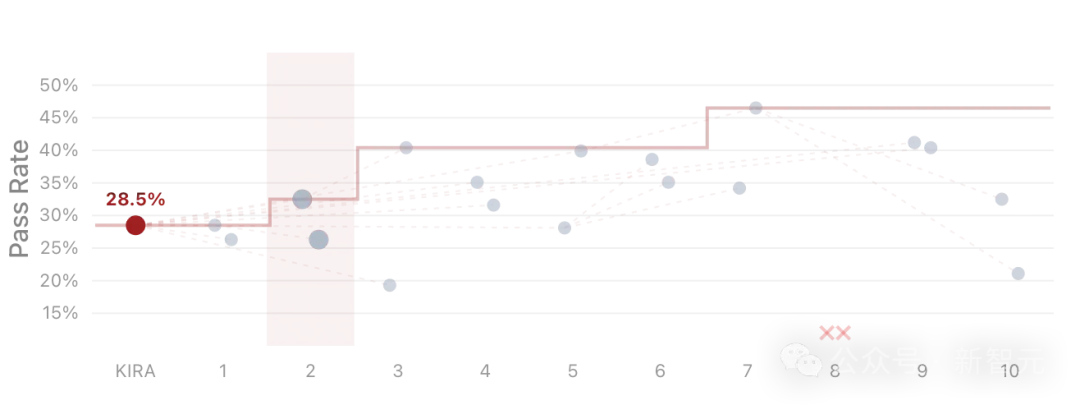
论文展示了一个19任务子集上的搜索过程。
从Terminus-KIRA基线的28.5%起步,到第7轮迭代就涨到了46.5%。
Meta-Harness 在 19 任务子集上的迭代优化过程。从 Terminus-KIRA 基线 28.5% 的成功率起步,第 7 轮迭代达到 46.5%,展示了通过完整执行轨迹诊断实现的高效 harness 优化。
每一轮都基于具体的执行轨迹做「反事实诊断」——如果我当时这样处理,结果会不会不一样?
举个例子,第7轮的改进是在第一次LLM调用之前先跑一条shell命令,把环境依赖信息注入到初始prompt里。
加一条命令,省掉无谓的试错。 这种程度的诊断精度,靠压缩摘要是做不到的。
89个任务,小模型登顶
Meta-Harness分了三个场景做了测试:文本分类、数学推理、代码代理。
代码代理用的基准是TerminalBench-2,它包含89个Docker化任务,覆盖代码翻译、分布式机器学习配置、系统编程、生物信息学、密码分析等领域。