Fable 5解禁,Anthropic同步发Sonnet 5模型抢人苏扬
Fable 5回归在即,Anthropic连夜发了一款中端模型抢用户。
Anthropic CEO达里奥·阿莫迪。图片由AI生成
美国当地时间6月30日,Anthropic发布了Claude Sonnet5,并将其定位为“迄今为止智能体能力最强的Sonnet模型”。
Anthropic表示,模型能自主制定计划,调用浏览器和终端等外部工具,在没有人工干预的情况下独立完成多步骤任务。
Anthropic在官方博客中写道,智能体时代对很多开发者来说始于Sonnet级别模型,Claude Sonnet3.5、3.6和3.7是首批在编码和工具使用方面展现出技能的模型,但近期智能体能力最显著的提升主要来自Opus级别。
Sonnet 5的作用是把这种能力往下放,让中端模型也能做到过去需要旗舰模型才能完成的事。
价格方面,8月31日前,输入每百万token 2美元,输出每百万token 10美元,之后回调为标准定价,输入每百万token3美元,输出每百万token 15美元。
作为对比,Opus 4.8的定价是输入5美元、输出25美元。按标准定价计算,Sonnet 5每百万token的成本比Opus4.8低约六成。
值得注意的是,此前因为安全问题被下架的Fable 5系列模型将迎来转机。
美国商务部长卢特尼克在社交平台X上发帖称,在过去的两个星期里,我们与Anthropic密切合作,对Fable5进行了分析与批准,以确保美国政府内部达成一致,暗示这款被誉为Anthropic史上最强模型即将回归。
随后,Anthropic回应称,已收到通知,Claude Fable5和Mythos5将于明天(当地时间7月1日)开始恢复访问。
Anthropic回应Fable 5解禁
01 基准测试全面跳涨,一项评估直接反超Opus
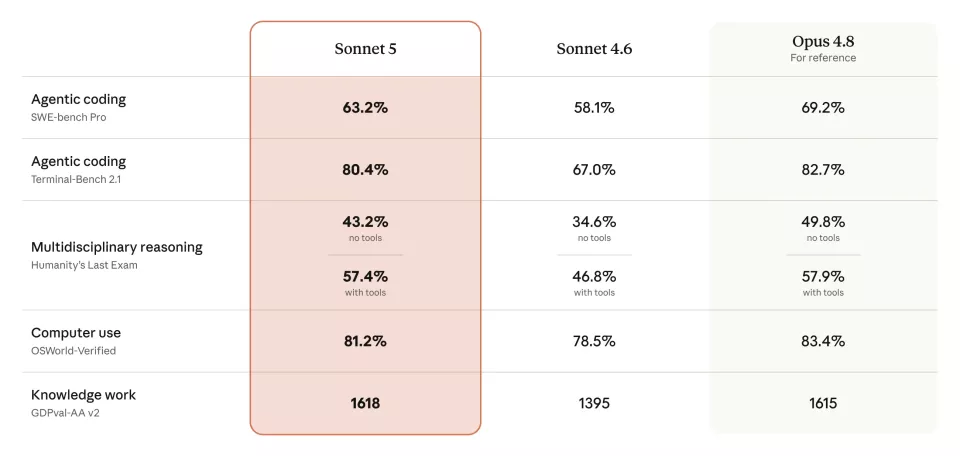
Anthropic公布了五项主要评估成绩,Sonnet 5在所有项目上均较前代Sonnet 4.6有明显提升。
Sonnet 5在五项主要评估中缩小了与旗舰模型Opus的差距,并在其中一项上实现反超
在智能体编码基准SWE-bench Pro上,Sonnet 5得分63.2%。Sonnet 4.6为58.1%,Opus4.8为69.2%。差距从前代的11.1个百分点缩小到6个百分点。
在Terminal-Bench 2.1编码评估中,Sonnet 5拿到80.4%。Sonnet 4.6只有67.0%,Opus4.8为82.7%。这项评估上Sonnet 5较前代提升了13.4个百分点,与Opus 4.8的差距只剩2.3个百分点。
多学科推理方面,评估用的是Humanity‘s LastExam。Anthropic在此次发布中更新了这项考试评分模型,并将Sonnet4.6的得分修正为34.6%(无工具)和46.8%(有工具),与Sonnet 4.6发布博客中报告的数字不同。
Sonnet 5在无工具条件下得分43.2%,有工具辅助下得分57.4%。有工具时57.4%的成绩与Opus4.8的57.9%基本持平,差距仅0.5个百分点。
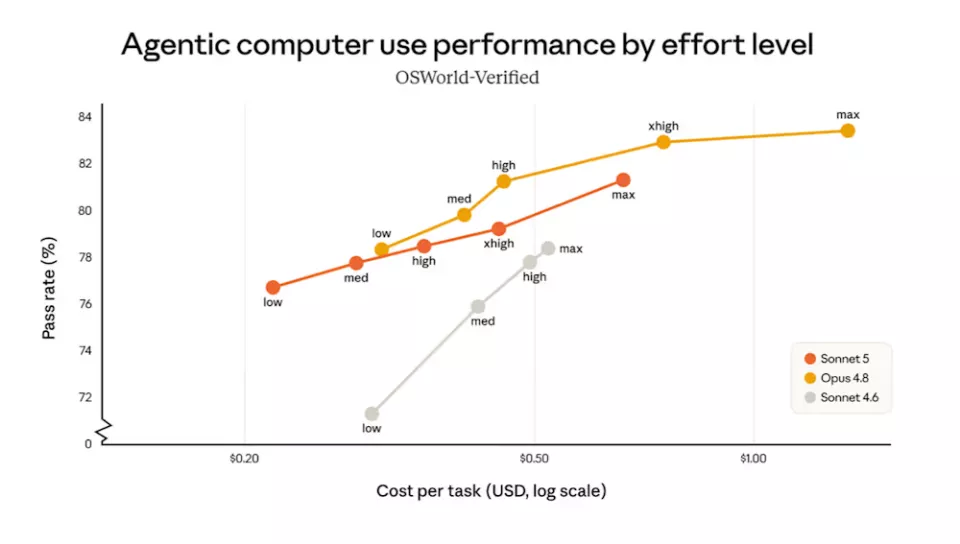
计算机使用评估OSWorld-Verified,Anthropic同样调整了评估方式,使其更准确反映模型在真实世界中的表现。Sonnet4.6的得分由此更新为78.5%。Sonnet 5的得分是81.2%,提升了2.7个百分点。
在计算机使用任务上,Sonnet 5以更低的单任务成本,接近了Opus 4.8的准确度
知识工作基准测试GDPval-AA v2是Sonnet 5唯一直接超过Opus 4.8的项目。Sonnet5得分1618分,Sonnet 4.6为1395分,Opus 4.8为1615分。
Anthropic在官方博客中表示,从这些评估结果来看,Sonnet 5的进步幅度很大,性能已经跃升到了与Opus4.8大幅重叠的层级。
02 未进行特殊安全训练
Anthropic在部署前安全评估中对Sonnet 5做了多项测试,结论是相比Sonnet 4.6整体有所改进。
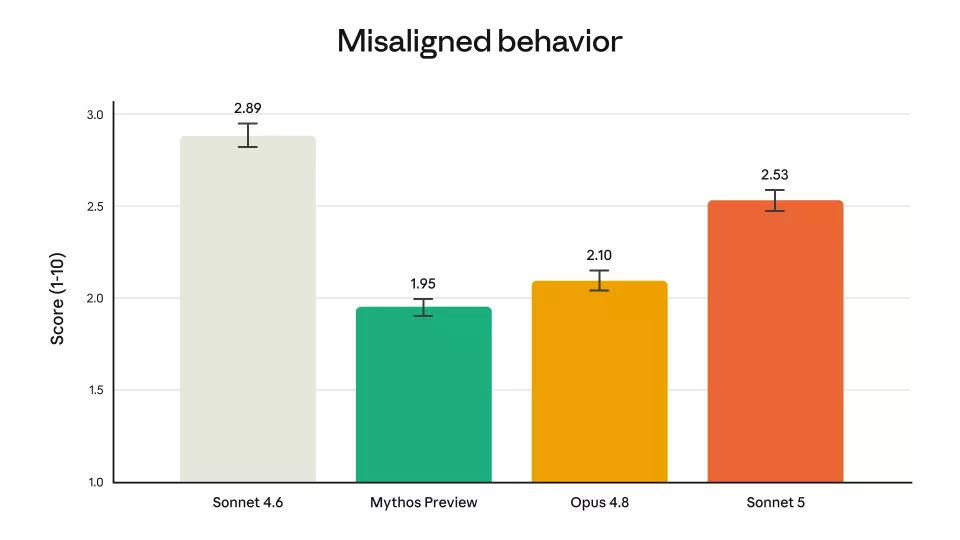
在智能体安全方面,Sonnet 5更擅长拒绝恶意请求,抵抗提示注入攻击劫持的能力也更强。出现幻觉和谄媚行为的比率较Sonnet4.6更低。在自动化行为审计中,测试范围覆盖了配合滥用、欺骗等广泛的不当行为,Sonnet 5的总体得分低于Sonnet4.6,即不当行为发生率更低,更安全。
Anthropic能力更强的模型,不当行为发生率比Sonnet 5更低,但Sonnet 5相较前代已有明显改善
与Opus 4.8和Claude Mythos Preview相比,Sonnet5在相同审计中显示出略高的不当行为发生率。Anthropic的安全评估是一套梯度体系:模型能力越强,安全对齐表现越好。Sonnet5处于中间位置,优于前代但不及旗舰模型。
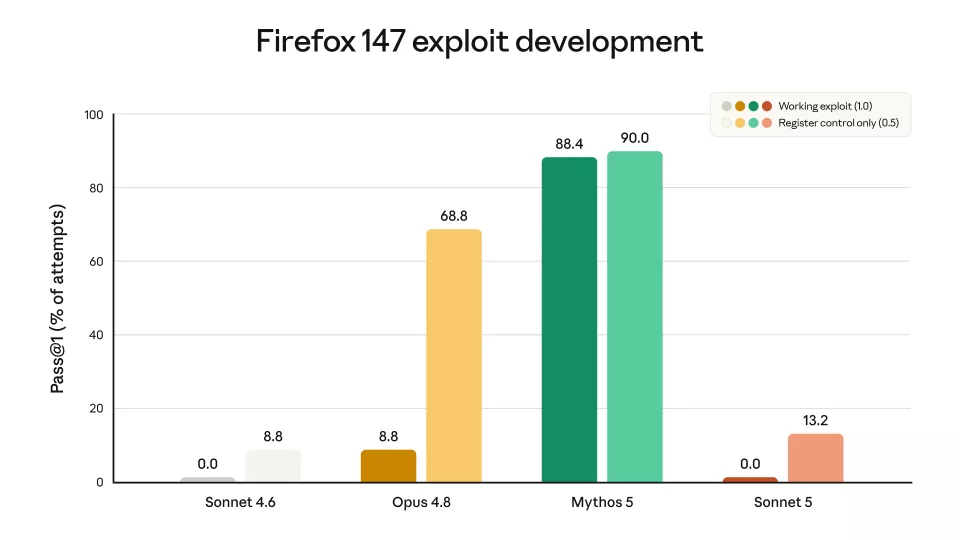
在网络攻击能力方面,Anthropic与Mozilla合作进行了评估,测试模型为Firefox147浏览器中的漏洞开发利用程序的能力。相关漏洞已在Firefox 148中修补。
两个Sonnet模型都未能针对Firefox漏洞生成可利用程序,而Mythos 5的成功率接近90%
两个Sonnet模型均未能成功开发出可用的漏洞利用程序,成功率为0.0%。Sonnet 5的部分成功率为13.2%,Sonnet4.6为8.8%。与之相比,Opus 4.8的漏洞利用成功率为68.8%,Mythos5为88.4%。两个Sonnet模型与旗舰模型在网络攻击能力上的差距在一个数量级以上。
Anthropic表示没有特意针对网络安全任务训练Sonnet 5。该公司分析认为,Sonnet5在部分成功率上的微小提升很可能来自通用智能的改善,而非专项训练。它可以执行一些常规、无害的网络任务,但在开发软件漏洞利用等有潜在危险的技能上,远低于Opus和Mythos系列。
由于Sonnet5在这类任务上比前代稍强,Anthropic默认启用了网络安全防护功能。这套防护系统可实时检测并阻止危险的网络使用行为,防护等级与Opus4.7和4.8上的相同。
与之对照,Fable 5的防护措施更为严格,会拦截范围更广的网络安全任务。Anthropic对Sonnet5的整体网络风险判断为较低水平,因此没有采用最严等级的防护。对于需要较少防护的网络安全工作,Anthropic推荐使用Opus4.8。