Token工厂:从“堆GPU”到“榨Token”华尔街日报
Token 工是以 Token 吞吐量为核心产出指标的新一代 AI 基础设施。其运营目标不再是简单提供 GPU 算力,而是将电力、GPU、网络和模型高效转化为持续输出的 Token 流,并最终转化为智能服务和收入由于 Token 吞吐量直接决定了 AI 工厂的收入能力和资本回报率(ROI),如何高效榨取有限资源、最大化单位 GPU 和单位功耗所产生的 Token 数量,正在成为 AI 基础设施竞争的新焦点。在这一过程中,竞争逻辑也正在从“拥有多少 GPU”转向“如何让 GPU 生产更多 Token”。
智算产业正在从资源竞争进入效率竞争阶段
在 scaling law 的大背景下,过去智算中心的北极星指标是 GPU 资源的尽可能堆砌。谁拥有最多的 GPU,谁就掌握了行业的核心竞争力。然而,市场逐渐发现,拥有足够多的 GPU 可能只是最初的竞争门槛,但却并不以足以构建长期的竞争价值。这背后的原因是因为 GPU 只是最初的生产资料之一,但是市场最终需要的是带有生产力的 Token,而 Token 的生产还需要许多其他的能力,比如电,比如网络等等,调度能力和推理优化也非常重要。对于智算中心来说,只单纯的拥有 GPU 数量却在其他方面有所缺失,那么同样量级的资源可能就会产生非常大的资源浪费。这样的时代背景下,Token 工厂顺势而生。Token 工厂是指在 AI 推理时代,数据中心从传统的“数据存储仓库”转型为专门生产 AI 生成基本单位——Token(词元)的工业化生产设施。
Token 工厂:以 Token 吞吐量为核心产出指标的新一代 AI 基础设施
Token 工是以 Token 吞吐量为核心产出指标的新一代 AI 基础设施。其运营目标不再是简单提供 GPU 算力,而是将电力、GPU、网络和模型高效转化为持续输出的 Token 流,并最终转化为智能服务和收入。正如英伟达黄仁勋所提出的,AI 工厂的本质是将能源转化为 Token,再将Token 转化为实际价值,而 Token 正逐渐成为衡量 AI 生产力的核心单位。 由于 Token 吞吐量直接决定了 AI 工厂的收入能力和资本回报率(ROI),如何高效榨取有限资源、最大化单位 GPU和单位功耗所产生的 Token 数量,正在成为 AI 基础设施竞争的新焦点。在这一过程中,竞争逻辑也正在从“拥有多少 GPU”转向“如何让 GPU 生产更多 Token”。
AI 系统软件栈决定了 Token 工厂的资源转化效率
在 AI 时代,GPU 已经逐渐成为标准化的算力资源,其性能决定了 Token 工厂的理论生产能力上限,而真正决定既定的算力资源能够释放多少价值的,则是覆盖调度平台、推理引擎、编译器和模型优化在内的 AI 系统软件栈。相比传统云时代主要依赖硬件扩容提升计算能力,Token工厂更强调通过软件持续挖掘存量算力的生产效率,即以更少的 GPU、更低的功耗生产更多的 Token。本报告中将主要讨论两项核心能力:1)以调度平台为核心,通过各项技术提高 GPU利用率,减少资源碎片化和空闲时间,让更多 GPU 真正投入 Token 生产。2)以芯模协同为核心,通过芯片架构、编译器、推理框架与模型结构的联合优化,提高单位 GPU 的 Token 生成效和单位功耗性能,进一步释放硬件潜力。
从行业实践来看,先进调度系统和芯模协同带来的收益已经凸显
从行业实践来看,先进调度系统和芯模协同带来的收益已经得到越来越多生产环境的验证。近年来,无论是以 CoreWeave、Google、阿里云为代表的云厂商,还是以 Deepseek 为代表的模型厂商,都已将优化重点从单纯提升硬件性能转向提升系统整体效。展望未来,随着 GPU硬件逐渐标准化,AI 基础设施的竞争优势将越来越多地来自系统软件能力。无论是海外的NeoCloud、云计算厂商还是模型、芯片厂商,都将围绕调度平台、推理引擎和芯模协同持续构建差异化竞争力。
Token 工厂的出现标志着智算产业正在从资源竞争进入效率竞争阶段
从“堆资源”到“榨资源”,行业北极星指标或发生本质变化
在 scaling law 的大背景下,过去智算中心的北极星指标是 GPU 资源的尽可能堆砌。谁拥有最多的 GPU,谁就掌握了行业的核心竞争力。然而,市场逐渐发现,拥有足够多的GPU 可能只是最初的竞争门槛,但却并不以足以构建长期的竞争价值。这背后的原因是因为 GPU 只是最初的生产资料之一,但是市场最终需要的是带有生产力的 Token,而 Token 的生产还需要许多其他的能力,比如电,比如网络等等,调度能力和推理优化也非常重要。对于智算中心来说,只单纯的拥有 GPU 数量却在其他方面有所缺失,那么同样量级的资源可能就会产生非常大的资源浪费。
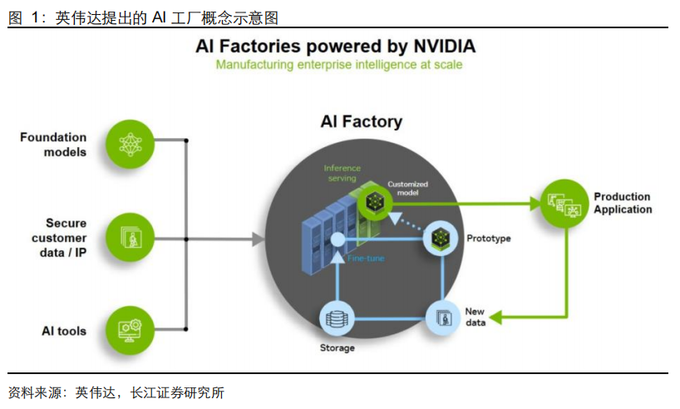
这样的时代背景下,Token 工厂顺势而生。Token 工厂是指在 AI 推理时代,数据中心从传统的“数据存储仓库”转型为专门生产 AI 生成基本单位——Token(词元)的工业化生产设施。这一概念最早由英伟达 CEO 黄仁勋在 2024 年提出,并在 2026 年的 GTC大会上系统阐述了其背后的“Token 工厂经济学”。从产业链地位上看,Token 工厂是一种介于单纯的算力提供方和下游实体企业中间的角色,和云计算处于相近的产业链地位。
Token 吞吐量直接决定 Token 工厂的收入
Token 工厂的出现可能意味着过去以“堆资源”为核心的产业逻辑正式朝着“榨资源”的方向转型,而不同商业模式所对应的北极星指标(最终目标)也悄然发生了根本性的变化。
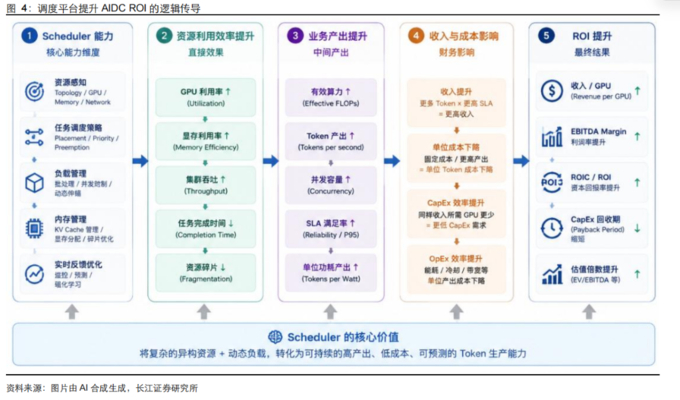
Token 工厂的收入公式为 Token 调用量×Token 的定价,二者共同作用决定了 Token 工厂的总收入。从这个公式中我们发现,过去智算中心主要关注资源的多寡,但现在 Token工厂北极星指标变成了有限资源的 Token 生产效率(目前的常用指标是 token/s 或token/任务)。谁能在相同的资源保有量基础上生成更多的 Token,谁就将获得更多的收入。
如何提升“榨资源”的效率?从与单纯的算力提供方相比,Token 工厂最核心的增量能力在于每家工厂自有的算力调度平台。不论是行业案例还是论文实验,都反复验证调度平台之于 Token 工厂效率提升的重要性。
AI 系统软件栈决定了 Token 工厂的资源转化效率
调度层面优化:AI 云调度能力的重要性超过了传统云
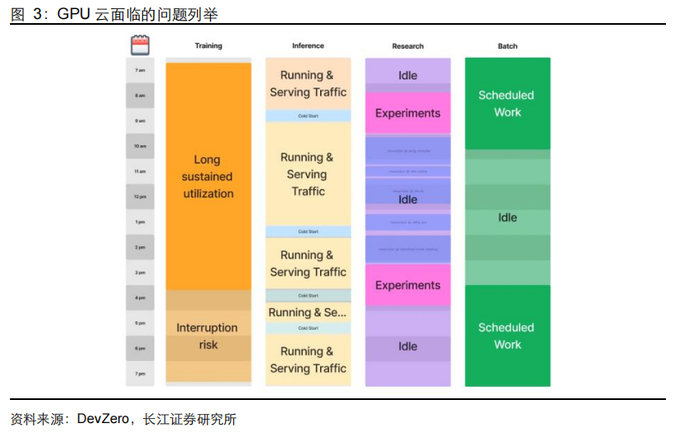
如果说传统云时代的调度是单纯的“资源调度”,那么 AI 云时代的调度系统就是“多维瓶颈系统”。传统云时代所接收的请求一般具备短、独立、相对可预测的特征(比如双十一的访问需求量暴增,但是相对在一个可预测的区间),CPU 云的调度系统主要任务是将任务放进机器即可。与传统云主要优化 CPU 利用率不同,AI 云面临 GPU 碎片化、KV Cache 碎片化和 Gang Scheduling 等独特挑战。因此,调度系统重要性在 AI 时代更为凸显。
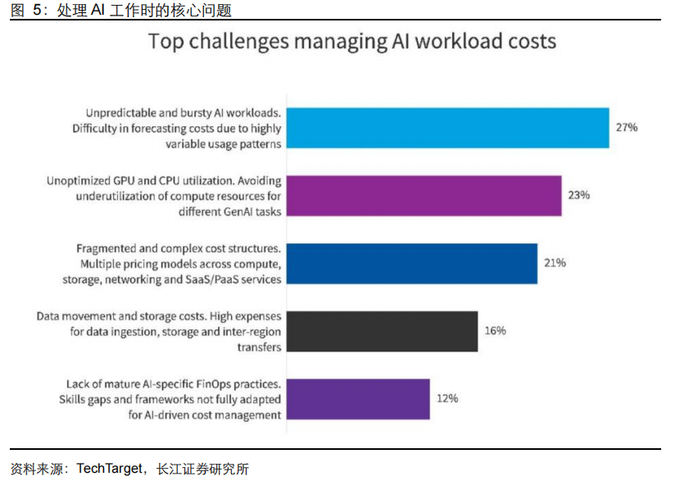
从行业实际使用情况看,GPU 资源的碎片化等问题较为常见。根据 TechTarget 在 2026年 3 月发布的一份行业统计数据看,参与者在选择管理 AI 任务成本时面临的最核心问题时,23%的参与者选择了“并非最优的 CPU 和 GPU 利用率”,21%的参与者选择了“破碎及复杂的成本结构”,实际上都反应了 AI 云在实际使用中的问题。
国内外 GPU 云和智算中心核心玩家皆在不同层级上做出了多样化的尝试
如何解决上述问题?国内外 GPU 云和智算中心核心玩家皆在不同层级上做出了多样化的尝试,分别从资源观测、资源共享、集群调度以及 Token 级调度等不同层级展开探索。
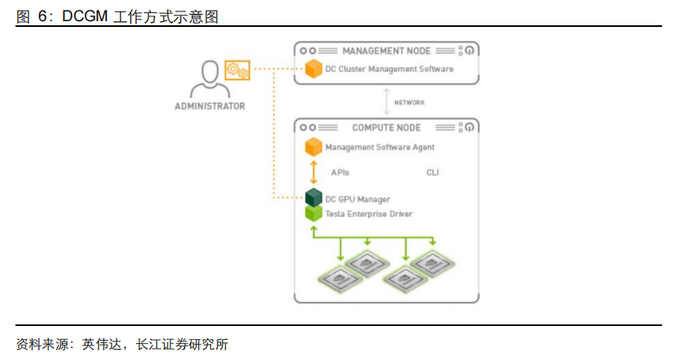
英伟达:DCGM 系统,解决 GPU 调度的黑盒问题
在资源观测层,英伟达推出 DCGM((Data Center GPU Manager),通过实时采集 GPU利用率、HBM 显存、NVLink 带宽、功耗和温度等关键指标,为调度系统提供统一的数据基础。DCGM 虽然本身并不负责调度,但解决了 GPU 集群“看不见”的问题,为后续资源优化提供决策依据。换言之,DCGM 之于 AI 云调度,相当于传感器之于自动驾驶系统