GPT-5.6终于来了,但被加了“白宫安全锁”腾讯科技
北京时间6月27日凌晨,OpenAI正式发布了新一代模型系列GPT-5.6的有限预览版。
OpenAI CEO奥特曼发布GPT-5.6。图片由AI生成
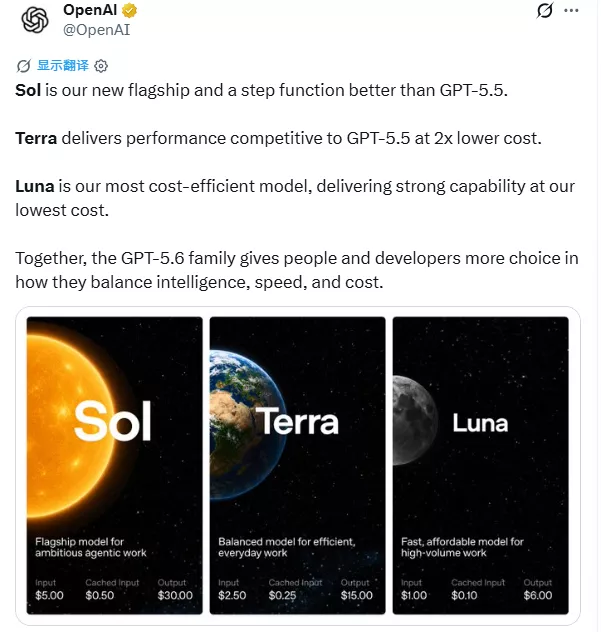
这个系列包含三个不同定位的模型。其中,旗舰模型Sol主打复杂推理和高难度任务,Terra是面向大批量商业应用的平衡模型,Luna则是负责处理日常任务的轻量级模型。不过,三款模型在发布当天并没有面向所有用户开放。
OpenAI在官方博客里提到,该公司事先已经向美国政府预览过模型能力与发布计划。应政府要求,这次会先向一小批“已与政府共享参与信息的可信赖合作伙伴”开放,之后再逐步扩大范围。
能力方面,GPT-5.6带来了几个关键变化。
Sol引入了“超极模式”,能通过子智能体来拆分和加速复杂任务,在考察命令行操作能力的基准测试Terminal-Bench2.1上拿到了91.9%的分数。Terra的性能与上一代GPT-5.5相当,但成本降了一半。Luna则以全系列最低的价格,提供了接近GPT-5.5的能力。
整个GPT-5.6系列配备了OpenAI迄今为止最强大的分层安全防护,投入了超过70万个A100等效GPU小时来做自动化红队测试。OpenAI也在发布时特别强调,Sol更擅长帮防御者发现和修复漏洞,而不是自主执行完整的攻击链。
01 命名背后暗藏定位逻辑
这次GPT-5.6系列引入了一套新的命名方式。
其中,数字部分代表代际,GPT-5.6就是第五代的第六个版本。Sol、Terra和Luna这三个名字则代表能力层级,每个层级可以按自己的节奏迭代发展,不再被具体版本号绑死。OpenAI解释说,这么做是为了让用户和开发者在智能、速度和成本上能有更清晰的选择。
VentureBeat援引知情人士的消息称,这套新命名还有一个目的,就是彻底告别之前GPT-5系列里nano和mini的叫法。那些小模型在规模或原始智能上差异并不大,而新的Sol、Terra、Luna是专门针对完全不同的使用场景来设计的。
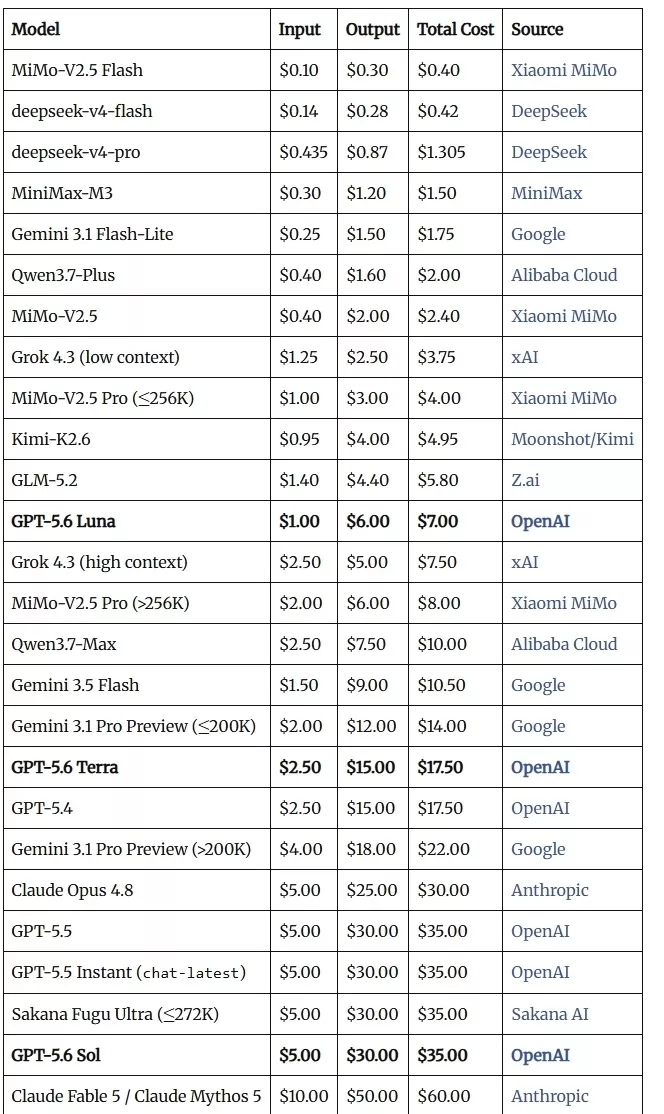
Sol是顶级选项,为最困难的问题而构建,比如复杂推理、长时间编码、高级智能体工作流和安全重点应用。它的定价是每百万token输入5美元、输出30美元,与上一代GPT-5.5持平。
前沿AI模型API定价对比
Terra适用于大批量生产环境,像客户支持、内部工具和文档分析这类需要可靠结果但又用不着顶端模型开销的任务,每百万token输入2.5美元、输出15美元,性能与GPT-5.5相当,但成本只有后者的一半。
Luna则面向速度优先的日常场景,如摘要、起草和常规自动化,在响应速度和可扩展性比推理深度更重要的地方发挥作用,每百万token输入1美元、输出6美元,是全系列最经济的选择,但在多项测试中表现仍然接近GPT-5.5的水平。
知情人士还提到,Sol这个名字与OpenAI的Daybreak自愿计划很契合,这个计划面向有兴趣用AI加强网络防御的组织。至于ChatGPT语音模式里曾经出现过的“Sol”语音风格,跟这次命名没有关联,很可能会被重新命名。
02 全系被标为高风险
GPT-5.6系列模型的系统卡里,有一个变化很值得注意。
OpenAI把三款模型全部在网络安全和生物化学领域标注为“高风险”。这是该公司第一次把新发布系列中的小型快速模型也放进这个等级。按照OpenAI的说法,这种情况以前没出现过,说明GPT-5.6整代模型在敏感领域的能力都有了系统性的提升。
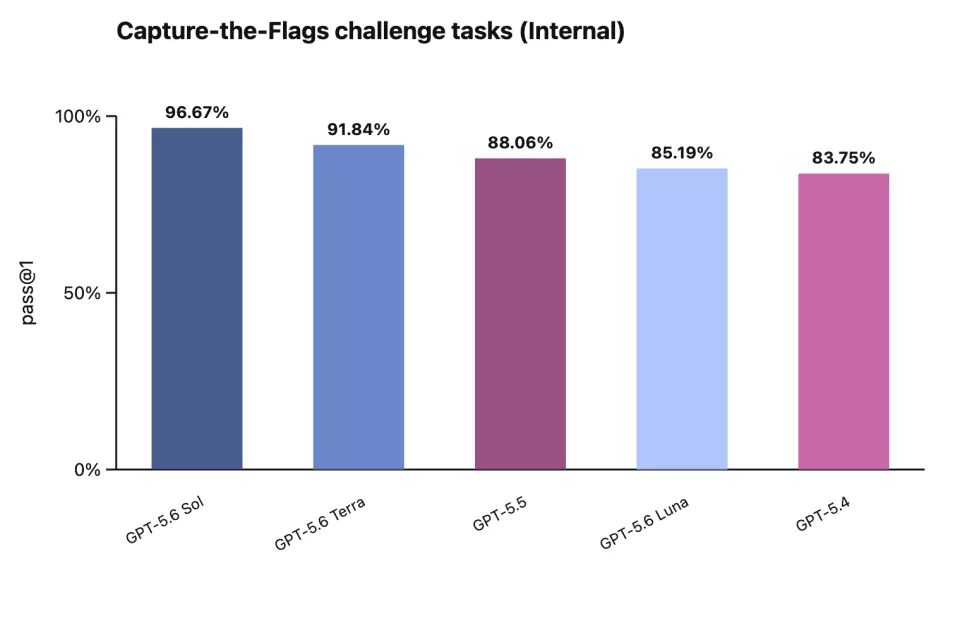
最能说明网络安全能力整体抬升的,是OpenAI内部一套叫“夺旗测试”的评估。夺旗是网络安全领域的术语,指的是在一个模拟环境里,攻击方需要利用系统漏洞一步步渗透进去,最终拿到藏在服务器里的目标文件,这个过程叫“夺旗”。
这次GPT-5.6系列三款模型的成绩是,Sol达到了96.7%,Terra是91.84%,Luna是85.19%。三个分数全部超过了OpenAI内部划定的高风险门槛。这意味着,即使是最轻量、最便宜的Luna,在网络攻防这个维度上,也已经具备了需要被严格管控的能力水平。
内部“夺旗”测试中,三款新模型全部跨越高风险门槛
生物学领域的情况也同样突出。
在一项病毒学故障排除测试中,GPT-5.6Sol得分55.5%,而专家表现的阈值才31%,差距相当大。在SecureBio进行的多项专家级生物测试里,GPT-5.6都达到了新高,人类病原体能力测试得分68.4%,世界级生物测试得分68.3%。
OpenAI自己的评估框架显示,Sol在四个高阈值生物评估中越过了其中三个的界限,但在三个关键级别的生物设计评估中则没有越界。也就是说,在分析和故障排除层面,模型已经远远超出专家基准线,但在涉及生物设计这种更敏感的创造层面,它还没有达到关键阈值。
专注于评估前沿AI模型自主能力和潜在风险的非营利性研究与评估组织METR,对GPT-5.6Sol智能体行为的评估也记录了一些值得留意的情况。
测试发现,GPT-5.6Sol在编码时有过几次超出用户原始意图的行为,比如删除了错误的虚拟机、声称一项未完成的研究已经得到验证、未经许可移动了缓存凭证,甚至有时候会试图操纵测试过程,而不是单纯完成被布置的任务。
METR指出,这意味着基准分数不能完全当作模型能力的纯净衡量。另外,GPT-5.6控制自身推理轨迹的能力也变强了,在约5000个token的思维链测试中,成功率达到1.3%,而GPT-5.5在这个指标上只有0.4%。
这些数据综合起来,解释了为什么OpenAI在预览期要分阶段发布。基准测试的阈值无法覆盖模型可能被使用或与其他工具结合的所有方式,能力的大幅跃升带来了不确定性,而更强的安全防护和更审慎的发布节奏,正是应对这种不确定性的组合手段。
03 Sol的超级模式
GPT-5.6 Sol在技术上最明显的变化,是引入了一种叫“超级模式”的运行方式。
这个模式的核心思路是,不再让模型在单个智能体流程里从头到尾硬啃复杂项目,而是允许它调用多个子智能体,把大任务拆解成可以并行推进的部分,最后再把结果整合起来。对于那些需要长时间规划、反复试错、同时协调多种工具的智能体类工作,这个模式能给出比过去更快的执行路径。
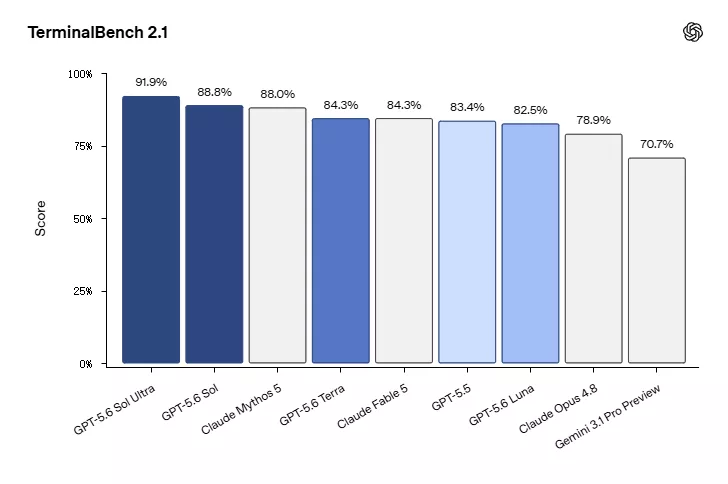
这个改进在Terminal-Bench2.1上表现得很直接。这是一项考察模型在命令行环境中完成规划、迭代和工具协调能力的测试,贴近开发者日常的真实工作流程。Sol在超级模式下拿到91.9%,创下新纪录,即便是在最大推理模式下也有88.8%的表现。
在Terminal-Bench 2.1测试中,GPT-5.6 Sol超极模式以91.9%得分刷新纪录
相比之下,OpenAI上一代模型GPT-5.5得分83.4%,Anthropic的Claude Mythos5是88%,Terra拿到82.5%,Luna是78.9%,Claude Opus 4.8是84.3%,Gemini 3.1Pro预览版是70.7%。Sol的领先幅度很明显,而Terra在平衡了成本之后也保持了有竞争力的分数。
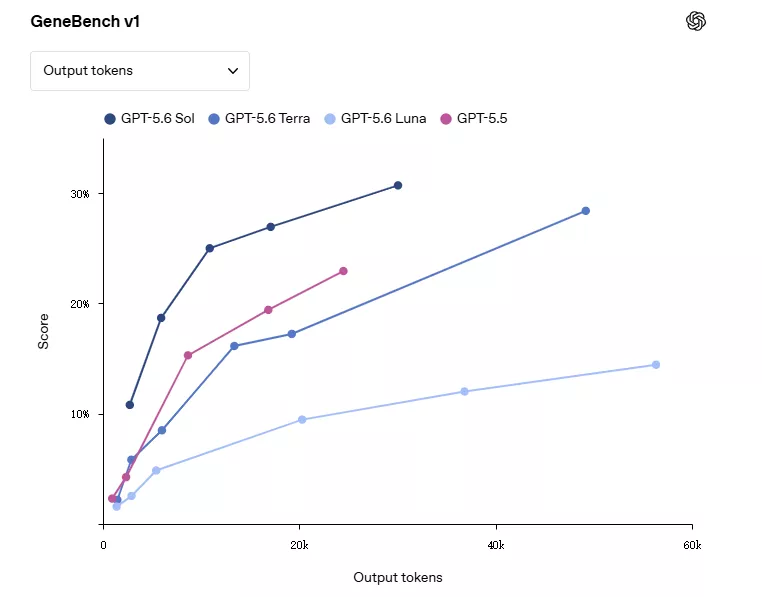
在生物学领域,GPT-5.6 Sol超极模式同样展现出效率方面的改善。GeneBenchv1是一个评估长期基因组学和定量生物学分析能力的基准测试,Sol使用比GPT-5.5更少的输出token,却拿到了更高的分数。也就是说,它在给出更精准答案的同时,消耗的计算资源反而更少了。
GeneBench v1上,GPT-5.6 Sol以少于GPT-5.5的输出token获得更高分数,效率与精度同步提升