DeepSeek们最狠的大招藏在招人里新智元
Epoch AI调查了6家中国AI公司1604个岗位,从经验门槛到出海路线,招聘里到底都有哪些牌。
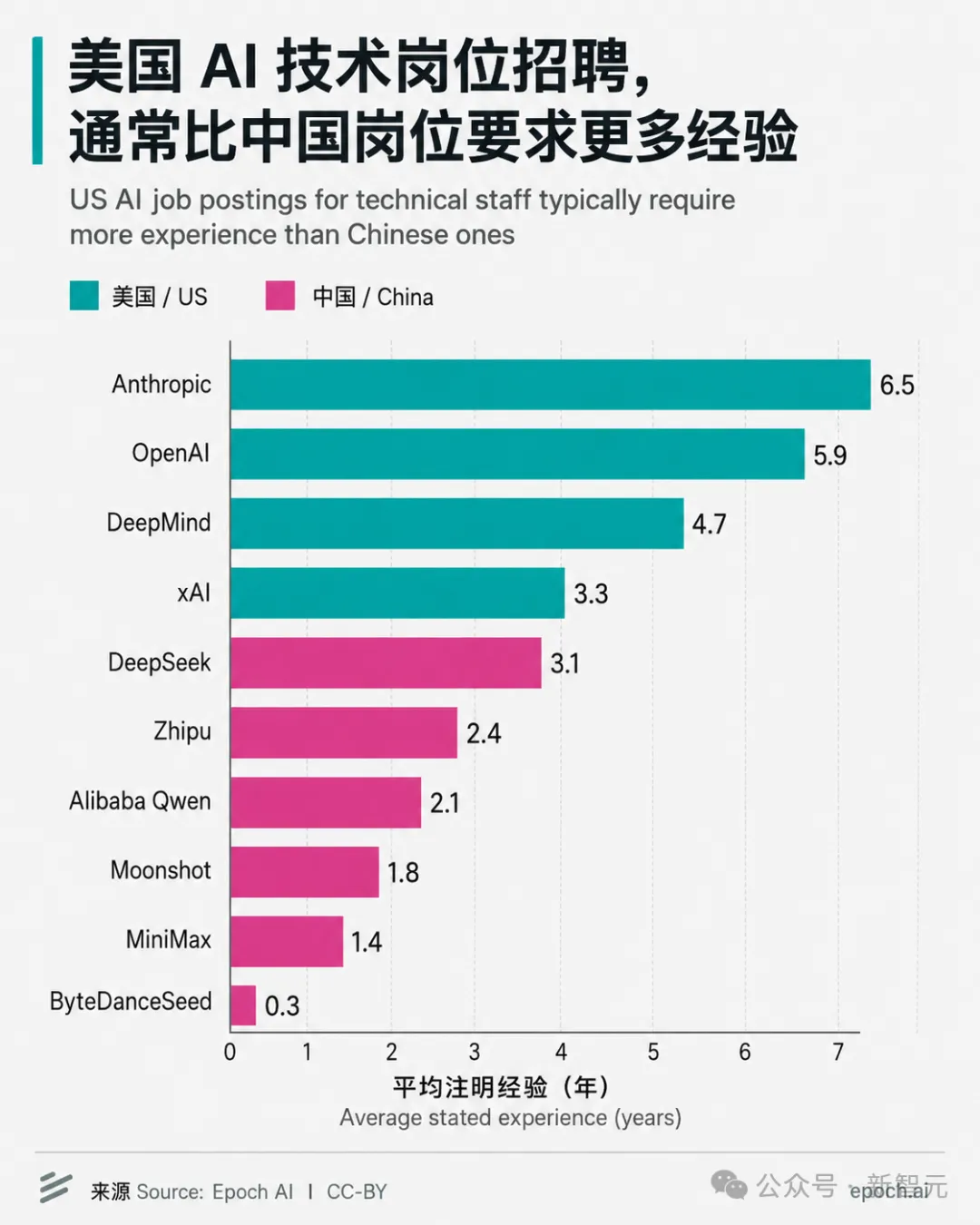
同样是进顶尖 AI 公司当工程师,在中国你只要 1.6 年经验,在美国却得熬到 5.5 年。
换句话说,一个中国应届生刚拿到毕业证,就可能坐在 DeepSeek 的工位上调大模型;而他的美国同行还得在别的公司再「实习」四年,才够格投一份前沿 AI 实验室的简历。
这是 Epoch AI 刚调查完 1604 份中国 AI 招聘启事得出的结论。
很多人想搞懂 DeepSeek、阿里、字节这些中国 AI 公司到底在干什么,通常只有两招:啃它们的技术论文,或者刷新闻、追小道消息。
Epoch AI 这次用了一招——直接去扒他们的招聘启事。
逻辑很简单:公司要招什么人,就暴露了它想造什么、卡在哪里。你不用看它说了什么,看它把钱砸在哪就够了。
于是他们把 DeepSeek、MiniMax、月之暗面、Z.ai(智谱)、字节、阿里六家最值得关注的公司、超过 1600 个岗位全捞了出来。
经验门槛:不看资历看脑子
美国前沿 AI 实验室招人,平均要求 5.5 年从业经验;中国只要 1.6 年。
这不是中国公司不挑人,而是它们压根不靠资历挑人。
DeepSeek 创始人梁文锋有句话很直接:「做长期的事,经验没那么重要,基础能力、创造力和热情更重要。」
DeepSeek核心技术岗,大多数是应届生或者工作一两年的年轻人。
结果呢?这帮「没经验」的年轻人学术积累一点不虚。
最经典的案例就是多头潜在注意力机制(MLA),直接出自一个年轻研究员的个人兴趣,公司围绕这个想法建了团队、砸了几个月算力,最终搞出了让 DeepSeek-V3 训练成本暴降的核心架构。
而就在昨天,DeepSeek 放出了一份招聘公告。用人理念写得极其直白:「让新人直接承担最核心、最重要的任务。」
字节也没闲着,专门搞了个「Top Seed」计划,不限专业背景,只看研究潜力,目标是找到「大模型领域前 5% 的人才,做 95% 的人做不到的事」。
2026 年校招季,字节 5000 多个岗位中 90% 和 AI 相关,研发岗同比增长 23%。校园岗位占到中国实验室在招工程岗的近 20%。
在美国搞前沿 AI,去哪儿?
湾区,没别的选择——约 85% 的岗位扎堆在旧金山一地。你不在旧金山,你就不在 AI 的主牌桌上。
中国呢?也集中,但分散得多。
北京、杭州、上海三个中心,吃下了 93% 标注地点的岗位,其中北京一城占 63%。
Epoch AI 的数据截至 2026 年 6 月 23 日,他们用一种很聪明的算法来避免重复计数:一个岗位如果标了三个城市,就把 1/3 分给每个城市。
为什么中国没像湾区那样「一城独大」?
两个原因。第一,各省卷得厉害。
地方政府拿补贴扶持本地公司,争自己的「省冠军」——北京有字节,我就要扶持杭州的DeepSeek、上海的 MiniMax,自然冒出更多中心。
第二,清华、北大、浙大、上交这些顶尖高校源源不断往外送人,公司干脆把总部扎在人才旁边,招人成本更低、响应更快。
这种「多中心」的格局,也让中国 AI 人才的流动性更高。
你在北京干两年觉得卷不动了,跳槽去杭州也是无缝衔接——不像美国,你想离开旧金山搞前沿 AI,选项基本为零。
一个深耕甲方,一个征服老外
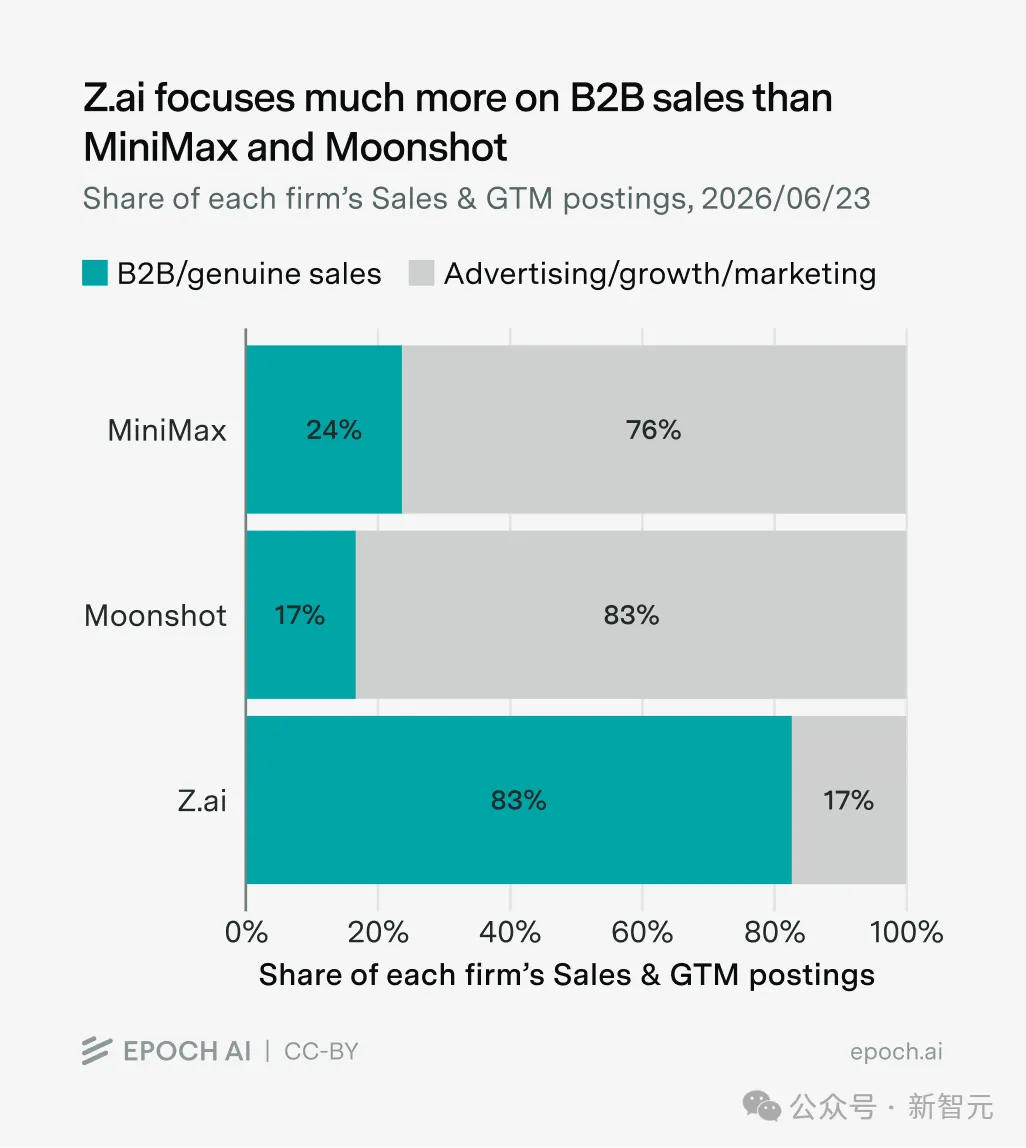
Anthropic 明显比 OpenAI 更偏 2B。这套差异,在中国初创身上也成立。
数字不说谎。
Z.ai 的市场岗多数是 B2B 销售,瞄准的是政府机构、能源国企、金融机构这些大客户,2025 年大部分收入来自在客户的基础设施上跑模型。
Z.ai 的招聘启事甚至有专门面向美国市场扩展的岗位,目标锁定财富全球 500 强企业。
MiniMax 走的是另一条路。MiniMax 的大部分收入来自 Talkie、海螺 AI 这类面向个人的 AI 原生产品。
它的市场岗主力是营销,不是销售——因为 C 端产品靠的是让用户自己来,而不是一个个去谈。