GPT-5.6实测来了:精准狙击Mythos量子位
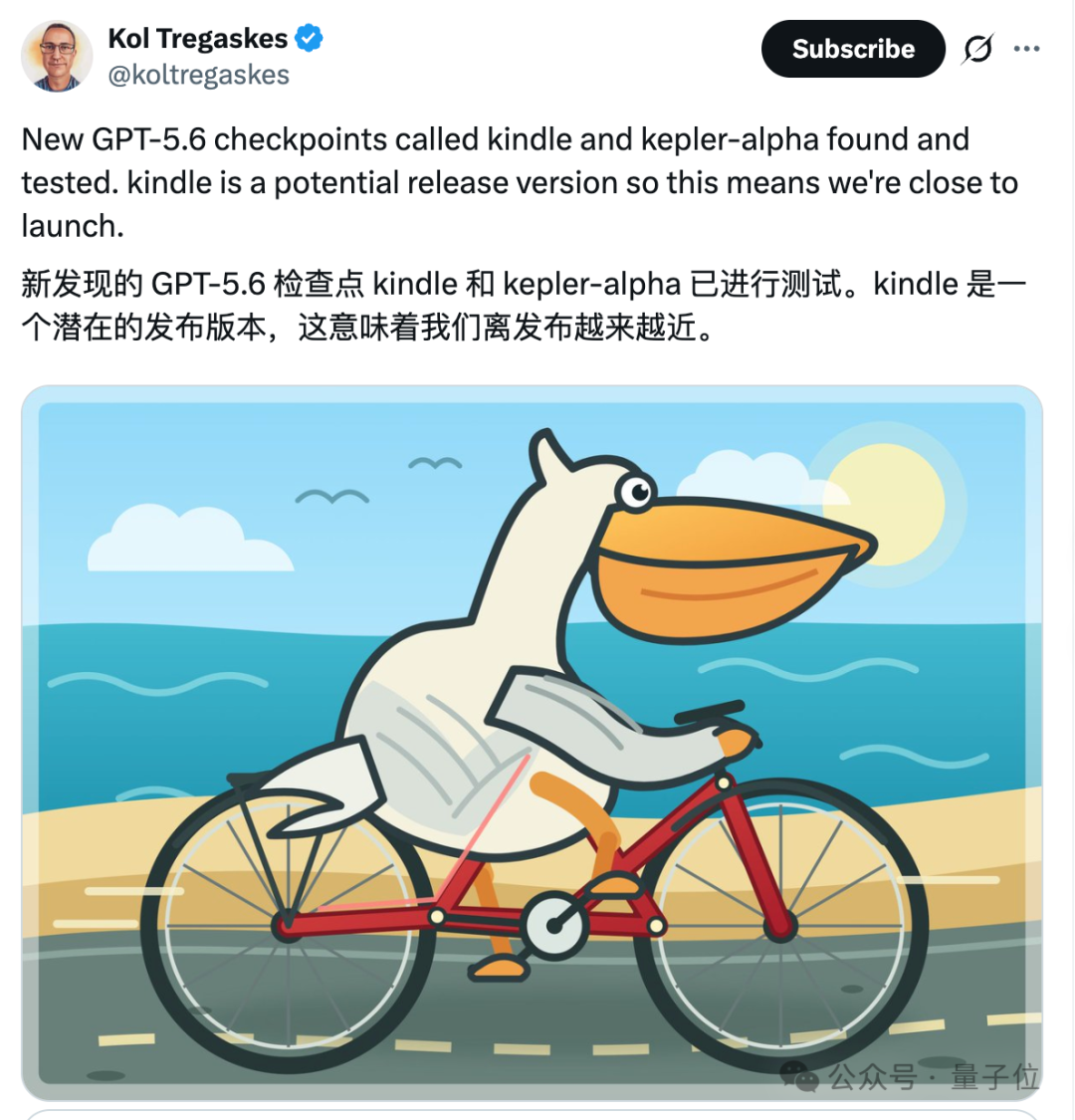
刚刚,Anthropic 放出藏了俩月的大杀器 ——Claude Fable 5 和 Mythos 5,无异于扔下一枚炸弹,现在压力直接给到 OpenAI。同一时间,GPT-5.6 也泄露了。上周开始,OpenAI 已测试内部代号为 kepler 和 kindle 的两个新检查点,kindle-alpha 被曝已选为发布候选。
GPT-5.6 的内部测试版本,开始在海外开发者和泄露圈里被疯狂实测,代号、候选版本、跑分体感,全被翻了出来。
无论是争抢 IPO,还是旗舰模型撞车,两家 “你递表我也递表”“你发新模型我也发新模型”,纯纯是打得不可开交。但问题是,GPT-5.6 真的能打过 Mythos 吗??
GPT-5.6 浮出水面
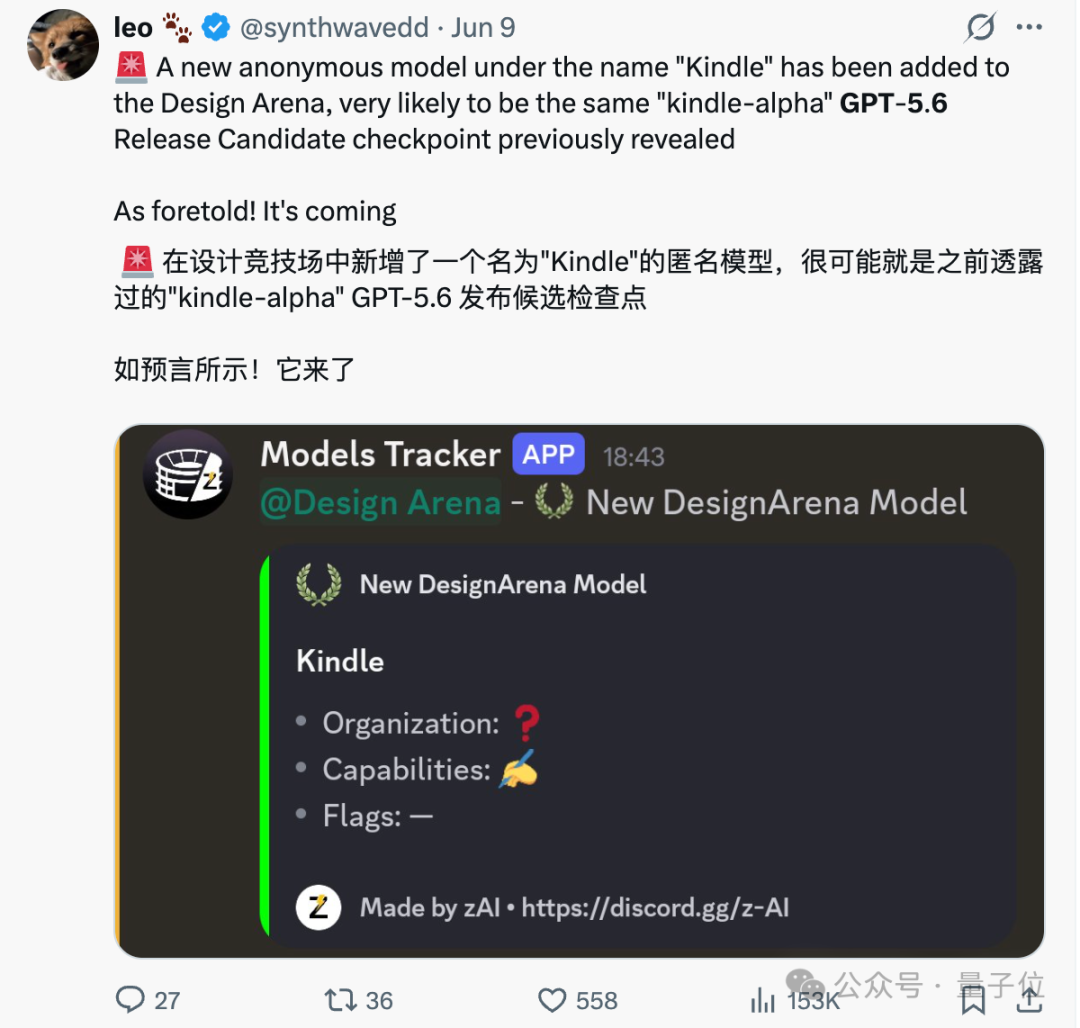
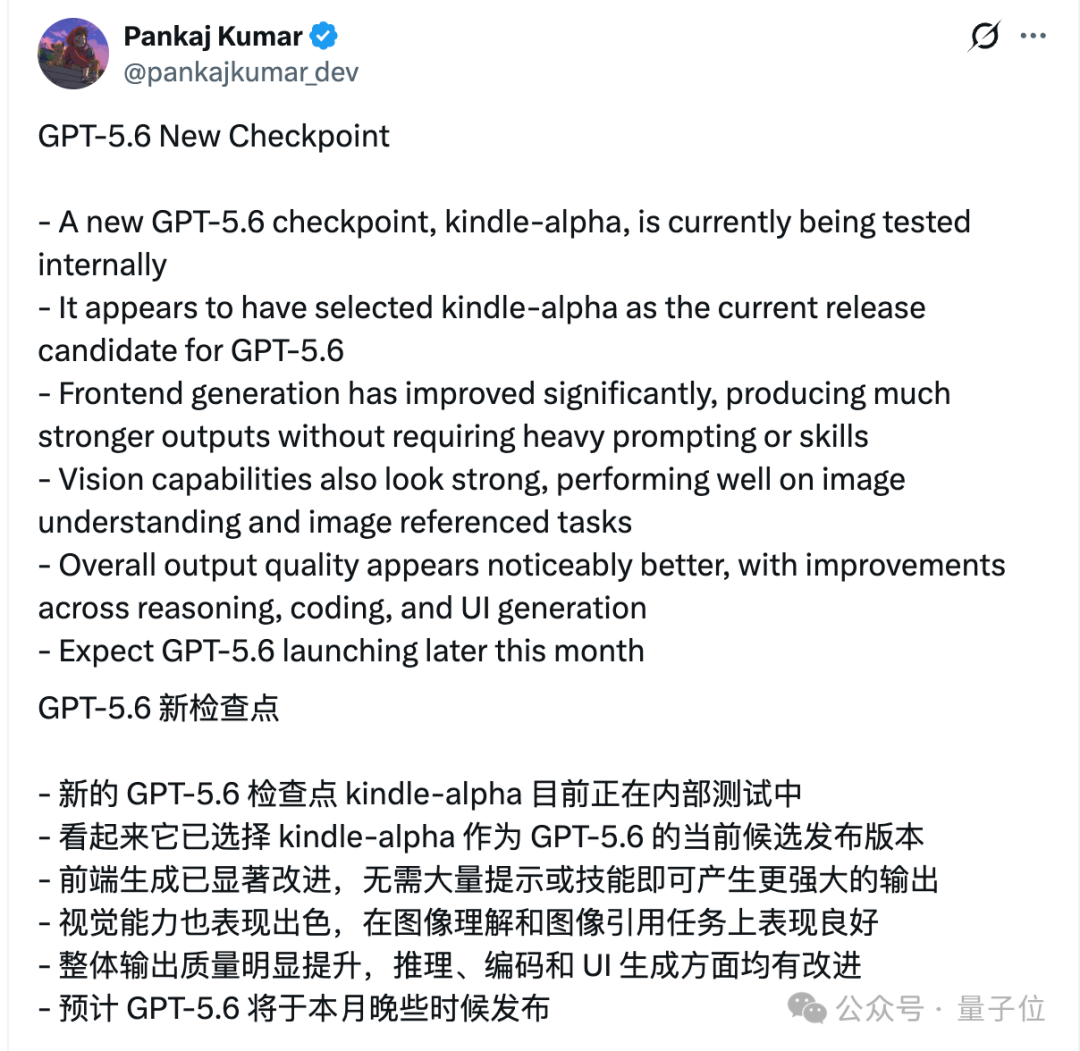
截至目前,OpenAI 对 GPT-5.6 还是零官宣,尚未正式发布。不过,海外不少网友已经对还没公开的 “内部检查点” 做了探针测试。所谓检查点(checkpoint),就是模型在训练过程中某个时间点存下的一份参数快照。OpenAI 内部会存很多份,横向比较,再从里面挑一个认为 “够好、可以拿去发” 的版本,这个版本就叫发布候选版(RC)。从上周开始,OpenAI 内部正在测两个新检查点,代号分别是 kindle 和 kepler,其中 kindle-alpha 被选为发布候选版。
从流出的体感来看,GPT-5.6 这次最被反复提及的升级,是前端 / UI 生成。网友 Pankaj Kumar 的说法是,kindle-alpha 的前端生成能力大幅提升,不需要复杂的提示词或额外技巧,就能直接产出更强的界面输出。
此外,它的视觉能力也很能打,在图像理解和图像引用类任务上表现不错,整体在推理、编码、UI 生成上都有明显改善。这是网友 Chris 实测 kindle 的效果,使用 medium 档位:
而这是另一位网友此前在非推理版本 Joule 上实测的效果:
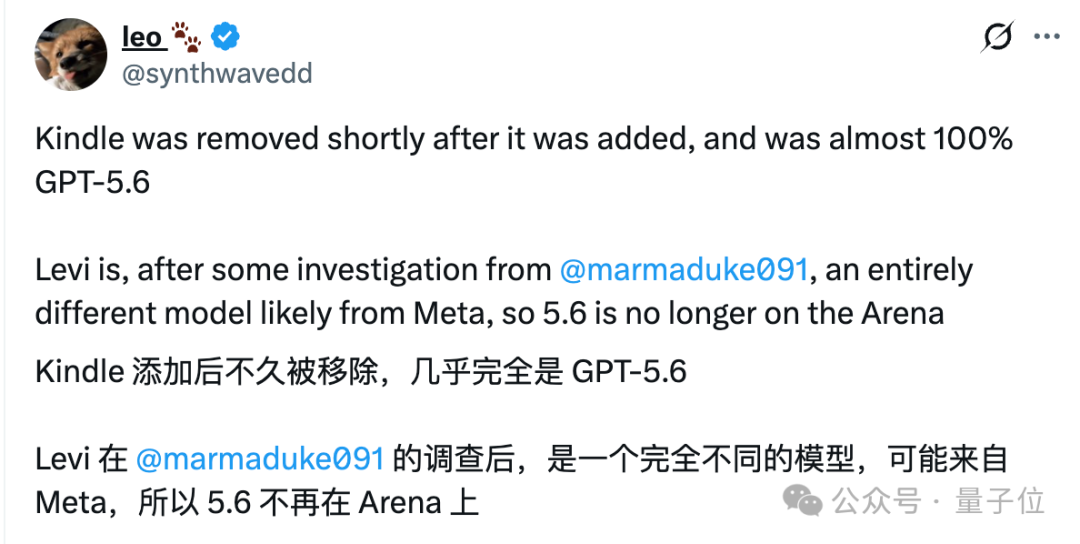
可以看出前者精美很多。但网友 Leo 拿同一个 prompt、在 xhigh 档位上分别实测了 kepler 和 kindle 两个版本,发现 kindle 比起 kepler,反而还退步了。
嗯… 这效果确实很难评。他甚至判断,OpenAI 很可能还会继续打磨,不排除最后弃用 kindle 这个候选版。
最新消息是,kindle 已被移出 Arena,出现了一个新模型 Levi。有网友猜测 Levi 也可能是 GPT-5.6 内部版本的一个代号,并对比了它和 GPT-5.5 的前端能力:
可以看出 Levi 的前端也挺能打的,风格清爽简约,富有高级感,细节处理也很到位。不过有网友调查后发现,Levi 可能来自 Meta,而非 GPT-5.6。
那么,GPT-5.6 究竟能打过 Mythos 吗?网友 mark_k 声称,GPT-5.6 “在多个 agentic coding 基准上击败 Mythos”。
但目前来看,更有说服力的是前面展示的网友 Leo 的实测。他认为 GPT-5.6 的情况不容乐观:kindle 相比 kepler 是退步,以它目前的形态,会被 Mythos 轻松击败。
6 月,上演御三家「速度与激情」
6 月,夏天来了,大模型圈也是火热起来了。海外 AI 御三家的模型发布时间全撞在了一起:Fable 5、Gemini 3.5 Pro、GPT-5.6,上演了一出 “生死时速”,而且打的是同一批能力 —— 推理、智能体、编码、前端生成。有意思的是,三家虽然都把节点压在 6 月,但到现在真正把卷子交上来的,只有 A 社一家。
Gemini 3.5 Pro 在 5 月 19 日的谷歌 I/O 大会上亮相,主打 200 万 token 上下文和 Deep Think 推理,但还未正式上线,官方定于 6 月正式可用。GPT-5.6,消息传出是本月晚些时候发布。
这也给 OpenAI 的处境添了一层张力:对手已经把分数贴出来了,内部可能还在为该交哪一版 RC 纠结。但除了跑分,定价也是一个重要因素。
Fable 5 和 Mythos 5 统一定价为每百万输入 Token10 美元、每百万输出 Token50 美元,约为现有 Opus 的两倍。如果 GPT-5.6 在能力上和 Mythos 打平甚至略输,但价格便宜得多,那它在真实采用率上还是有可能扳回一城的~
目前,OpenAI 还未有任何官方公告,真正的对决要等 GPT-5.6 正式版和 Fable 正面跑分那一刻 —— 这个月内大概率见分晓,敬请期待吧~