图灵奖得主评AI:好的不新颖,新颖的不好新智元
强化学习之父、图灵奖得主Richard Sutton一针见血:今天的AI,好的部分全是老套路,新颖的部分全是废话。
学术圈最毒的评价之一是:
这项工作既有新意,又很好。
可惜的是,好的部分不新颖,新颖的部分不好。
但强化学习领域的奠基人之一、《强化学习》教科书的作者、图灵奖获得者Richard Sutton,把这个笑话对准了整个生成式AI。
他说:这个评价,适用于今天我们所熟悉的大部分AI。
AI:好的部分不新颖,新颖的部分不好
Sutton的核心论断极其简洁,简洁到残忍。
生成式AI本质上是监督学习。
监督学习的逻辑是:给模型看大量人类创造的样本,让它学会模仿。
模仿得越像,分数越高。
当模型严格按训练数据生成内容时,输出质量很高,因为它在复现人类已经验证过的好东西。但这不新颖。它只是在用不同的排列组合,重新包装人类已经知道的事。
当模型试图偏离训练数据、生成真正新颖的内容时,质量就崩了。因为它没有任何内部机制来判断「这个新东西到底好不好」。它只会生成,不会评估。
这就是那个结构性矛盾:
新颖性和质量,在纯监督学习的框架下,是跷跷板的两端。
你按下一头,另一头就翘起来。
不是工程问题。不是靠堆数据、扩大模型、加更多GPU就能解决的。
Sutton用了一个极其刺眼的类比:「幻觉」——大模型最被人诟病的毛病——本质上就是模型试图「新颖」的副产品。
我们讨厌幻觉,恰恰证明了一件事:我们其实根本不要新颖性。我们只要高质量的模仿。
「好的不新颖,新颖的不好。」
那个笑话里审稿人的毒评,竟然精准描述了整个生成式AI的内在局限。
真正的「发现」,需要三件套
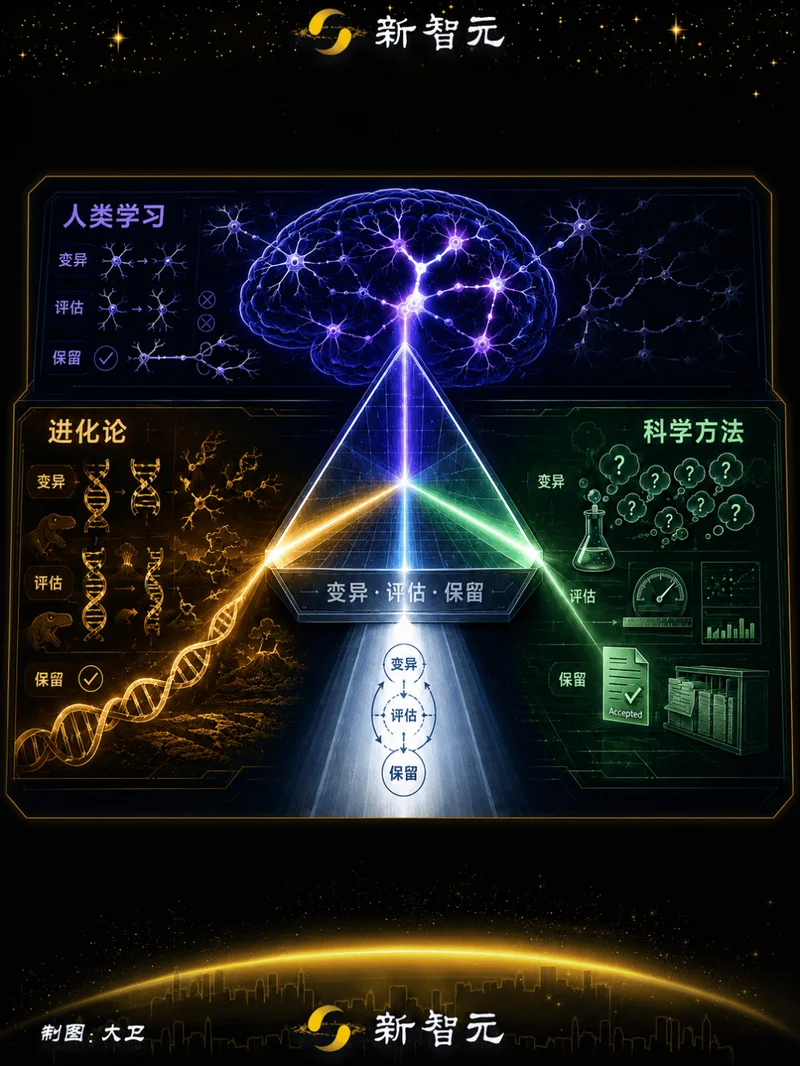
Sutton从第一性原理出发,拆解了创造力的「三位一体公式」:
真正的发现(Discovery)=变异(Variation)+评估(Evaluation)+选择性保留(Retention)。
任何真正的创造力与发现,都需要三个步骤,缺一不可:
1. 变异(Variation)产生多样化的可能性。可以是随机的,可以是基于已有知识的,但必须有真正的不确定性——否则不叫探索,叫查表。
3. 选择性保留(Selective Retention)把有价值的变异留下来,让它影响未来的行动和学习。
这三个步骤,不是Sutton的发明。它是自然选择的逻辑,是科学方法的逻辑,是人类学习的逻辑。
进化论:随机基因突变(变异)→环境筛选(评估)→适者生存(选择性保留)。
科学方法:提出假说(变异)→实验验证(评估)→发表论文(选择性保留)。
人类学习:尝试不同解法(变异)→检验对错(评估)→记住有效的方法(选择性保留)。
现在,生成式AI只完成了三位一体的第一步:几乎没有评估,更不要提选择性保留了,
它就像一个会随机射箭的弓箭手,但眼睛是蒙着的,射完之后既不看靶子,也不根据结果调整姿势。