算力的尽头是电表?赛先生
科学家们正在探索新的算法、硬件和计算方法,以降低人工智能的能耗需求。数据中心的战略性选址以及其他提高绿色能源使用率的措施,同样至关重要。
随着近年来 AI 工具的日渐普及,其带来的环境影响也与日俱增。图片来源:JAMES FRYER / THEISPOT
科学家们正在从算法、硬件和计算方式等多个方向探索降低AI耗电量的办法。另外,数据中心的选址策略,以及如何提高绿色能源的使用比例,同样很关键。
当我(译者注:作者)在公寓里喝着咖啡,随手问了谷歌的AI Gemini一个问题时,很难想到生成一个回复会耗掉多少电。信号从路由器发出,大概先经过铜线或光纤,然后一路跑到谷歌的某个数据中心。在数据中心里面,经过一排排处理器的处理,我的问题被转换成数字,再经过数十亿次运算,才弄清楚上下文和意思。答案组织好之后,转瞬之间就又飞了回来。
数据中心好比互联网的心脏,驱动着从电子邮件到网页搜索的一切,已经运转了几十年。但随着AI生成文本、图像和视频的功能日趋普及,数据中心的耗电量也达到了前所未有的水平。据谷歌的估算,用Gemini处理一条中等长度的文本提示词,大约要花掉0.24瓦时电。
单看一次消耗的电量,确实微不足道——0.24瓦时,也就够你看九秒钟电视。但是架不住积少成多。2026年3月,OpenAI估计每周有超过9亿人在用它的ChatGPT,每天的查询量高达数十亿次。
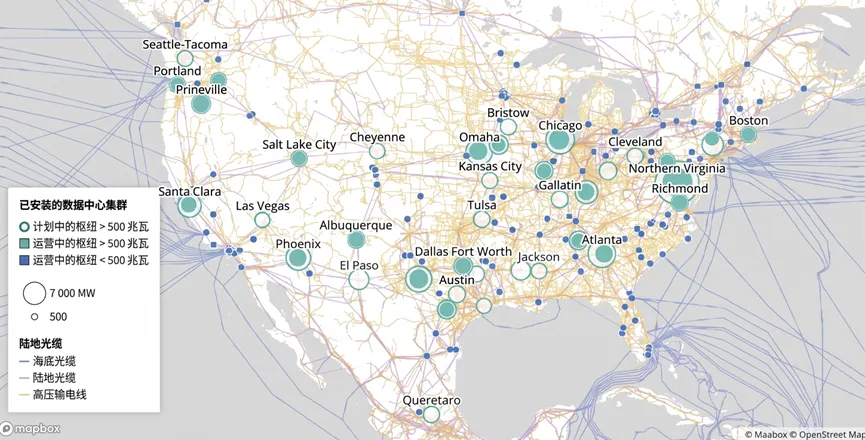
加州大学圣巴巴拉分校研究数据中心可持续性的埃里克·马萨内特(Eric Masanet)说,数据中心在全球——以及在美国(美国的数据中心数量位居全球之首)——到底用了多少电,并不是每家科技公司都会公开披露。但是,按照国际能源署最新的估算,2025年美国的数据中心吞掉了大约224太瓦时的电量,占了全美用电量的5%以上。相比2018年数据中心用电占比估计只有1.9%,可以说是大幅攀升,那会儿生成式AI还没大规模爆发。
而这种电力消耗似乎还远远不够。为了争夺生成式AI市场的领导地位,谷歌、Meta、亚马逊、OpenAI、Anthropic、微软、甲骨文等知名科技公司都在疯狂砸钱,动辄几百亿、几千亿美元,大建AI专用数据中心。AI时代之前的数据中心,耗电量大概在100兆瓦上下(足以满足 83,000 户家庭平均用电需求)。现在新建的往往是“超大规模”的数据中心,轻轻松松吃掉1吉瓦甚至更多,大致相当于洛杉矶全市发电量的十分之一。
令马萨内特和其他专家感到警觉的是,这些新增的能源需求中有很大一部分是由化石燃料(如天然气)电厂满足的,而化石燃料的燃烧会释放大量二氧化碳,进一步加剧全球变暖。导致这种情况的一个关键原因是,数据中心常建在水电、地热、太阳能或风能等可再生能源不够丰富的地区。
对于这个问题,科技公司的常见做法是,在别处投资可再生能源,用来“抵消”自己的碳排放。但问题是,除非那些清洁能源电厂的发电量超过了数据中心的耗电量,否则这个策略说破天也只是让排放量原地踏步,做不到真正的“净零排放”。而要遏制全球变暖,净零排放才是关键。“每用化石燃料发电机发电一兆瓦,”马萨内特说,“就等于我们往后退了一步。”
这还没算上制造数据中心里那些硬件所消耗的资源,也没有考虑对周边社区的影响。住在数据中心附近的居民,常常要忍受天然气电厂的空气和噪音污染。同时,数据中心冷却还需要大量用水,使当地的水资源也面临着巨大压力。
国际能源署的一份不完全数据库显示,美国大量数据中心集中在弗吉尼亚一带。图片来源:IEA / ENERGY AND AI OBSERVATORY 2025. CC BY 4.0
预测AI的能源影响,向来是一件非常棘手的事情。毕竟AI投资的回报规模能有多大,谁也说不准。但在专家们看来,有一件事已经很清楚:节能策略已经刻不容缓。2025年的一项估算显示,如果任其发展,美国数据中心每年的二氧化碳排放量很快会达到2400万到4400万吨,后者与挪威全国一年的排放量相当。
因此,计算机科学家和工程师们正在重新审视 AI 背后的那些能耗巨大的硬件和软件。他们一边研发更省电的算法和处理器设计,一边认真考虑数据中心的选址和建造方式。
“AI的高能耗不是偶然的,说到底,它是我们构建系统的方式决定了的,”康奈尔大学能源系统专家尤峰崎(Fengqi You)说道。但他也指出,如果能搭配运用好各种解决方案,“我们是有可能扭转这个趋势的。”
能耗问题的根源
要想搞懂AI为什么这么耗电,首先得了解一下大语言模型(LLM)。LLM是聊天机器人、AI助手这类文本生成工具背后的核心——具体来说,它们大多基于谷歌大脑(Google Brain)机器学习实验室在2017年提出的一种设计。这种设计,即 Transformer 架构,能够以闪电般的速度处理文本:它同时获取每个单词,并衡量该词与其所见到的每一个其他单词之间的关系。它通过计算每个单词与文本中所有其他单词的关联强度,并在大量上下文中观察每个单词,来“学习”哪些词汇可以组合在一起。(AI图像和视频生成器用的也是类似的设计思路。)
落到计算层面,实际操作就是把单词或词片段转化成数字,然后在它们之间执行加法和乘法运算。速度能这么快的关键在于可以并行计算,而这得益于图形处理器,即 GPU。GPU 主要由英伟达(NVIDIA)制造,最初是为了在游戏中快速渲染3D画面而发明出来的。
给AI计算提供算力的芯片厂商正在努力提高芯片的能效,英伟达最新推出的AI专用芯片就是一例。图片来源:英伟达
LLM为了学会这些关系所做的初始训练,会消耗大量能源。训练的时候,每个词都要跟同一段文本里所有其他词逐一比对,所以模型的计算量——也就是能耗——会随着文本长度以平方关系增长:文本长度变两倍,计算量变四倍。考虑到大多数 LLM 是在海量的公开互联网文本上训练的,这样算下来更是天文数字。有人估算过,训练GPT-4(2023 年推出的 ChatGPT 版本),花掉了大约50到60吉瓦时的电力,足以满足旧金山三到四天的用电。
不过,让专家们更头疼的,是模型训练完成之后实际使用时——也就是推理阶段——的能耗。“训练也就一次,但推理要面对的是全球几十亿用户,”密歇根大学的AI系统专家莫沙拉夫·乔杜里(Mosharaf Chowdhury)说道。他一直在跟踪测量几个已开源的大语言模型的用电情况。
这一过程出乎意料地低效。Transformer模型每生成一个词——挑出在当前上下文中跟在前面那个词后面概率最高的那个——就得把整个查询和已经写了一半的答案重新送入模型中再运行一遍。而且它每次都要动用训练期间为了理解语言模式所需要的全部参数,这些参数动不动就是几千亿甚至几万亿个。
“只是为了多写一个词,就要做海量计算,这件事本身就很有问题,”奥地利约翰内斯·开普勒大学的AI专家君特·克兰鲍尔(Günter Klambauer)表示。
优化AI软件以节省能源
意识到这一点后,人们开始把目光投向那些专攻特定任务的小型语言模型。这些模型训练面更窄、参数更少(几千万到几亿个),计算量也比大模型少得多。在2025年联合国教科文组织发表的一篇论文中,伦敦大学学院的计算机科学家伊万娜·德罗布尼亚克(Ivana Drobnjak)和同事把Meta的语言模型Llama-3.1跟几款专门针对特定任务的小模型做了能耗对比——其中DistilBART和t5-small-xsum负责摘要,另外几款分别做翻译或问答。结果发现,在各自的任务上,这些小模型比执行同样工作的 Llama 3.1 节省了超过 90%的能耗。
于是,计算机科学家们干脆把这种任务特化的思路做进了LLM内部。所谓的“专家混合”模型,就是一个大模型里只有特定部分会针对某些任务被激活。这些部分“各自学会了处理语言中不同的模式,”德罗布尼亚克解释道。
DeepSeek R1 模型的能耗远低于其他模型,很多人认为“专家混合”就是原因之一。康奈尔科技学院的电气与计算机工程专家乌迪特·古普塔(Udit Gupta)指出,其实像Gemini 或ChatGPT这样的LLM也在把用户的查询导向更专业化的子模型。“目前有大量工作致力于评估用户查询或任务的复杂性,然后找到合适的模型来处理。”古普塔说。(谷歌发言人拉尔夫·布雷默提到,处理一条中等长度的Gemini提示词现在花0.24瓦时,能效相比2024年已经提高了33倍,但一些专家仍然怀疑,用LLM处理查询到头来还是比普通网页搜索更耗能。)
科学家们还在探索不同类型的 LLM,以摆脱克兰鲍尔所说的Transformer模型那个“平方诅咒”。
一种替代方案被称为长短期记忆(LSTM)模型。它的思路是,把用户输入的提示词和已经生成的文本临时储存成一份“摘要”,就像回想一部电影的关键情节,而不是把整部电影从头再放一遍。这样一来,每次生成新词的时候,它只需要处理摘要,不用再跑一遍此前文本中所有的词。LSTM靠这一招避免了响应查询时能耗暴涨的问题。克兰鲍尔说,处理八千字左右的文本,LSTM比Transformer类模型节省了大约一半的电力。
LSTM模型其实在20世纪90年代就已问世,但因 Transformer 训练速度更快而被暂时搁置。不过克兰鲍尔说,最近的一些进展提升了LSTM的性能,现称为xLSTM。他正与奥地利初创公司NXAI合作,继续开发和优化xLSTM,“因为我们觉得为了能效,这条路值得走。”他说。不过,德国人工智能研究中心的人工智能与商业信息学研究员沃尔夫冈·马斯(Wolfgang Maaß)也指出,大科技公司在Transformer路线上砸了这么多时间、这么多资源,如果要换赛道,成本过于高昂。“我们还得观望一下,看它是会成为主流,还是只在市场里占据一个小众定位。”
晶圆与光计算
虽然专家们说最快见效的节能手段在软件层面,但也有一些人在打AI计算芯片本身的主意,毕竟这些芯片才是真正的吃电大户。多年以来,工程师通过往单颗处理器里塞进更多算力来不断提升芯片效率,这样在协同进行 AI 计算的芯片之间传输数据就不那么费电了。而实现这一点的办法就是缩小芯片里晶体管(处理数据的微型电子开关)的尺寸。
但晶体管已经小到接近物理极限了。“我们需要想点别的办法来改进设计,”波士顿大学光子学中心的计算机架构师阿贾伊·乔希(Ajay Joshi)说道。
一种策略是让芯片变得更大。伊利诺伊大学厄巴纳-香槟分校的计算机工程师拉克什·库马尔(Rakesh Kumar)介绍说,餐盘大小的“晶圆级芯片”,集成的晶体管数量是邮票大小单颗 GPU 的近 70 倍,而通信功耗只有同类GPU的 1/143。晶圆级芯片目前由加州公司Cerebras量产,不过也有缺点,比如制造过程中更容易损坏。但靠着省电等优势,“它对很多超大规模企业和AI公司会非常有吸引力。”库马尔表示。
提高处理器效率的一种策略是将其做得更大,以容纳更多的晶体管(计算机的基本构建单元)。像加州厂商Cerebras开发的晶圆级芯片,就减少了在单个芯片之间传输信息所消耗的能量。图片来源:CEREBRAS SYSTEMS
很多科技公司走的是另一条路,即自己设计专门用于 AI 计算的处理器,来提高能效。例如亚马逊云服务(AWS)的 Trainium 2 芯片、谷歌的 Ironwood 张量处理单元(TPU)。至于英伟达,可持续发展主管乔希·帕克(Josh Parker)说,现在的 AI 专用的 GPU 跟当年给游戏用的已经不可同日而语,其设计目标就是用最高的效率运行 AI 任务。另外,其他方面的创新,像是GPU 之间互连效率的提升,也发挥了重要作用。“过去八年,英伟达 GPU 跑大语言模型任务的能效提升了 45,000倍。”他说。
工程师们还在探索其他可能的计算方式。传统的 AI 处理器通过将数字编码为 0 和 1 的二进制系统来进行计算,这是通过晶体管的开启和关闭来实现的(例如,表示数字 5 需要四个晶体管来表示编码 0101)。但晶体管能做的事情,不止是当个二进制开关、要么通电要么不通电。它还能像模拟旋钮一样,停留在不同的中间电压上,各自代表不同的数字。这样一来,完成同样的计算只需更少的晶体管,从而更省电。“人们几十年前就知道,用模拟的方式来做某些事情可以大幅提高能效,”库马尔说道。
例如,德国于利希研究中心的电气工程师保罗·马内亚(Paul Manea)和他的同事们正在开发一种名为“增益单元”的器件,里面装满了按上述方式工作的晶体管。关键是,增益单元既能存储处理查询所需的数据,又能直接计算出答案。这克服了传统计算系统的另一大能耗瓶颈——在传统设计中,数据存储和运算分别在不同的硬件上进行,数据来回传输非常耗电。
对于基于 Transformer 的 LLM 而言,这个问题尤其要命,因为每次生成一个词,它都得把查询和写了一半的答案从内存搬运到处理器上。马内亚及其同事估算,用增益单元代替传统 GPU,能把 Transformer 类 LLM 里能耗最高的部分所消耗的能量降低四个数量级。但马内亚表示,增益单元还需要进一步改进才能得到更广泛的应用。
既能存储信息又能进行计算的器件概念,是“神经形态”计算的一个核心理念。这是一个正在蓬勃发展的新兴计算机工程领域,其灵感来自人脑——要知道,人脑的能耗比计算机低了好几个数量级。另一项受大脑启发的发明是这样一种芯片,其不用连续数据流来编码信息,而是像人类神经细胞那样,用电压脉冲在系统中传播的时间来编码。让芯片的各个部分在不用的时候保持休眠状态,“就有可能压低能耗。”英国谢菲尔德大学的生物启发机器学习专家埃莱尼·瓦西拉基(Eleni Vasilaki)表示。