认知折叠:汉字的十万年与AI的一秒MOOC认知实验室
在这个信息爆炸的时代,我们每天被海量文字淹没,却鲜少思考文字本身的演化逻辑。汉字——这个世界上唯一延续四千年以上的表意文字系统——正在大语言模型时代展现出前所未有的结构性优势。
本文从认知科学的视角出发,沿着"恐惧→音乐→语言→文字→AI"的认知折叠之路,探索汉字的信息密度之美、组合智慧之妙,以及在AI终结信息癌变中的独特角色。
第一章:在寒冷的黑夜里
在慢慢寒冷、充满死亡的黑夜里,为了壮胆,有了呐喊,有了节奏
第二章:每一个汉字都是一个场景
从甲骨文的裂纹到神经网络的注意力矩阵
"明"字——日+月,两种光源的组合定义了"光明"本身。"江""河""湖""海"共享一个"水"的部首,构成一张以水为纽带的语义之网。汉字的造字逻辑,从来不是"给事物贴标签",而是"把场景装进符号"。这种"场景化"的编码方式曾被视为缺陷——批评者认为汉字多义、模糊,"苹果"既是一种水果也可以是一家公司。但在大语言模型时代,这所谓的"缺陷"忽然显露出另一种面相:它迫使AI学习"语境理解"而非"词典查找"。汉字的9.65比特信息熵,意味着每个字都携带着远多于英文字母的信息量,而这种信息量的富余,恰恰为上下文建模提供了丰富的语义线索。当模型处理一个汉字时,它面对的不是一个干瘪的符号,而是一个压缩了数千年文化记忆的场景。
从甲骨文的裂纹到神经网络的注意力矩阵,汉字走过了四千年。它以四千五百个单字为种子,以六书为规则,以场景为灵魂,构建了一个既古老又现代的认知系统。每一个汉字都是一个场景——这是先民留给我们的智慧,也是大模型时代最隐秘的馈赠。
第三章:9.65比特:语言的数学之美
冯志伟的算盘珠子与香农的数学公式
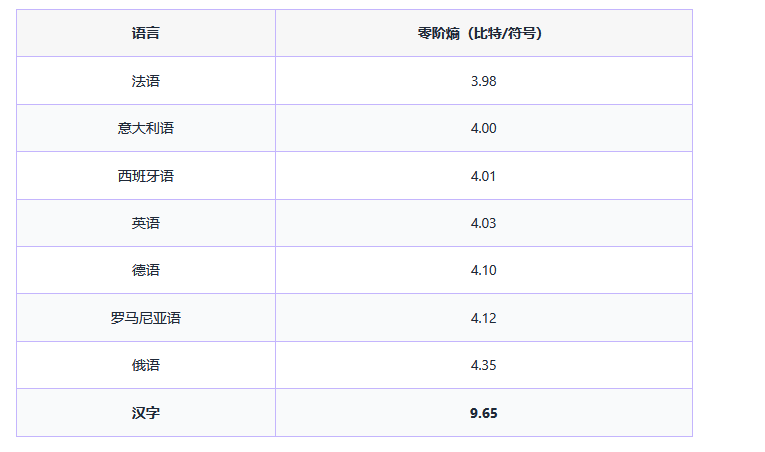
十年。整整十年,从1968年到1978年,冯志伟只做了一件事:扩大汉字的统计容量,建立六张不同规模的汉字频度表,反复验证。终于在1974年初,他得出了那个将被载入语言学史册的数字:汉字的零阶信息熵为 9.65 比特。这篇论文《汉字的熵》因为期刊普遍停刊而无处发表,直到1984年才在《文字改革》上得见天日。这是中国人第一次用自己的双手,丈量出母语的数学本质。
9.65 比特意味着什么?让我们把它放在世界语言的坐标系中审视:
第四章:组合游戏 vs 词汇膨胀