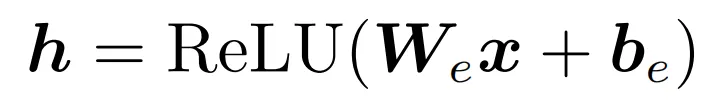大语言模型为什么能像人一样说话和思考?机器之心
我们每天都在使用大语言模型(Large Language Model,LLM)。一个明显的感受是,它们似乎真的能够理解我们的语言,虽然有时也会出现幻觉。另一方面,观察 LLM 输出的思维链,也就是其推理过程的语言表示,我们会感到它们好像真的能像人一样思考。
最近字节跳动的李航、张少华、林苑发表了一篇文章。论述:LLM 的语言和思考能力是怎样的能力?这些能力是如何通过其实现原理和方法、乃至工作机制形成的?
全文链接:https://github.com/hangli-hl/AI-Articles/tree/main
LLM 技术是人类创造出来的,其实现原理是清楚的,但其工作机制(Mechanics)仍未被充分理解。LLM 规模极其庞大,工作机制极其复杂,给对其能力的研究带来了很大困难。
ChatGPT 问世以来,已有大量关于 LLM 机制和特性的研究,特别是近年关于工作机制(或可解释性)的研究。这些工作从不同角度对这一 AI 的核心课题给出了一定程度的回答。但仍有许多问题有待今后的研究。
该文章将对 LLM 的基本原理和实现方法做了总结,也对 LLM 工作机制的研究进行简单的介绍,包括字节跳动做的 LLM 记忆机制的工作;在此基础上,对 LLM 的能力形成提出自己的看法。
引用:LLM记忆机制论文:Shaohua Zhang, Yuan Lin, Hang Li, Memory Retrieval and Consolidation in Large Language Models through Function Tokens, 2025. https://arxiv.org/abs/2510.08203
1 主要观点
文章阐述了以下主要观点。
LLM 学习到的是语言使用和推理的模式,重要的是学到了其高阶模式。 LLM 的学习属于机器学习,其学习得到的内容本质上是数据中的统计规律,或者说数据中的模式(Patterns)。语言数据内容丰富,包含了词汇、语法、语义、语用信息和世界知识。我们可以看到,LLM 不仅学习到了与词汇和语法相关的低阶模式,而且也学习到了与语义、语用和世界知识相关的高阶模式(Higher Order Patterns)。之前的语言模型往往做不到这一点,而这正是 ChatGPT 以及后续的 LLM「涌现」出来的能力。因此,认为 LLM 仅仅学到了语言的形式而没有学到内容的观点(例如后述乔姆斯基的看法)并不能令人信服。
可以用 Next Token Prediction (NTP) 来概括其基本实现原理,但整体能力是由策略、模型、算法及数据这几个要素共同决定的。 LLM 的学习和推理的过程是 NTP,但这只是表面的形式,其具体的实现方法以及其特点更为重要。预训练中使用的极大似然估计(等价于数据压缩)是估计词元序列数据的概率分布。后训练的强化学习旨在微调模型,使其成为最优词元序列生成的策略函数。作为模型的 Transformer 具有极强的语言和知识表示能力。随机梯度下降的优化算法则能帮助找到具有良好泛化性的解。LLM 的关键在于对这些技术的系统整合与规模化实现。有观点将 LLM 的成功简单归因于 NTP,这是过于简单化的理解。
LLM 的内部机制已得到一定的解析和理解。 近年 LLM 可解释性研究取得了一定进展,现在 LLM 对我们来说已不再完全是黑盒。LLM 中的特征可以通过 SAE 等工具提取出来,特征之间形成的回路也可以利用 CLT 等工具追踪。字节跳动最近的工作进一步揭示了 LLM 中特征在学习过程中被记忆、在推理中被检索的规律。随着未来研究的不断深入,LLM 的工作机制会越来越多地被我们解析和理解。
2 LLM 的工作机制
LLM 的研究可以从三个视角进行:机器学习方法与理论、外部提示实验分析、内部工作机制研究。若将 LLM 比作人脑,工作机制的研究则对应着脑科学实验。
2.1 特征叠加
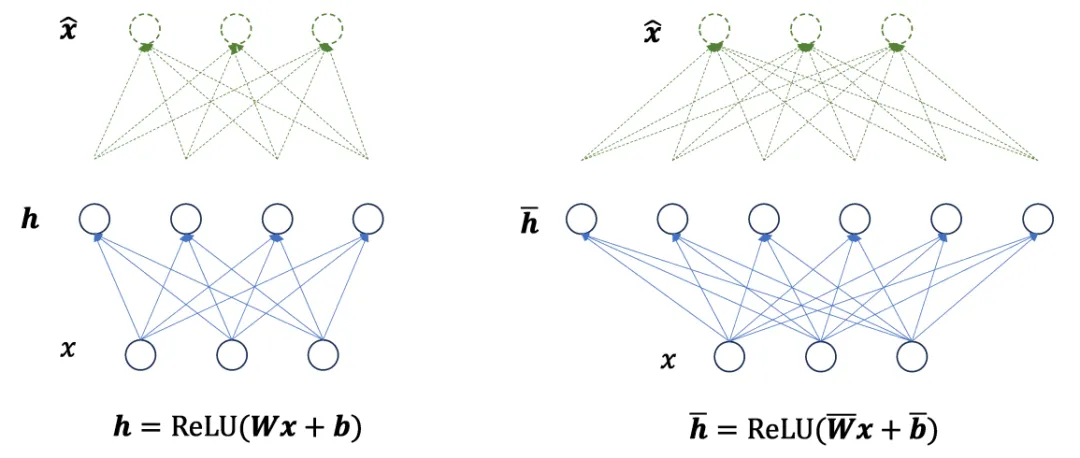
神经网络的每一层上都可能存在着「特征叠加」(Superposition)现象。传统的观点认为,一个神经元表示一个特征。然而,大量实验表明,这种理想化的情况在实际网络中比较少见。相反,神经元与特征之间往往呈现的是多对多的对应关系:即一个神经元参与表示多个特征,一个特征由多个神经元共同表示。
图 1:LLM 的语言和思考能力、工作机制、实现原理和方法之间的关系。
Anthropic 研究团队提出了特征叠加假说(Superposition Hypothesis)。其核心思想是:通过特征叠加,神经网络的一层神经元可以近似表示远大于其数量的特征,代价是特征之间存在一定程度的干扰。
神经网络的一层(称为实际层)可以表示为:
图 2:原始的前馈神经网络与近似等价的更宽的神经网络。
2.2 SAE:特征分析
稀疏自编码器(Sparse Autoencoder,SAE)可以用于分析神经网络,发现其中具有可解释性的特征。在 LLM 的可解释性研究中,通常将其应用于 Transformer 的残差流,即在每层的输出表示向量上。
SAE 与特征叠加理论形成了互补关系。特征叠加可以被视为一种压缩过程:模型隐式地通过高维且稀疏的特征向量对输入向量进行表示。而 SAE 则可以被视为一种「解压」方法:将输入向量分解为高维且稀疏的特征向量。这种「压缩—解压」的关系,使 SAE 成为研究和分析特征叠加现象的重要工具。
SAE 由编码器(Encoder)和解码器(Decoder)组成。首先,编码器通过非线性变换将输入向量转换为高维且稀疏的特征向量: