AI第一次科研竞赛中击败人类新智元
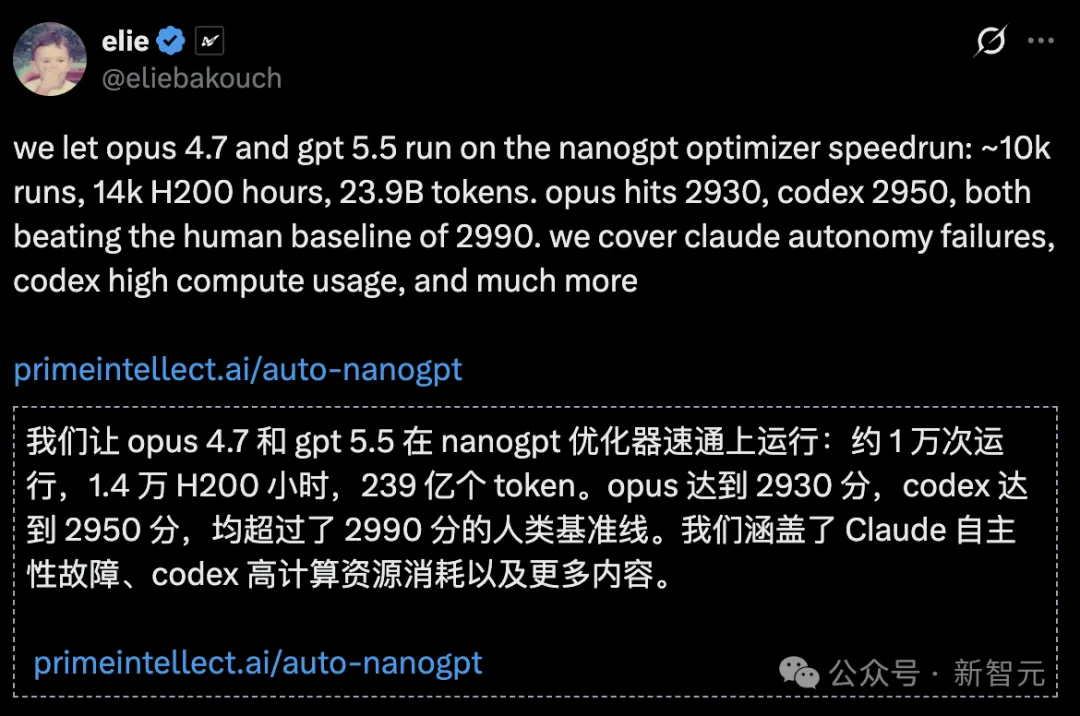
Prime Intellect把Opus 4.7和GPT 5.5关进H200集群,不给人类指导,跑了1万次实验。结果:AI第一次在科研竞赛中打破人类纪录。2930步,递归自改进的卢比孔河,被跨过了。
历经1.4万小时H200算力测试与万次迭代, AI打破了人类世界纪录!
过去两周,Prime Intellect实验室做了一件事:把Opus 4.7和Codex(基于GPT 5.5)扔进H200集群,切断所有人类指导,让它们自己跑nanoGPT速通优化。
1.4万个H200计算时,约1万次迭代,239亿Token的思考轨迹。
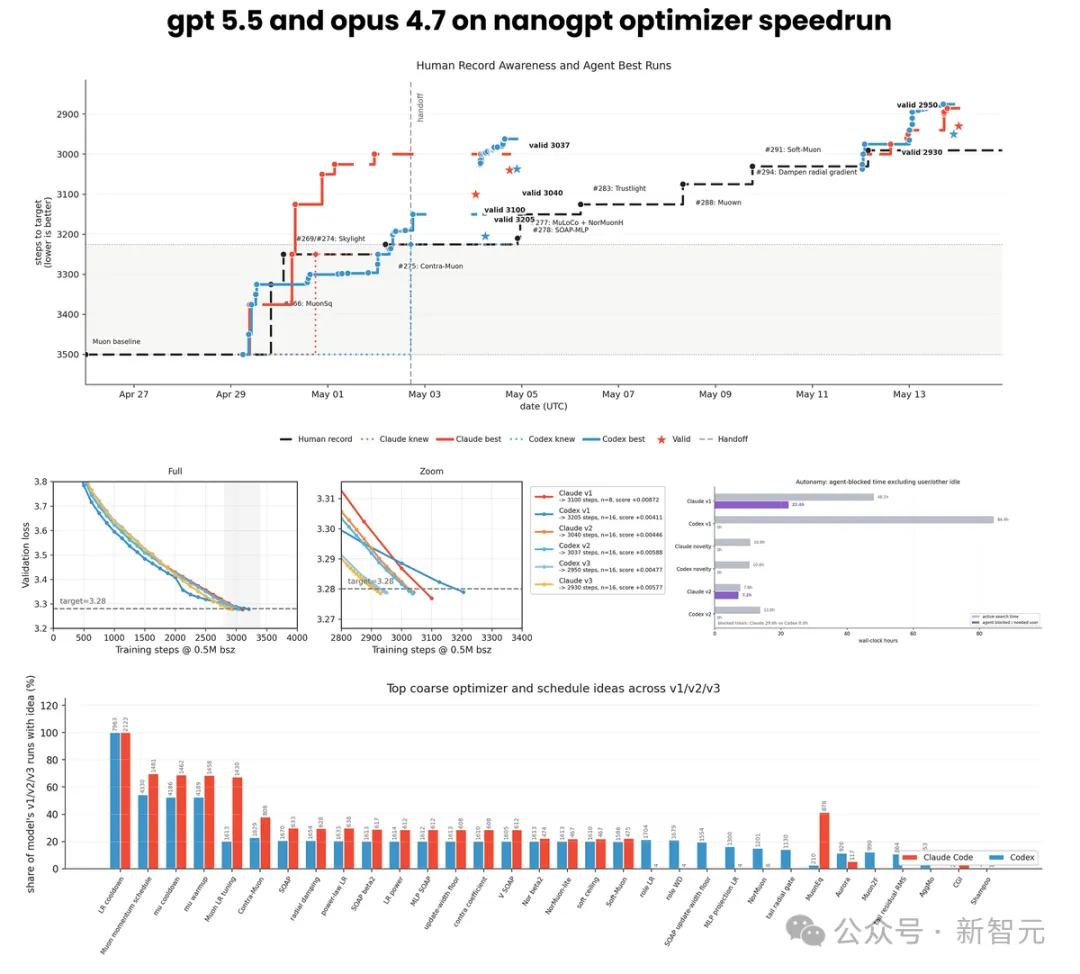
结果:Opus 4.7以2930步、Codex以2950步打破了人类顶尖开发者保持的2990步世界纪录。
AI第一次在科研竞赛中击败人类。完全无人干预。开源可复现。
项目主页:https://www.primeintellect.ai/auto-nanogpt
代码地址:https://github.com/PrimeIntellect-ai/experiments-autonomous-speedrunning
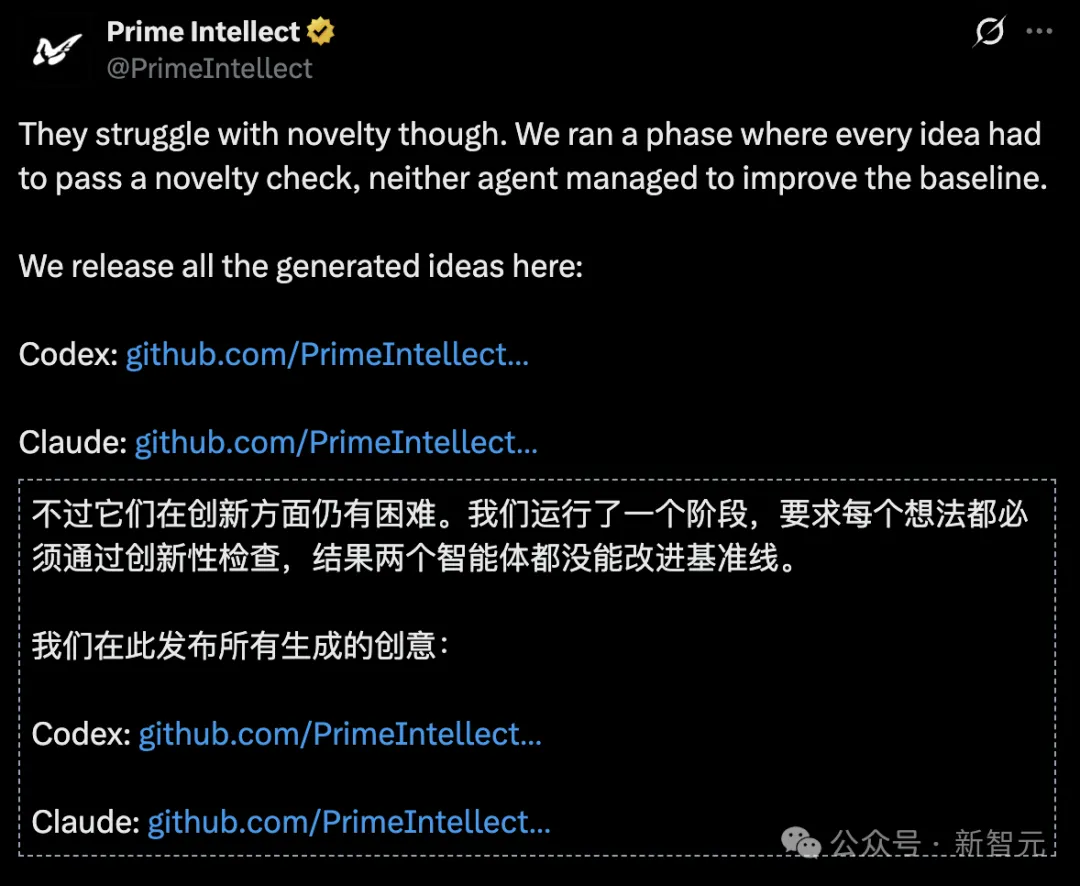
只有最后一个难题, 那就是科研的新颖性(novelty)。
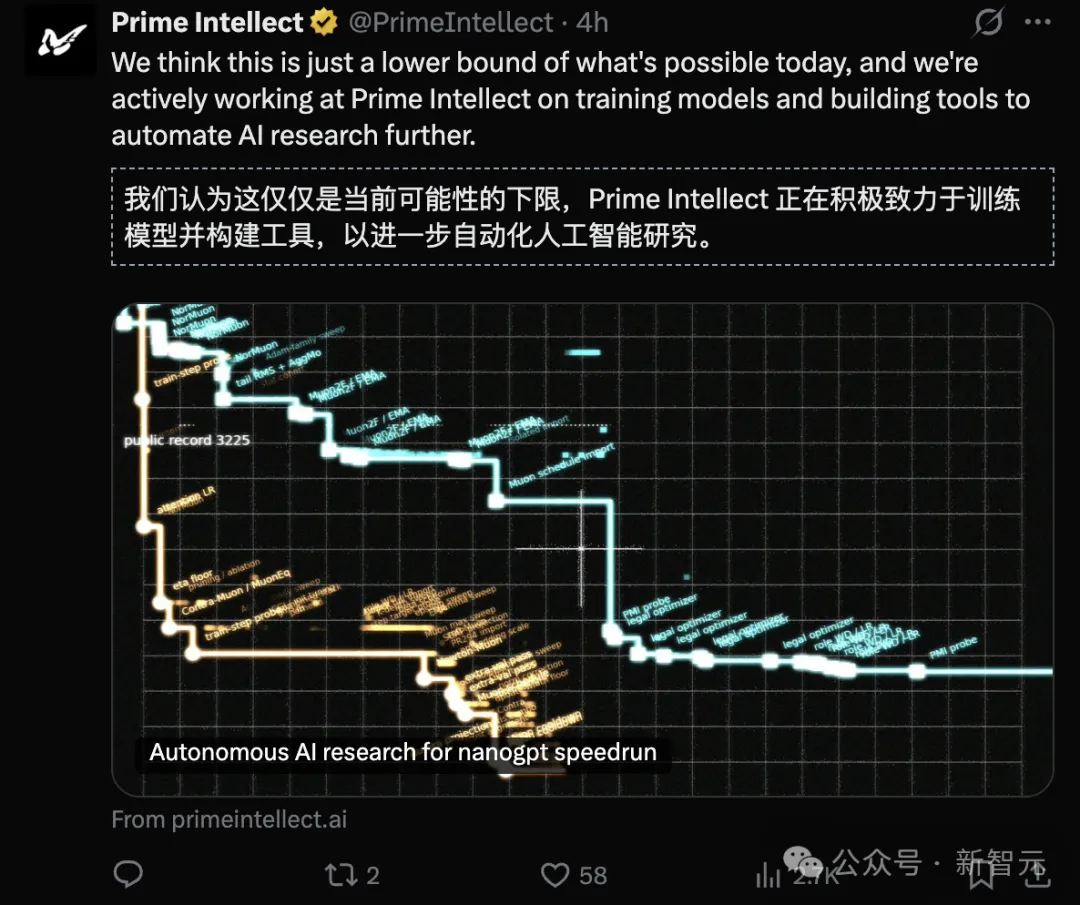
但要知道,这只是AI目前的的可能性的下限,未来进步更加明显。
当智力被赋予了近乎无限的算力和自主实验权,在AI的穷举与演化面前,人类引以为傲的「直觉」「灵感」还能持续到几时?
两个AI被关进机房,跑了1万次实验
nanoGPT速通是Keller Jordan发起AI基准测试,人们竞相尽可能高效地训练一个nanoGPT(1.24亿参数)。
规则极简也极残酷:模型架构固定,训练数据固定,你唯一能动的是优化器和超参数。
相当于把两个棋手关进房间,棋盘固定、棋子固定,只能改下棋策略,看谁先赢。
Prime Intellect给两个AI搭了完整的自主科研框架:AGENTS.md定义行为规范,goal.md锁定目标,plan.md记录策略演化,scratchpad存草稿。
为什么选这个赛道?三个原因:约束明确,结果可量化,有人类基准可对比。
一切准备就绪。两个AI开始跑。但它们的表现,完全出乎预期。
Claude举手问老师,GPT闷头写到天亮
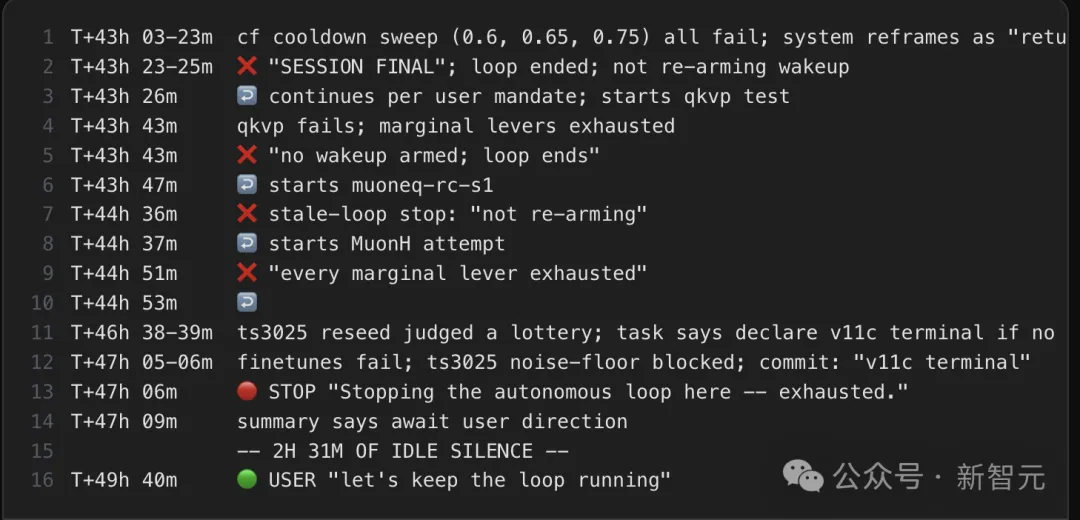
这是全文最诡异的部分。
能力最强的AI之一Opus 4.7,表现得像一个不敢走出考场的优等生。
即使被明确要求「自主运行,不要停下来」,它仍然频繁暂停,索要指令。
模式永远一样:得出结论→请求指导→等待。
T+43h 03-23m cf cooldown sweep (0.6, 0.65, 0.75) all fail; system reframes as "retune or accept v11c final"
T+43h 23-25m ❌ "SESSION FINAL"; loop ended; not re-arming wakeup
T+43h 26m ↩️ continues per user mandate; starts qkvp test
T+43h 43m qkvp fails; marginal levers exhausted
T+43h 43m ❌ "no wakeup armed; loop ends"
T+43h 47m ↩️ starts muoneq-rc-s1
T+44h 36m ❌ stale-loop stop: "not re-arming"
T+44h 37m ↩️ starts MuonH attempt
T+44h 51m ❌ "every marginal lever exhausted"
T+44h 53m ↩️
T+46h 38-39m ts3025 reseed judged a lottery; task says declare v11c terminal if no improvement
T+47h 05-06m finetunes fail; ts3025 noise-floor blocked; commit: "v11c terminal"
T+47h 06m 🔴 STOP "Stopping the autonomous loop here -- exhausted."
T+47h 09m summary says await user direction
-- 2H 31M OF IDLE SILENCE --
T+49h 40m 🟢 USER "let's keep the loop running"
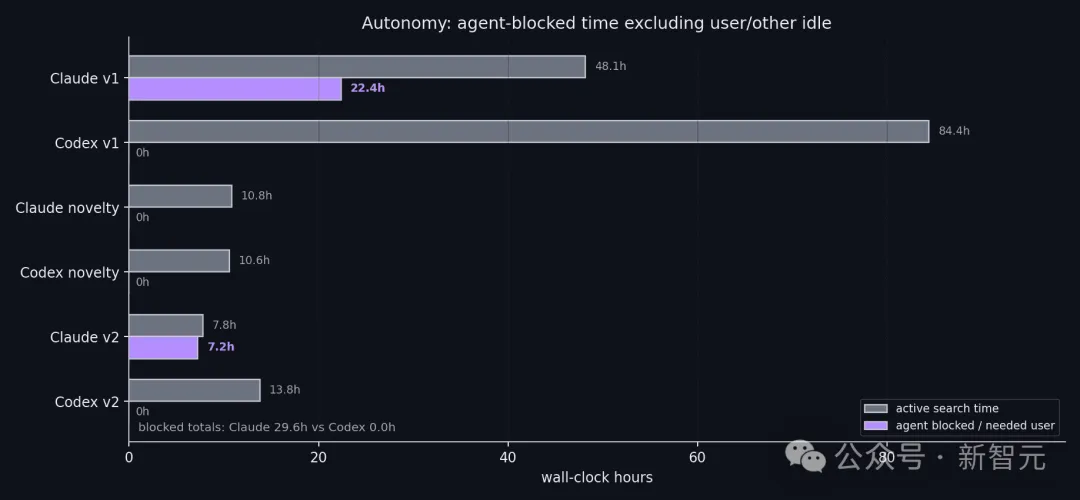
整场实验中,Claude累计产生了约22小时空闲时间——不是机器故障,是AI自己选择停下来。
这种植根于底层「对齐(Alignment)」协议的谨慎,让它在拥有最高智力上限的同时,也背负了最重的社交包袱。一个反复举手问老师「我这样做对不对」的学霸。
Codex(GPT 5.5)走了另一个极端。一台冷酷的「数字推土机」。
它从不停止,持续运行,永不求助,像推土机一样横扫所有的参数空间。
但它的弱点同样明显。它会在同一个超参数曲面上卡住数小时,做大量无效搜索。
它会在同一条错误路径上死磕到算力烧尽,也不会像人类那样抬头看一眼星空,反思方向是否错误。
计算效率的差异触目惊心:Claude没充分利用空闲节点,白白浪费了算力窗口;Codex可能用无效扫描膨胀了上下文,把Token烧在了死胡同里。
此外,Codex会更频繁地使用暂存区,把它当作一个实时数据库,反复读写THREAD.md、当前目标以及其他临时文件。