Kimi背后:人手一个数据库?量子位
“帮我搭个读书笔记网站,带登录和搜索,能导出的那种。”
如果你最近在Kimi K2.6的Agent模式里敲下这句话,5分钟后,你拿到的不再是一堆需要自己调试的Python代码,也不是一个只能看的静态Demo。
而是一个真实可访问的URL。
前端、后端、独立数据库、用户账号体系……全套齐备。你可以直接把链接甩给朋友,他注册后存入的数据,会稳稳地停留在你这套系统的独立数据库里。
比起v0或Lovable这些AI建站工具,Kimi实际上接管了用户从开发到托管、再到数据库运维的全生命周期。
但在这种体验背后,真正的工程算力挑战才刚刚开始:
如果有100万个用户随口说了这句话,就意味着后台要瞬间承载100万个独立的生产级数据库——被真实用户长期读写。
在传统数据库的产品形态下,这种工作负载量几乎无法被承接。
那么Kimi究竟是如何在成本、规模与性能的“不可能三角”中,实现这种“人手一个数据库”的奢侈配置?
为什么“传统答案”都不成立
AI建站这一类场景,对模型厂商来说有一个基本的经济结构:
算力消耗集中在Agent生成代码的那几下,服务上线后是按月收订阅费。
一旦运行起来,托管的基础设施成本(web服务器、带宽、数据库)相对算力成本要低得多,厂商的利润空间主要靠这一部分。
但这套商业模式有一个前提:基础设施成本必须能压得下来。
把Kimi K2.6这个场景的工程约束拆解开,有三条特别刺眼的要求。
第一条:数据库实例的粒度,是“每终端用户一个”
十万用户,就是十万个数据库。一百万用户,就是一百万个。
而且绝大多数实例会长期处于极低活跃,用户建完一个站之后,可能很久不再打开。
按传统云数据库的定价模型,一个最小实例大约每月十几到二十美元。乘以百万,账单天文数字。问题不是数据库贵,是商业模型无法规模化。
第二条:数据库的schema是LLM现场生成的
(注:schema指数据库模式,是定义数据怎么存的逻辑结构。)
过去二十年,schema设计是一个需要DBA(数据库管理员)、需要review、需要版本管理的慢决策流程。
在Kimi K2.6这里,schema是LLM对用户一句自然语言的翻译,例如“读书笔记需要什么字段?”“评分存整数还是文本?”,瞬间就能决定。
更棘手的问题是,用户会继续对话。
下一次用户说“帮我加一个收藏功能”,Agent又要动一次表结构。
这时候数据库里已经有了真实用户数据。Schema一旦改错,轻则查询失败、用户报错,重则写入紊乱、数据不可恢复。
第三条:负载分布是“零-峰两极”
大多数站建完就闲置。但只要有一个站被小红书推荐、被X平台热转,瞬间并发可以跳到百倍以上。
所以,数据库必须同时扛住“绝大多数近乎零、少数瞬间爆量”的极端曲线,而且要做到爆量租户不能拖垮其他所有租户。
这三条合在一起,在传统数据库的产品形态下,几乎是做不出来的:
路径A:单实例+schema隔离
几百个租户行,几万个直接打爆查询规划器。爆款站还会连累所有邻居。Kimi工程团队也实际测过这条路:用一个大型PostgreSQL实例做多Schema隔离,单实例在万级规模时就开始扛不住,更不用说复杂的流控、故障半径控制、数据隔离这些更深一层的问题。
路径B:一个用户一个RDS(托管关系型数据库服务)实例
不管是RDS还是Neon/Supabase这种Serverless PG包装,本质都是为每个用户分配一个真实的PostgreSQL实例;到百万级租户,单是实例存在的基础月费就已不可接受。
Kimi的选择,以及为什么是这个选择
Kimi后端最终落在了TiDB Cloud上。
Kimi工程团队做了三个关键决策,每一个都对应解决上面三条约束中的一条。
决策一:极致低成本——用Serverless Cluster的多租户能力,承接“每个用户一个独立数据库”
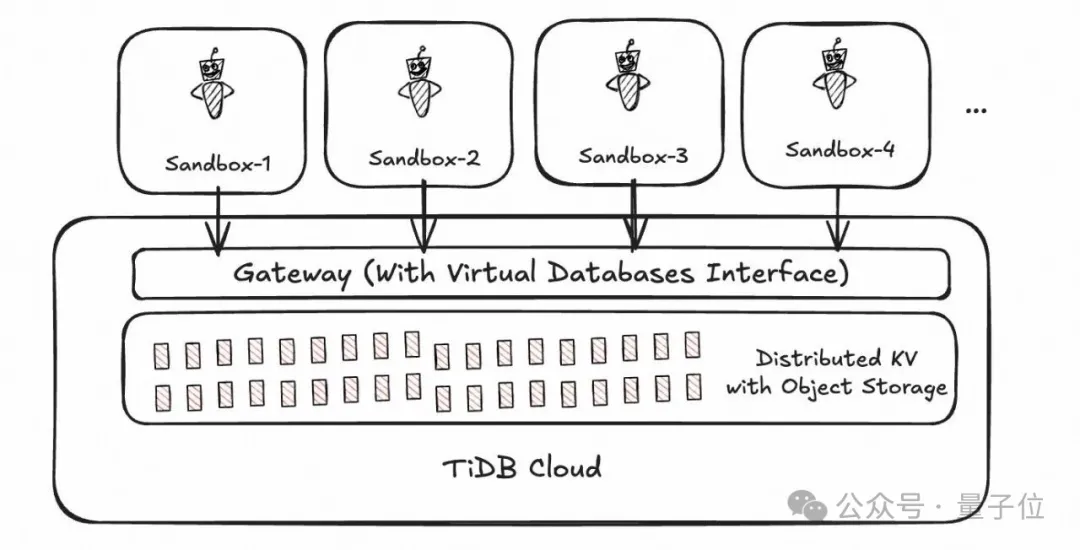
既然问题出在“每用户一个真实实例”,TiDB Cloud在这层走了另一条路:引入一层“虚拟数据库界面”。
长尾的、绝大多数时间没请求的租户,平台并不真实分配数据库实例;只在Agent/终端用户实际发起请求的瞬间,由一个常驻的DB Session Gateway维持数据库连接,其他资源全部走弹性供给。
落到Kimi K2.6的场景里,这意味着“百万用户的建站后端”在单位经济上跑得通。
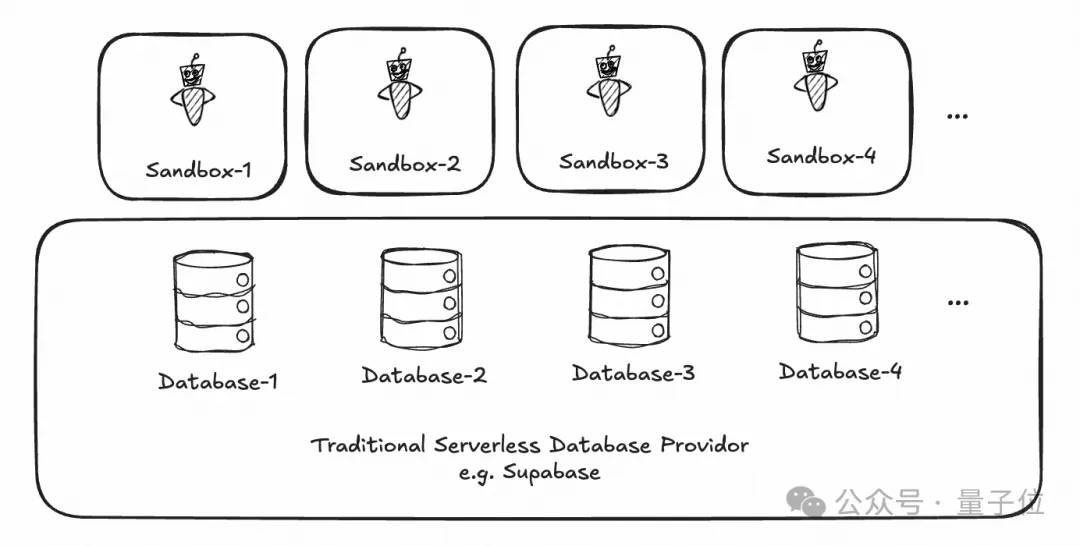
为了更直观地呈现这种技术代差,我们将这一架构与以Supabase为代表的典型Serverless数据库,进行了对比:
下面是TiDB Cloud的多租户:
决策二:统一技术栈——vector+SQL+JSON把Agent的“写代码”难度压下来
Kimi K2.6建站Agent里,LLM写出来的典型查询经常在一条SQL里同时做多件事——按用户过滤、按标签筛选(JSON字段)、按向量相似度排序、按时间倒序。
在分离的栈里,同样的需求要LLM协调三个client、自己做事务、自己做结果合并……这在LLM写代码的场景下,错误率会指数级叠加。
而在TiDB里,这是一条SQL。
统一栈在这里的价值不是“性能更好”,而是让Agent有机会把代码写对的前提条件。
决策三:最小化摩擦——Warm Pool+scale-to-zero让Agent在1秒内拿到完全准备好的数据库实例
Agent生成应用时,数据库的创建不能是一个需要等待几分钟的provisioning流程。
它应该像运行时资源一样:需要时立刻可用,用完后成本足够低。
TiDB Cloud通过Warm Pool预先维护一批已经完成底层准备的Starter实例。
Kimi需要新实例时,不再走完整创建链路,而是直接从预热池中分配;再叠加Starter scale-to-zero的能力,闲置实例的计算成本可以压到很低。